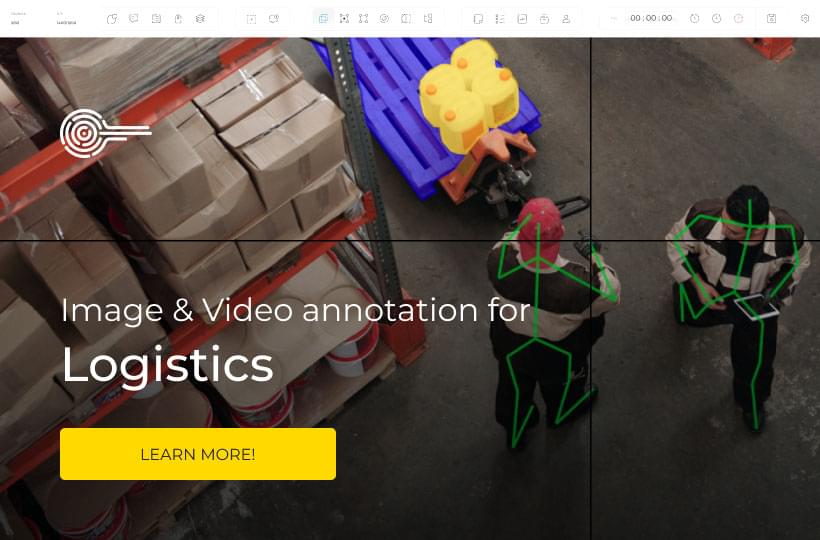
Exploring Object Recognition Technology: A Beginner's Guide
Did you know object recognition technology is transforming the digital sphere? It's found in everything from autonomous vehicles to cutting-edge security systems. This technology alters how we engage with our environment. Whether you're an aficionado or a novice, knowing about object recognition is crucial in our connected world.
Key Takeaways:
- Object recognition technology is vital across the automotive, manufacturing, and security sectors.
- Object detection serves as a critical part of this tech, pinpointing the exact location of objects.
- In object detection, we talk about bounding boxes, classification, localization, and intersection over union (IOU).
- For those interested in working with object recognition, tools like TensorFlow, PyTorch, and OpenCV are quite popular.

Understanding Object Detection
Object detection is central to object recognition technology in computer vision. It's about finding and labeling objects in images or videos. This task is vital for understanding the spatial details of visual content.
Unlike image classification, which pinpoints what's in an image, object detection locates and identifies objects. It's key for counting, tracking movements, and enhancing digital interactions. Think of it as recognizing and knowing where items are in a scene.
Object detection uses powerful algorithms and deep learning to spot specific objects. This capability supports automatic processes and deeper insights from visual information. Its uses are broad, seen in self-driving cars, surveillance, and enhancing augmented reality experiences.
Advantages of Object Detection in Computer Vision
Object detection offers key benefits in computer vision:
- Accurate Localization: It provides exact locations of objects with bounding box coordinates. This is critical for precise spatial analysis.
- Multi-Object Recognition: It can find and classify multiple items in complex scenes. This helps in detailed analysis.
- Real-time Interaction: Object detection's spatial insights allow for quick digital interactions. This includes things like recognizing gestures.
- Improved Contextual Understanding: By understanding the spatial relations between objects, it deepens our grasp of visual data.
Through its ability to locate and classify objects, object detection lays the groundwork for advanced computer vision. It's instrumental in making systems that can understand and interact with visual content intelligently. This capability is essential for developing future applications in various fields.
Key Concepts in Object Detection
To fully comprehend object detection, one must grasp its fundamental concepts. This area in computer vision addresses the detection of objects within images and videos. It combines localization and classification to accurately pinpoint and categorize objects.
Localization aims to pinpoint where objects are within an image. It's achieved by drawing bounding boxes around the objects. These boxes define the object's position, aiding in further examination and interaction.
Classification identifies the kind of object present. It involves tagging objects based on their features. It plays a crucial role in determining the nature of objects, enabling deeper analysis and decision-making processes.
After localizing and classifying objects, the accuracy of this process is crucial. The Intersection over Union (IOU) metric is essential for this. It gauges how well the detected object aligns with the actual object by measuring their bounding box overlap.
These essential components lay the foundation for reliable object recognition systems. By uniting the notions of bounding boxes, classification, localization, and IOU, detection algorithms can accurately identify objects across various scenarios.
| Key Concept | Description |
|---|---|
| Bounding Box | Defines the location of objects within an image |
| Classification | Identifies the object's class or label |
| Localization | Determines the exact position of the object |
| Intersection over Union (IOU) | Evaluates the similarity between predicted and ground truth bounding boxes |
Object Detection Approaches
Object detection can be tackled through two primary approaches: traditional and deep learning-based. The former, including HOG and Haar Cascades, involves creating features and algorithms by hand. These techniques are used to spot objects in images.
HOG, for example, studies local gradient arrangements to pinpoint object outlines and forms. In contrast, Haar Cascades employ a sequential process. They ascertain if parts of an image are either an "object" or "non-object".
HOG Haar Cascades
Tools and Frameworks for Object Detection
Object detection relies on specialized tools and frameworks for both model creation and deployment. Options like TensorFlow, PyTorch, and OpenCV stand out. Each brings unique strengths to the table in the realm of object recognition tasks.
Deep Learning Frameworks: TensorFlow and PyTorch
TensorFlow and PyTorch stand as key pillars in the deep learning realm. They elevate the process of object detection through their high-level APIs. These frameworks come equipped with various models, tools for training, and libraries. They streamline the path to implementing detection models.
TensorFlow shines as an open-source giant, supporting various deep learning models. It's a top choice for those working on object detection due to its broad community and model availability. This means it adapts well to various detection challenges.
PyTorch takes a different route with its dynamic computational graph. This feature opens doors to more creative model designs. Known for its simplicity and approachability, it draws many researchers and practitioners in deep learning.
Image Processing with OpenCV
OpenCV isn't a deep learning framework itself but an essential in image processing. It plays a key role by enhancing object detection when joined with deep learning tools. Offering extensive image manipulation functions, it prepares image data for the best detection results.
OpenCV
Integrating TensorFlow, PyTorch, and OpenCV can fast-track the creation of object detection models. This integration allows you to take advantage of pre-existing models, prepare for specific tasks, and marry deep learning’s strength with image processing.
| Framework | Advantages |
|---|---|
| TensorFlow | - Vast collection of pre-trained models - Scalable and flexible platform - Extensive community support |
| PyTorch | - Dynamic computational graph - Developer-friendly ecosystem - Popular among researchers |
| OpenCV | - Comprehensive image processing functions - Efficient image manipulation - Integration with deep learning frameworks |
When choosing the right tools for your project, consider your team's expertise. TensorFlow, PyTorch, and OpenCV offer a strong base. They help craft efficient and precise object detection models. By leveraging these frameworks, you unlock the full potential of deep learning in computer vision.
Training a Custom Object Detection Model
Teaching a custom object detection model involves numerous steps for reliable and efficient object recognition in visuals like images or videos. Initially, you gather labeled data, images paired with marked-out boxes indicating the object's exact location and size. This data is pivotal for the model to learn precise identification.
With labeled data in hand, the journey proceeds to data preprocessing. In this stage, images are made uniform in size. Normalization steps are applied to improve the data quality, and data augmentation adds variety to the training set.
After settling on a model, the process turns to model fine-tuning. Here, you train the chosen model on your specific dataset, refining it for your unique needs. This step optimizes the model's performance for the targeted recognition of objects.
As the final step, your tuned model is ready for inference on new visuals. It will accurately identify and locate objects, opening doors to a myriad of use cases in computer vision and other cutting-edge fields.
Challenges and Considerations in Object Detection
Implementing object detection presents several key challenges. These include handling data, the choice of model, hardware needs, and processing in real-time. To create efficient systems, developers have to address each of these hurdles carefully.
Annotated Data: Ensuring High Quality
High-quality annotated data is crucial for training reliable object detection models. Annotations, like bounding boxes and labels, offer a solid training base. Still, gathering a sizable, well-annotated dataset is often labor-intensive and requires expertise. Keylabs is an excellent tool to help you with that.
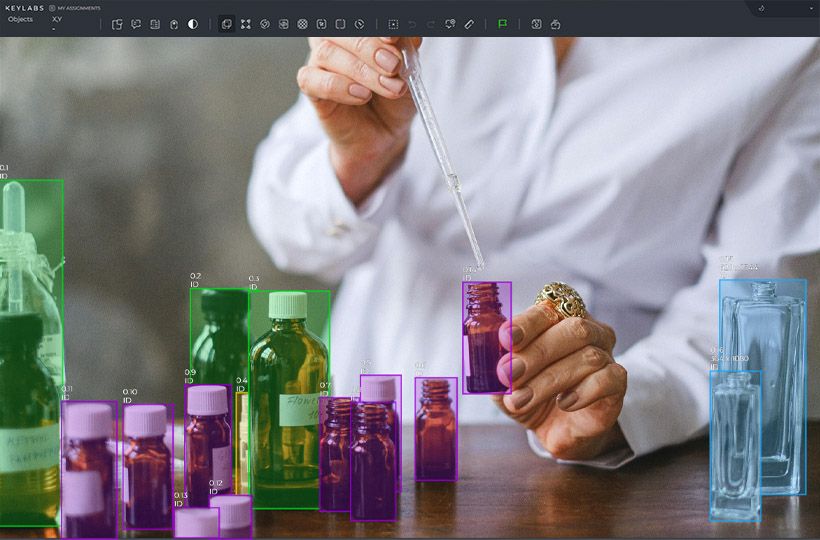
Meeting Hardware Requirements for Training Deep Learning Models
Developing deep learning models for object detection necessitates considerable computational power. Utilizing GPUs with high memory and parallel processing can help meet these needs. It's essential to match hardware to the training process to avoid delays.
Implementing Real-Time Processing for Low Latency
For systems demanding quick reactions and minimal latency, real-time processing is indispensable. Achieving real-time operation requires model and pipeline optimizations. Techniques like model pruning and efficient memory usage significantly reduce inference times, enhancing system performance.
"Addressing the challenges of obtaining high-quality annotated data, choosing the best model architecture and hyperparameters, ensuring adequate hardware resources, and implementing real-time processing is pivotal for object detection systems' success."
Object Detection Models: R-CNN, Fast R-CNN, Faster R-CNN
In the realm of object detection, several models exist to boost both accuracy and speed. Among these stand R-CNN, Fast R-CNN, and Faster R-CNN. They've each brought new methods to the table for region recommendation and data extraction.
R-CNN
R-CNN, which stands for Region-based Convolutional Neural Network, changed the game by suggesting a new way to look at region proposals. Instead of feeding the entire image into a neural network, R-CNN breaks it down into regions. It then picks out the regions likely to hold objects.
This model works in two stages. First is the selective search for region proposals and then the use of pre-trained CNNs for extracting features. Selective search looks through the image's regions using cues like texture and color to pick out possible object locations. The chosen areas are then fed into the CNN for feature extraction, classification, and precise location determination.
Fast R-CNN
Fast R-CNN was next, taking R-CNN’s foundations and making them faster and more precise. A standout improvement was the addition of ROI (Region of Interest) pooling. This allowed for quicker, more efficient feature extraction from the selected regions. Instead of extracting features for each proposal independently, ROI pooling could perform a pooling operation across a fixed area in the CNN's output.
Additionally, Fast R-CNN brought to the table a multi-task loss function to enhance both object classification and bounding box setup accuracy. By optimizing these two tasks at once, the model refined its overall performance.
Faster R-CNN
Then came the Faster R-CNN model, which did away with selective search altogether. Instead, it introduced a Region Proposal Network (RPN) to directly create region proposals. The RPN is designed to forecast regions where objects might be found, using anchor boxes and convolutional features.
Faster R-CNN merges this RPN with the Fast R-CNN architecture, creating a faster, more complete model for object detection. This integrated approach improves upon both efficiency and precision compared to prior models.
In review, R-CNN pioneered the use of region proposals and a two-stage strategy, while Fast R-CNN evolved this process with ROI pooling and a joint learning loss function. Faster R-CNN then streamlined the method further by introducing a direct region proposal generation mechanism with the RPN.
Advancements in Object Detection Models
Object detection technology is advancing rapidly, moving past the R-CNN models. A significant breakthrough is the emergence of single-stage detectors. They are known for their superior results and quicker operation.
Single-stage detectors work more efficiency by skipping the region proposal step. Instead of this, they instantly predict the object's category and location. This means they can detect objects in real-time with high precision.
Models like MobileNet and ResNet play a crucial role in these advancements. MobileNet is preferred for its light and efficient design, especially for devices with limited resources. On the contrary, ResNet is excellent at capturing intricate image details, enhancing detection accuracy.
Thanks to MobileNet and ResNet's capabilities, object detection technology has seen a significant boost in performance and efficiency. This progress hasn't just improved object recognition; it has also opened new doors in various industries.
Benefits of Advanced Object Detection Models
- Improved Performance: New models bring better accuracy and speed, allowing for instant analysis of visual data.
- Efficiency: They cut down on complex processes, making the detection much simpler and more efficient.
- Applicability: MobileNet and ResNet can be used in fields like autonomous driving, surveillance, and AR.
- Versatility: These models can track and identify items of various forms, sizes, and postures effectively.
Progress in object detection models is nonstop. Researchers and developers are always aiming to extend the borders of computer vision. These advancements offer new opportunities and support the ongoing development of object recognition in our digital world.
Summary
Object recognition technology is a game-changer across diverse industries, driving precise detection and classification of objects. Its reach extends to automotive, manufacturing, and security systems, among others.
This primer equips you, whether aiming for a career or just curious about the field. It offers a strong foundation for exploring the vast potential of object recognition technology.
FAQ
What is object recognition technology?
Object recognition technology is a high-level computer vision task. It serves for both finding and categorizing objects. This tech sees use in auto, manufacturing, and safety.
What is object detection?
Object detection is part of recognizing objects. It spots and labels them in pictures or videos. This gives details for accurate positioning, necessary for counting, tracking, and interacting digitally.
What are the key concepts in object detection?
Object detection grasps ideas like bounding boxes for placement, classifications of what objects are, and pinpointing their spots. It also covers IOU, which gauges how well found objects match the actual.
What are some tools and frameworks for object detection?
For object detection, there's TensorFlow, PyTorch, and OpenCV. TensorFlow and PyTorch offer great tools at a high level. OpenCV complements them with strong image processing abilities.
How can I train a custom object detection model?
Training a custom object model requires data with detailed annotations. You'll collect and preprocess data, select a model, fine-tune it, and then apply it to look at new images or videos.
What are the challenges in object detection?
Object detection faces the challenge of needing precise annotated data and selecting the best model settings. It must also cope with deep learning hardware demands and meet real-time processing needs.
What are some object detection models?
Notable models in this field are R-CNN, Fast R-CNN, and Faster R-CNN. They use innovative methods like region proposals and pre-trained CNNs. These improve both accuracy and speed.
What are the advancements in object detection models?
Recent progress includes models like MobileNet and ResNet, offering speed and quality beyond past models. They outperform the likes of VGG-16, introducing better efficiency.
What is the role of object recognition technology in industries?
In many sectors, object recognition is vital. It assures precise detection and sorting of objects. This extends to vehicles, production, safety, and more.