3 main labeling tools for medical projects
Labeling is an essential component of medical projects, as it helps to identify and categorize data for analysis and decision-making. There are several labeling tools available that can streamline the process and improve accuracy. In this article, we will explore the three main labeling tools used in medical projects: Natural Language Processing (NLP), Rule-based Systems, and Machine Learning.
First, we will delve into NLP, which uses algorithms to analyze and understand human language. We will discuss the advantages and limitations of NLP in medical projects. Next, we will explore Rule-based Systems, which use a set of predefined rules to categorize data. We will explain how these systems improve labeling accuracy. Finally, we will examine Machine Learning, which uses algorithms to learn from data and improve over time. We will discuss the types of Machine Learning algorithms used in medical projects.
Throughout the article, we will provide best practices for labeling in medical projects and discuss the challenges and future developments in labeling tools for medical projects.

Introduction To Labeling Tools In Medical Projects
Labeling is an essential aspect of medical image analysis and text annotation for machine learning (ML) models. It involves identifying and classifying specific features, such as pathologies, anatomical regions or cell types within images or text documents. Medical data labeling experts at Keymakr review images to identify and classify pathologies for ML training.
There are two main categories of data labeling tools: price-based (developed in-house or outsourced) and open or closed-source software.
Labeling medical devices requires compliance with regulations established by the US Food & Drug Administration (FDA). The use of Unique Device Identifier (UDI) is required by the device manufacturer when creating 2D/3D medical image labels. The FDA recognizes several formats such as GS1 and HIBCC, which must conform to regulatory guidelines outlined in their guidance document on the regulatory approach for medical device labeling. Imprinted labels may contain symbols without explanatory texts, explanatory texts along with symbols, or standalone symbols that comply with a relevant standard.
Organizations require data management tools that facilitate quality control measures in project-based medical data analysis. Six components are critical to successful label generation workflows: annotation software, AI management systems including extension frameworks, secure access integrations like Google Drive/Version Control Systems/NAS storage/Others), project management platforms like Monday.com/Jira/Trello/Others), QA/QC mechanisms that include third-party auditing companies during a pilot study phase resulting in coding instructions customized per individual rater/group, workflow automation tools using APIs/Mercurial to move scripts around quickly between different repositories among team members electronically accepting/redacting recommendations inline or via chatbot interphases optimizing feature engineering models, and data curation management subsystems ensuring annotation consistency between actively labeling teams to receive quality user feedback on labeling skills for subsequent sessions in the next release cycle.
Labeling Tool 1: Natural Language Processing (NLP)
Natural Language Processing (NLP) is one of the most popular labeling tools in medical projects. NLP systems like ETHER, I2E, and MetaMap have the ability to extract Adverse Event (AE) terms from drug labels and map them to the Medical Dictionary for Regulatory Activities (MedDRA). The National Library of Medicine's NLP research focuses on developing algorithms for automated text analysis in biomedical literature and electronic medical records. Text data can provide valuable information but only offer one lens into patient health. NLP technology is becoming increasingly popular in smart communication between people and devices in healthcare.
NLP technology uses machine learning algorithms such as convolutional neural networks( CNN), Bidirectional Encoder Representations from Transformers(BERT) or Long short-term memory(LSTM), and statistical models to enable computers to understand human language naturally. However, data labeling is crucial in training NLP models to understand human speech accurately. Open-source labeling tools like brat and WebAnno are popular for advanced NLP tasks such as dependency labeling.
NLP facilitates the development of user-friendly medical applications by understanding natural language spoken or typed by patients. An essential aspect of the development process is verifying that the model correctly understands unstructured text by testing it against labeled data sets made up of medical terminologies, concepts, relationships encoded into a standard format( e.g., SNOMED CT). Deep analysis can help understand recent developments in an NLP-empowered medical research field. In conclusion, Natural Language Processing systems with their built-in machine-learning algorithms present robust opportunities for automatically embedding structure into unstructured text datasets while minimizing manual input from a team member while maintaining significant accuracy levels given adequate access to old legacy terminology databases containing accurate clinical definitions around drugs-like-medication actions-based events reporting mandated globally by regulatory authorities but tracking pharmacovigilance signals at all times.
Advantages And Limitations Of NLP In Medical Projects
Natural Language Processing (NLP) is a computer-based technology that enables machines to understand and interpret human language. It has become an essential tool in many industries, including healthcare. Here are some advantages and limitations of using NLP in medical projects.
Advantages:
1. Accurate Diagnosis: There is a vast amount of data in healthcare, making it difficult for clinicians to extract relevant information from patient records. NLP algorithms can help by accurately identifying key phrases within documents, reducing the time taken to analyze patient data.
2. Improve Patient Care: Incorporating NLP into electronic health records (EHRs) can enable better care coordination and provide real-time alerts when errors or potential risks are identified.
3. Cost-Effective: By automating administrative tasks such as scheduling appointments or managing insurance claims, NLP can significantly reduce overhead costs associated with manual labor.
Limitations:
1. Lack of Standardization: The terminology used in medical documents varies widely between healthcare providers, making it challenging to develop algorithms that accurately capture the context and meaning of individual terms.
2. Data Privacy Concerns: As with any technology that interfaces with patient data, there are concerns around patient privacy regulations such as HIPAA law which guidelines should be closely followed.
3. Bias May Affect Algorithm Accuracy: Some studies have shown that NLP algorithms may exhibit bias towards certain demographics or population groups during analysis when trained on datasets containing a particular demographic-related bias without proper countermeasures deployed resulting in skewed insights extracted from inaccurate models generated by this process.
While incorporating Natural Language Processing into medical projects has its advantages like improving accuracy diagnosis detection and saving cost through automation administrative tasks; there are also potential limitations like EHR standardization issues, concerns for handling sensitive PII( Personally Identifiable Information), & potential biases affecting the accuracy interpretation gleaned from the application's output results used within NLP algorithms. Therefore, careful consideration must be given to deploying and maintaining NLP technology in sensitive healthcare project contexts.
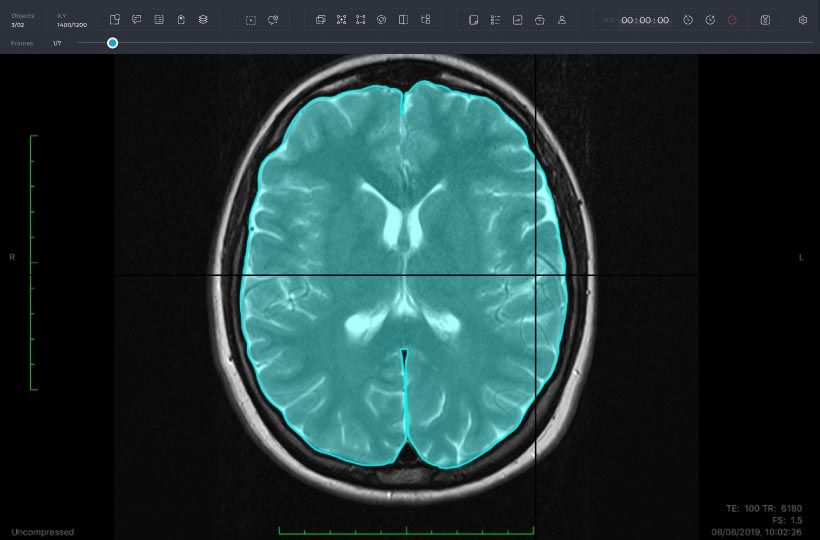
Labeling Tool 2: Rule-based Systems
Another useful labeling tool for medical projects is the rule-based system. This tool draws on sets of predefined rules to categorize and label medical data. These rules could be based on specific terminology or an established set of guidelines, such as the International Classification of Diseases (ICD). Rule-based systems can save time and increase accuracy by automating much of the tedious task of manual labeling.
Rule-based systems work by processing input data through a set of predefined rules or criteria. For example, a rule may dictate that any mention of "heart attack" should be labeled as "cardiovascular disease". Once the label is applied, the system may also trigger additional actions such as alerting healthcare providers to potential concerns or recommending treatment options based on similar cases. By automating this process, rule-based systems enable organizations to process large volumes of data more quickly and precisely than would otherwise be possible.
However, it's important to note that rule-based systems require careful setup and maintenance in order to achieve optimal performance. Rules must be constantly reviewed and updated to ensure they remain relevant and accurate over time. Organizations using rule-based systems should also implement regular quality assurance checks to identify any errors in labeling or associated actions triggered by those labels. With proper care and attention, however, rule-based systems can be an efficient addition to any medical project's toolkit for managing complex data sets with precision and ease.
How Rule-based Systems Improve Labeling Accuracy
Labeling in medical projects is a crucial task that requires high accuracy and objectivity. This is where rule-based systems come into play. Rule-based systems utilize pre-established rules to improve diagnostic accuracy and objectivity in medical decision support systems. By automating the labeling process, clinicians can save time and prevent errors.
Moreover, machine learning and rule-based systems can aid in the identification and normalization of Adverse Drug Reaction (ADR) entity mentions. ADRs are harmful side effects associated with specific drugs. Detecting these reactions accurately is essential for patient safety, which emphasizes the importance of having reliable labeling tools such as rule-based systems.
Rule-based expert systems have also played an important role in modern strategic goal setting, planning, design, and scheduling intelligent systems. These systems operate autonomously by applying reasoning techniques to reach conclusions based on established rulesets. With this technology at their disposal, healthcare professionals can better prioritize tasks related to patient care.
It's worth noting that skilled experts like linguists or knowledge engineers are required to manually encode rules in Natural Language Processing (NLP). In fact, rules-based approaches require expertise to develop algorithms that meet industry standards for accuracy and specificity.
Rule-based labeling tools can significantly improve the accuracy of critical medical decisions while saving healthcare professionals valuable time by automating repetitive diagnosis-related tasks. By implementing this technology with subject matter experts' guidance correctly, patients will receive better care from reliable diagnostic options provided by intelligent learning AI functionality designed specifically for them.
Labeling Tool 3: Machine Learning
Machine learning in the medical field requires accurate data labeling to ensure the integrity of predictions and diagnoses made from the data. This step is crucial in discovering new drugs, treating diseases, measuring medical imaging and diagnostics, and maintaining organized medical records. Data labeling can be categorized into three types: price-based, open source, and closed source tools.
Keylabs offers a full range of capabilities, including such as bounding box image annotation and text classification for machine learning teams. It provides an easy-to-use interface where stakeholders can access a central repository of labels on both labeled or unlabeled datasets. The platform allows for quick iteration to improve accuracy and reduce time spent on manual processing.
Data labeling can either be done by an in-house team or outsourced to third-party services. Choosing between these options depends on factors like budget constraints, project timeline efficiency, skill set requirements of labelers or annotators, among others.
Image/video labeling, text labeling, and audio labeling are exemplary use cases for machine learning projects requiring data labeling. Accurate labels lead to better performance metrics when using algorithms trained with supervised machine learning techniques such as logistic regression models.
Investing in sound data analytics involving appropriate labelers ensures AI models' success while identifying patterns quickly across vast amounts of healthcare-related clinical data sets that would not otherwise be discoverable manually or through traditional modes of analysis.
Types Of Machine Learning Algorithms Used In Medical Projects
The use of machine learning algorithms in medical projects has the potential to save lives. However, before implementing these algorithms, it is important to choose the right tool and labeling method for your dataset.
One common type of machine learning algorithm used in medical projects is Regularized General Linear Model regression (GLMs). This algorithm can help predict outcomes for patients based on their medical history. Another popular algorithm is Support Vector Machines (SVMs) with a radial basis function kernel, which can be used for image analysis and classification tasks.
Single-layer Artificial Neural Networks are another type of algorithm that can be used in medical projects. These networks are designed to mimic the behavior of neurons in the human brain and have been used to detect cancerous cells in X-ray images.
When working with medical datasets, data labeling is a critical step. Three types of generative models - Generative Adversarial Networks (GANs), Autoregressive models (ARs), and Variational Autoencoders (VAEs) - can help automate this process.
Challenges And Future Developments In Labeling Tools For Medical Projects
Labeling tools have become increasingly important in medical projects. They have evolved from manual annotation to semi-automated and fully automated systems, which can help reduce the amount of time needed for labeling medical data accurately. However, one of the main challenges in developing accurate and consistent annotations is dealing with complex medical data. Describing unclear or subjective information becomes difficult when it comes to training the machine learning models used to make labels.
Another challenge that needs to be addressed is ensuring that the labeling process is secure and HIPAA-compliant. For instance, a webinar organized by Amazon Web Services in September 2021 discussed how enterprise customers need specific controls for access control, auditability, event logging and more when designing their applications on HITRUST solutions.
To address these issues, natural language processing (NLP) and machine learning are expected to play major roles in future developments for labeling tools in medical projects. NLP offers a way of extracting meaningful information from clinical notes using computational linguistics techniques such as named-entity recognition (NER), which identifies entities like drugs or diseases mentioned within text-based data. Machine learning offers automated methods for identifying spectroscopy peaks although much work remains before they are suitable for deployment on patients outside of research settings.
These advancements will potentially improve accuracy while also increasing efficiency in the labeling process when dealing with large amounts of diverse datasets that go beyond radiology images such as surgical notes, pathology cases or electronic health records (EHRs). Indeed according to Kumar et al., hybrid AI models comprising various machine-learning classifiers along with NLP components seem promising solutions for annotating uncontrollable document structures e.g., unformulated EHRs often used in hospital settings where information can be spread across different sections making them not useful without additional technology like semantic analysis.