3 Reasons why to choose manual data labeling
In the world of machine learning, data is king. But before data can be fed into algorithms, it needs to be labeled and organized. This process, known as data annotation or data labeling, is essential for training machine learning models to recognize patterns and make accurate predictions. While automated data labeling methods are available, manual data labeling remains the gold standard for accuracy, flexibility, quality control, and cost-effectiveness.
In this article, we'll explore three key reasons why manual data labeling is the superior choice for your data annotation needs. We'll examine the benefits of manual data labeling for unique or complex datasets, the quality control measures that ensure high-quality data, and the cost benefits of manual labeling compared to automated methods. We'll also look at case studies of successful manual data labeling projects and best practices for effective labeling. By the end of this article, you'll have a clear understanding of why manual data labeling is the best choice for your machine learning projects.

Introduction To Manual Data Labeling
When it comes to preparing data for supervised machine learning, data labeling is a necessary process. This involves identifying objects in raw data and tagging them with labels, which helps algorithms learn how to recognize patterns and make predictions. There are two types of data labeling: labeled and unlabeled. Labeled data is more difficult and expensive to acquire and store, while unlabeled data is easier and cheaper to acquire.
While there are tools that can assist in the labeling of raw data, manual data labeling can produce better results. Here are three reasons why choosing manual data labeling can be beneficial:
Firstly, professional human labelers have a broader understanding of context beyond what machines can detect on their own. Relying solely on automated processes may result in misinterpretations or inaccurate labels that could hinder the success of your project.
Secondly, through manual label assignments at scale with hundreds or thousands of workers, you can improve the efficiency and speed with which your algorithms learn from this labeled dataset. Having a large workforce will enable faster completion of tasks thereby ultimately accelerating product time-to-market.
Lastly, by hiring an experienced team responsible for annotating machine learning datasets you ensure that high quality standards are met. Professional services provided by these teams include strict guidelines for quality assessment such as multiple rounds of auditing across each batch so satisfactory outcomes will be reached.
Overall, while manual data labeling can be more labor-intensive than automated solutions; it results in higher accuracy rates allowing businesses to train ML models efficiently, leading them closer towards achieving true AI initiatives with robust datasets that build killer applications or products!
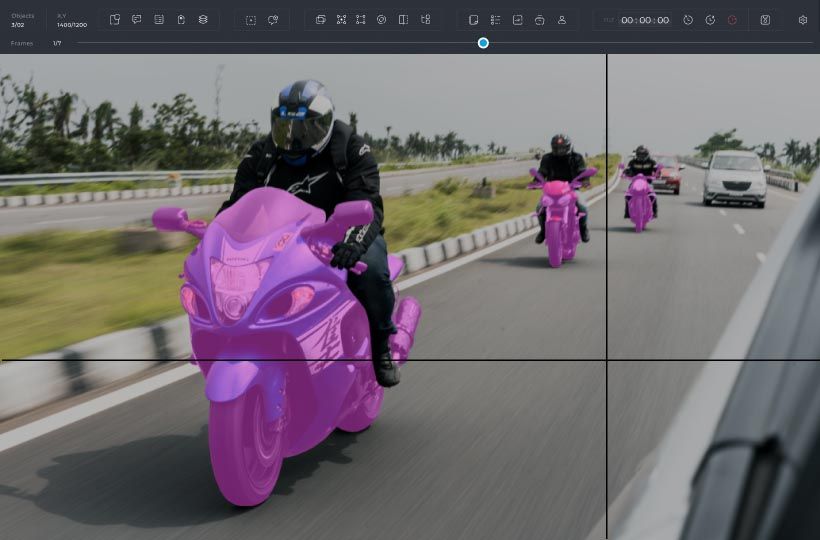
Accuracy: Why Manual Data Labeling Is More Precise Than Automated Methods
Manual data labeling has become a popular option for data labeling due to its greater control and accuracy over automated methods. This process involves assigning labels to data by humans who are extensively trained to understand the data and labeling guidelines, ensuring greater quality overall.
One significant benefit of manual labeling is the ability to capture edge cases that may be easily missed by automated systems. This feature is particularly helpful when working with complex or ambiguous data that requires contextual knowledge and interpretation. The trained labelers can provide valuable insights into these cases, resulting in more accurate data and better decision-making outcomes.
Furthermore, manual labeling provides an extra level of quality assurance since knowledgeable human managers ensure high-quality standards across huge volumes of data. They can identify errors, inconsistencies or missing information in the dataset while also training new members on how to achieve optimal results through adherence to best practices.
Flexibility: The Benefits Of Manual Data Labeling For Unique Or Complex Datasets
In the field of Machine Learning (ML), high-quality datasets are essential for building effective models. Manual data labeling allows for flexibility in describing or attributing data, making it a crucial tool for unique or complex datasets. This is particularly important in niche industries and sectors where public or synthetic datasets may be insufficient.
One of the key benefits of manual data labeling is the ability to capture edge cases that automated systems may miss. Highly skilled labelers can provide precise and consistent labels, enabling the creation of high-quality datasets necessary for various ML applications. This ensures that models produce accurate predictions even in situations where there is little to no pre-existing data available.
Manual data labeling also allows consultation with experts in relevant fields, further improving the accuracy and granularity of labeled data. In industries such as healthcare and finance, where safety and compliance are paramount concerns, manual data labeling offers customizable solutions specific to each use-case.
In conclusion, manual data labeling offers flexibility that is not possible with automated systems when dealing with unique or complex datasets. Accurately labeled training sets lead to more effective models within industries looking for highly specialized expertise to succeed. With highly skilled labelers able to provide detailed insight into rare and esoteric areas of knowledge needed in particular fields - ensuring your dataset will accurately reflect what you need it too; choose manual data labeling over automation wherever possible!
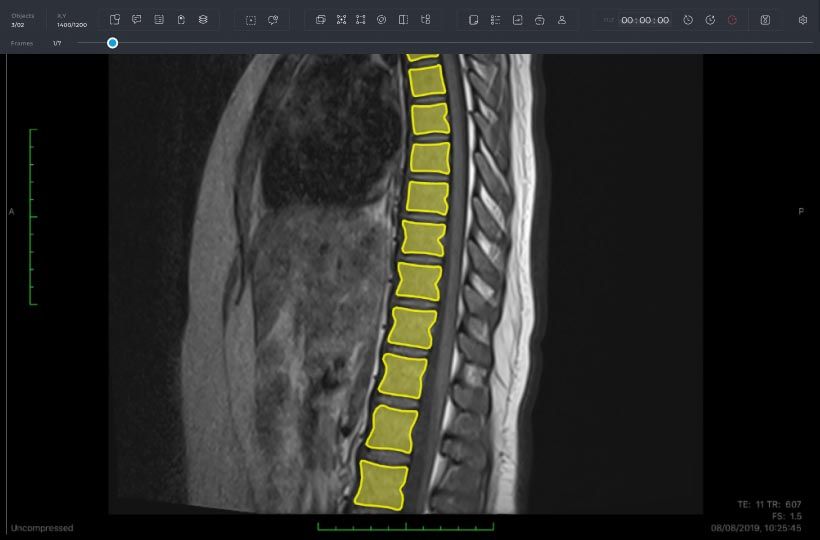
Quality Control: How Manual Data Labeling Ensures High-quality Data For Machine Learning Models
Manual data labeling significantly improves the precision with which labels are applied to each data point. It ensures that human insights are used to catch details and nuances that machines cannot identify, improving the reliability of predictions delivered by machine learning models. For instance, imagine training an autonomous driving system without human labelers identifying different types of vehicles, pedestrians and obstacles.
Secondly, it’s important to choose experts from your field for successful manual annotation. Subject matter experts can provide nuanced tags where necessary or provide additional information such as weather conditions that can impact the image or a user's boots since there could be slight differences in boot design with regards to various locations around the world . By involving these individuals into your annotation best practices system you will see positive results based on their feedback and attention-to-detail.
Lastly, conducting Qualify Assurance (QA) testing alongside taxonomy creation is essential for achieving accuracy during manual data labelling. Testing assists in minimizing mistakes by noting common errors users have made like time delay between submitting annotations or outliers once judges receive annotations back a second time around . This procedure along with creating clear instructions makes sure annotators understand how they need to tag each item while removing any miscommunication between stakeholders involved regarding what exactly needs tagging done on them.
In conclusion ,manual data labeling plays an important role when it comes down high quality datasets through expert involvement and clear instructions setting the stage for detailed labelling activities.Combining QA testing as part of your mission statement ensures further normalization which leads to better reliance once you get to model performance evaluation phase.The use of subject matter experts coupled with established processes allows teams building machine learning applications using visual data to experience solid foundations that ensure long-term success . There is a time and place for automated labeling in the field, but manual data labeling ensures higher quality datasets overall.
Cost-effectiveness: The Cost Benefits Of Manual Data Labeling Compared To Automated Methods
Manual data labeling is the process of manually annotating data for machine learning or artificial intelligence systems. While automated methods are often faster and cheaper, there are several reasons why manual labeling is preferable in certain situations. In this article section, we will focus on the cost benefits of manual data labeling compared to automated methods.
The three main reasons why manual data labeling can be more cost-effective than automated methods are control, quality assurance, and task complexity. With manual labeling, human managers have greater control and precision over the labeling process, ensuring that annotations are accurate and consistent. This means that errors can be corrected as they arise rather than waiting for a potentially costly correction down the line.
Furthermore, human managers can ensure quality across large volumes of data by implementing rigorous standards for annotation. Automated systems lack this level of precision without significant investment in engineering resources. This can result in inaccurate annotations that may require retraining models or scrapping entire datasets—both costly outcomes.
Finally, while automated methods may be cheaper upfront due to reduced labor costs, they may end up being more expensive in some scenarios requiring direct instructions or involving subject-area expertise. Tasks such as image recognition require complex domain knowledge to pinpoint objects with great accuracy which cannot be achieved without any necessary steps taken by humans with enough knowledge about their fields.
Best Practices: Tips For Effective Manual Data Labeling
When it comes to data labeling, manual labeling is often the best option for accuracy and flexibility. Here are three reasons why choosing manual data labeling can benefit your project:
1. High Accuracy: Manual data labeling can provide higher levels of accuracy compared to automated methods. This is because humans can pick up nuances in the data that a machine may miss. It also ensures that the labels are consistent across all items, giving you more reliable results.
2. Flexibility: Manual data labeling allows for flexibility in the type of items being labeled and the label categories used. Labelers can quickly adapt to new tools and different types of content, making it easy to expand your dataset as needed.
3. Active Learning: Implementing an active learning approach with manual data labeling can significantly reduce time and cost while also improving accuracy. By strategically sampling items for labeling based on uncertainty or low confidence scores, labelers can work smarter not harder.
To maximize these benefits, there are several best practices you should follow when implementing manual data labeling:
- Choose representatives who are experts in the field to label data
- QA test your taxonomy to ensure consistency and appropriateness
- Use an integrated management system for project, data, and user management
By following these tips, your team will be able to optimize their manual data labeling efforts effectively while ensuring high-quality results that support your business goals.
Manual data labeling offers numerous advantages over automated methods. It provides greater accuracy, flexibility, and quality control, while also being cost-effective. By choosing manual data labeling, businesses and organizations can ensure that their machine learning models are trained with high-quality data, leading to better performance and results. Additionally, following best practices for manual data labeling can further enhance the accuracy and efficiency of the process. Overall, manual data labeling is a smart choice for those looking to improve their machine learning capabilities.