3D Pose Annotation: Harnessing Skeletal Data for Advanced Applications
This approach creates detailed digital representations of human movement by mapping and connecting body points. These models are used to train machine learning systems to recognize gestures, predict actions, and interact naturally with users. The process goes beyond simple labeling—it captures spatial relationships and movement patterns that enable rich augmented reality experiences and adaptive robotics.
Modern methods combine real-time tracking with advanced analytics, allowing developers to refine AI behavior. Human pose annotation platforms demonstrate how integrating 2D/3D data visualization improves the efficiency of model training. Such accuracy ensures systems can interpret complex scenarios, from sports analytics to medical rehabilitation monitoring.
Quick Take
- Skeleton-based annotations transform visual data into structured motion patterns.
- Accurate labeling impacts AI performance in real-world applications.
- Combined 2D/3D visualization improves AI model training efficiency.
- Real-time tracking capabilities facilitate adaptive systems.

Introduction to 3D Skeleton and Pose annotation
Modern AI systems need structured motion maps to understand human-like motion. These frameworks map biological motion through interconnected points, creating dynamic models that machines interpret as fluid actions rather than static images.
Basic principles of motion mapping
During this process, critical points of the body and their spatial relationships are identified. Early methods focused on identifying isolated joints, while modern approaches capture entire sequences of movements. This allows systems to analyze actions ranging from subtle gestures to complex athletic maneuvers.
Driving innovation in visual intelligence
The demand for accurate motion analysis is growing, so developers are now prioritizing three important components:
- Temporal coherence in movement sequences.
- Contextual understanding of body mechanics.
- Adaptive learning for diverse physical variations.
This allows machines to interpret movement with high accuracy, which is driving breakthroughs in rehabilitation technologies, interactive systems, and advanced CV applications. As visual intelligence advances, robust analysis frameworks become the foundation for accurate AI decisions.
Skeletal Annotation Basics
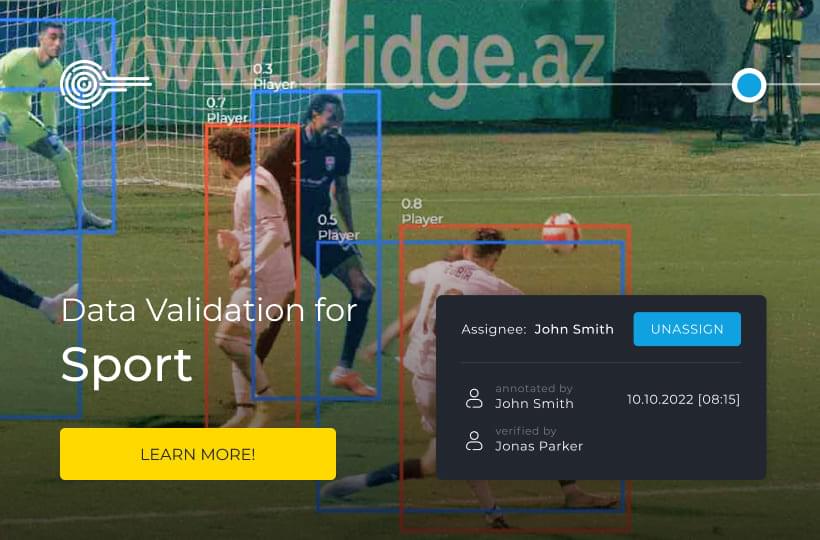
Skeletal annotation labels key points of the human body in images or videos for further use in computer vision tasks such as motion tracking, posture analysis, anomaly detection, or gesture control. This type of annotation is based on fixing the positions of joints (elbows, knees, ankles) and connecting them into a single structure that represents the skeletal model of a person. Each point has coordinates that correspond to a specific anatomical landmark. Annotation can be performed manually using special tools or automatically using pre-trained AI models. The quality of skeletal annotation affects the training of models that need to recognize movements with high accuracy, including in healthcare, sports, robotics, and augmented reality.
Advanced technologies underpinning skeletal annotation
Advantages of these machine learning models include:
- Adaptation to lighting and angle changes.
- Reduced training data requirements.
- Better predictability.
How to Use 3D Skeleton and Pose Annotations
Data Loading and Ontology Configuration. A successful implementation starts with organizing your dataset properly. Start with curated image sets that show different body positions and lighting conditions. Cloud-based solutions allow for batch loading and preserve relationships between files through smart tagging.
Define joint sequences and connection rules that reflect human biomechanics. Key components include:
- Configurable key point labels that match the use case.
- Flexible limb connection protocols.
- Validation options at different angles.
- Step-by-step annotation process.
Advanced tools simplify marker placement using predictive algorithms. Select reference frames that demonstrate complete body visibility. The system will suggest initial joint positions that annotators refine using edge snapping.
Step-by-step workflow for consistent results:
- Mapping primary joints using drag markers.
- Establishing bone connections using automatic curvature detection.
- Checking temporal consistency between video sequences.

Keypoint vs. Skeleton
Why do some AI models understand movement better than others? The answer lies in how they process anatomical data. These are two different approaches: labeling isolated points versus interconnected structural analysis.
For tasks that require deep motion analysis, such as physical therapy evaluation, skeletal methods outperform isolated markers. They capture how shoulder rotation affects hip position during rehabilitation exercises. This level of detail leads to advances in human motion recognition.
Applications of Skeletal Annotation
Structured motion analysis is now driving innovation in various industries, creating solutions that adapt to human behavior.
Modern animation studios use frame-by-frame motion tracking to create characters that move with anatomical accuracy. This technique captures minor weight distribution and joint rotation changes, transforming Gi-quality animation into realistic performances. In virtual reality, real-time body mapping allows avatars to display detailed user gestures, down to finger movements.
Skeletal annotation tools enable:
- Natural interaction with virtual objects.
- Emotion-driven character animation.
- Synchronization of multiple users in shared spaces.
Healthcare, robotics, and sports
Medical teams are now investigating rehabilitation progress using millimeter-accurate motion tracking. Sensors detect asymmetries in gait patterns or shoulder mobility, alerting therapists to potential failures.
In sports, coaches analyze athletes’ form using heat maps that show force distribution during complex maneuvers. Robotic engineers apply similar principles to teach machines to:
- Interpret human gestures to perform everyday tasks.
- Adjust grip strength based on the weight of an object.
- Move safely through shared spaces.
Integrating Skeletal Annotations into Machine Learning Models
Training models start with validated motion datasets. This teaches algorithms to recognize patterns through:
- Temporal consistency across frames.
- Applying biomechanical constraints.
- Diverse representation of body types.
Modern platforms optimize data integration through automated validation checks. This reduces the number of training errors compared to manual workflows.
Successful implementation requires three best practices:
- Establish clear rules for a shared hierarchy.
- Use hybrid validation (automated + human validation).
- Update datasets quarterly with new motion patterns.
These strategies create self-improving systems that adapt to new use cases. When done correctly, structured data integration reduces model training time and increases predictive reliability.
Practices for Preprocessing and Data Augmentation
Strategic preprocessing transforms raw input data into a robust foundation for machine learning. It does this through three main techniques: normalization, augmentation, and noise filtering.
Normalization standardizes body positions and lighting variations. Augmentation introduces realistic scenarios through rotation and scaling. Together, they create robust datasets that reflect the complexity of the real world.
Noise reduction requires careful analysis. Random forest classifiers are effective at identifying and removing corrupted frames, preserving the consistency of objects in annotated sequences.
Follow these practical steps:
- Implement multi-step validation.
- Use synthetic data for rare scenarios.
- Check datasets for bias patterns quarterly.
Properly preprocessed information helps models distinguish subtle movements and be accurate.
Future trends in skeletal annotation and 3D technologies
Widespread adoption of unsupervised deep learning is expected to generate 3D annotations from 2D data, allowing labeling scaling without manual intervention. There is also growing interest in using mobile 3D scanners, LiDAR cameras, and wearable sensors that provide high accuracy in dynamic environments (sports, healthcare, robotics).
An important trend is the development of real-time annotations for interactive systems such as XR/AR applications and the generation of full 3D skeletal-based avatars for metaverses. At the same time, synthetic 3D data is being actively implemented to train models without using real biometric records to ensure ethics and privacy. In the coming years, the emergence of unified 3D annotation standards is also predicted, which will ensure compatibility between different systems and platforms.
FAQ
What is the difference between keypoints and skeletal annotations?
Keypoints are discrete coordinates in an image corresponding to important anatomical landmarks (e.g., elbow, knee). Skeletal annotation combines these key points into a structure that mimics the human skeleton for further analysis of motion or pose.
How do deep learning systems improve pose estimation accuracy?
Deep learning systems automatically learn to recognize complex spatial relationships between body parts, allowing them to reproduce even complex poses accurately.
Why is data augmentation important for training pose estimation models?
Augmenting datasets with variations in illumination, angles, and occlusions helps algorithms generalize better. Techniques such as rotation scaling or synthetic noise mimic real-world scenarios.
How are 3D image sensors changing pose annotation workflows?
3D image sensors automate the collection of spatial coordinates of body points and reduce the need for manual pose annotation. They provide higher accuracy and realism of the skeletal model, especially in dynamic or polygonal environments.
What are the future trends in skeletal annotation and 3D technologies?
They aim to increase the accuracy, automation, and realism of spatial analysis of the human body.