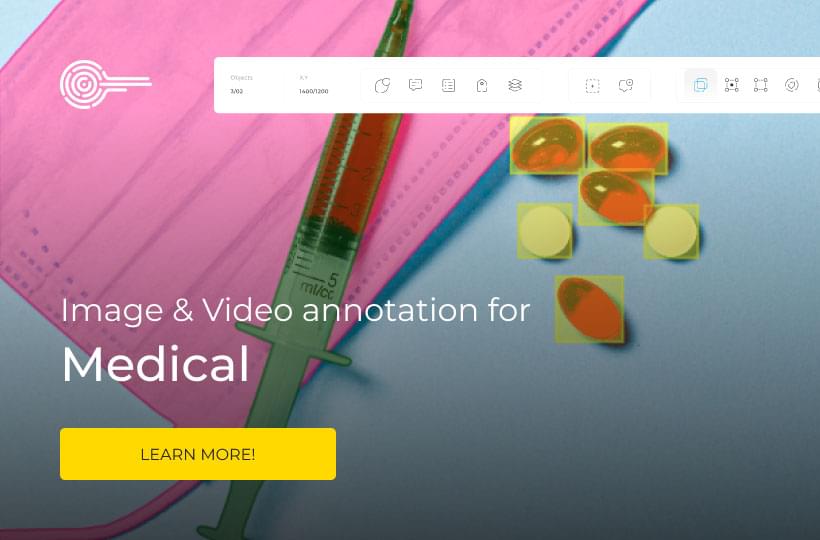
Accuracy and Reliability of Automatic Annotation
Up to 80% of the time spent developing AI is dedicated to data annotation. This fact underscores the vital role that data annotation plays in the development of machine learning models. Ensuring accurate and reliable data annotation is crucial for the effectiveness of these models, especially in fields like healthcare, manufacturing, and defense.
Data annotation involves labeling and categorizing data to train machine learning algorithms. The quality of this annotated data significantly affects the performance of the models. Poor-quality datasets can result in inaccurate predictions, low model performance, and misleading insights, thus wasting valuable resources.
Manual data annotation ensures high accuracy and flexibility but is time-consuming and costly. Conversely, automated annotation offers speed and consistency, making it suitable for large datasets. Finding the right balance between manual and automated annotation is crucial for achieving the best results.
Advances in natural language processing and machine learning have revolutionized data annotation. Tools now combine manual and automatic approaches. Augmented annotation, for instance, aims to surpass manual methods in quality. By leveraging both manual and automated annotation, organizations can optimize costs, maintain dataset consistency, and scale their annotation workflows effectively.
Key Takeaways
- Data annotation is a critical component of machine learning, consuming up to 80% of AI development time.
- The quality of annotated data directly affects the performance of machine learning models.
- Manual annotation offers accuracy and flexibility, while automated annotation provides speed and consistency.
- Balancing manual and automated annotation approaches is essential for optimal results.
- Advances in natural language processing and machine learning have led to the development of augmented annotation tools, improving annotation quality and efficiency.

The Importance of Data Annotation in Machine Learning
Data annotation is vital for the growth and success of machine learning models. It involves labeling data like images, text, or video to provide context for supervised learning. McKinsey suggests AI could add around $13 trillion to the global economy by 2030, underscoring the role of data annotation in AI advancement.
Role of Data Annotation in AI Model Development
Data annotation is crucial for AI model development. It lays the groundwork for training models to recognize patterns and perform tasks accurately. Annotated data feeds into supervised learning algorithms, enabling them to learn from labeled examples and apply to new data. The McKinsey Global Institute notes that 75% of AI and ML projects need updated datasets monthly, while 24% require daily updates, emphasizing the continuous need for data annotation in AI development.
High-quality data annotation is key to developing robust AI models. Accurate annotations help models learn the right patterns and relationships, leading to better performance and reliable predictions. Domain-specific expertise is often necessary for providing meaningful annotations, especially in areas like healthcare, finance, and autonomous vehicles.
Impact of Poor-Quality Training Datasets
Poor-quality training datasets can severely impact AI model development. Inaccurate or inconsistent annotations can lead to biased or misleading insights, resulting in suboptimal model performance and unreliable predictions. This is particularly critical in domains like medical diagnosis, where incorrect predictions can have severe consequences. Low-quality annotations can also lead to wasted resources, as models may need extensive rework or rebuilding.
To address the issues with poor-quality training datasets, implementing robust annotation quality control measures is crucial. Techniques like inter-annotator agreement (IAA) and self-agreement help spot discrepancies and errors. Partnering with reputable data annotation providers who use experienced annotators and best practices ensures high-quality annotations and minimizes the risk of poor-quality training data.
| Data Annotation Technique | Application |
|---|---|
| Named Entity Tagging | Identifying specific entities like "person," "sport," or "country" within text data |
| Sentiment Tagging | Determining sentiment in textual data for applications like social media monitoring and brand reputation management |
| Image Bounding Boxes | Identifying and localizing objects within images for object detection and tracking |
| Video Annotation | Identifying, classifying, and tracking objects within video frames for applications like autonomous vehicles and surveillance systems |
Ensuring high-quality annotations through best practices, expert annotators, and robust quality control measures is essential. This approach maximizes AI's potential and avoids the pitfalls of poor-quality training datasets.
Measuring Data Annotation Accuracy
Ensuring data annotation accuracy is key for high-performing machine learning models. Various metrics and methods are used to measure this accuracy. These tools assess annotation quality, pinpoint areas for improvement, and confirm the reliability of the data.
Inter-Annotator Agreement (IAA)
Inter-annotator agreement (IAA) measures how consistent different annotators are on the same dataset. It shows the extent to which they make similar annotation decisions. IAA is crucial for ensuring the annotated data's quality and consistency across individuals.
Cohen's Kappa
Cohen's kappa evaluates the agreement between two annotators, factoring in chance agreement. It's a statistical measure that offers a deeper look at annotation consistency, especially for binary or categorical tasks. This metric is more precise than simple percent agreement.
Fleiss' Kappa
Fleiss' kappa extends Cohen's kappa to assess agreement among multiple annotators. It measures agreement beyond chance. This metric is ideal for scenarios with several annotators, providing a detailed evaluation of consistency.
Krippendorf's Alpha
Krippendorf's alpha is versatile, handling incomplete data and measuring agreement beyond chance. It's useful for datasets with not all instances annotated by all annotators. This metric considers partial agreement and offers a nuanced view of annotation reliability.
F1 Score
The F1 score is a key metric in machine learning, balancing precision and recall. In data annotation, it compares annotations to a ground truth for a comprehensive accuracy check. This score evaluates both the correctness and thoroughness of annotations.
| Metric | Description | Use Case |
|---|---|---|
| Inter-Annotator Agreement (IAA) | Measures the level of agreement among multiple annotators | Assessing annotation consistency across different individuals |
| Cohen's Kappa | Evaluates agreement between two annotators, considering chance agreement | Binary or categorical annotation tasks |
| Fleiss' Kappa | Assesses agreement among a fixed number of annotators, beyond chance | Multiple annotators involved in the annotation process |
| Krippendorf's Alpha | Handles incomplete data and captures agreement beyond chance | Datasets with missing annotations or partial agreement |
| F1 Score | Combines precision and recall to measure annotation accuracy | Evaluating annotations against ground truth or reference annotations |
Using these metrics and methods, you can accurately measure your data annotations. Regular quality checks help pinpoint areas for improvement, ensure data reliability, and aid in developing more precise machine learning models.
Best Practices for Ensuring Data Annotation Quality
To achieve top-tier data annotation quality, it's vital to adhere to industry standards and implement thorough quality checks. These steps are crucial for enhancing the precision and dependability of your annotated datasets. This, in turn, boosts the performance of your machine learning models.
Hiring Experienced Annotators
Choosing skilled annotators is key to superior data annotation. These experts are adept at following annotation guidelines and possess the knowledge to label data accurately. Their proficiency ensures precise and consistent outputs, minimizing the need for extensive revisions.
Providing Comprehensive Training
Extensive training is vital for annotator quality. Annotators should be thoroughly schooled in annotation protocols, domain-specific knowledge, and quality benchmarks. This training equips them with the skills for precise data labeling and consistent project execution. Regular updates through refresher training keep them abreast of guideline changes and best practices.
Implementing Automated and Manual Quality Checks
Combining automated and manual quality checks is pivotal for pinpointing errors and refining annotation precision. Automated systems swiftly detect common mistakes like missing labels or inconsistencies. Manual reviews offer a deeper examination of the annotated data. This dual approach, supported by spot checks and error tracking, sustains data quality throughout the project.
| Quality Check Type | Description |
|---|---|
| Automated Validation Rules | Predefined rules to identify common errors and inconsistencies |
| Spot Checking | Random sampling of annotated data for manual review |
| Error Tracking Systems | Tools to monitor and track annotation errors over time |
Defining High-Quality Deliverables
Clearly defining high-quality deliverables is essential for ensuring annotators comprehend the expected standards. This includes setting accuracy thresholds, error rate limits, and other quality metrics. Clear goals and effective communication help annotators focus on delivering superior results.
Considering Project Length and Budget
When planning an annotation project, it's crucial to consider both the timeline and budget. Allocating adequate time and resources for quality assurance, including training and revisions, ensures the final output meets quality benchmarks. Finding a balance between cost and quality is vital for the best outcomes within budget constraints.
Establishing Golden Standards
Creating golden standards, or perfectly annotated examples, acts as a benchmark for annotators. These standards aid in maintaining consistency across the project. They are useful for training, quality evaluation, and benchmarking. Clear examples of exemplary annotations guide annotators towards achieving similar standards.
Partnering with Reputable Data Annotation Providers
Collaborating with established data annotation providers ensures high-quality outputs. These partners bring the necessary expertise, resources, and experience for accurate and dependable datasets. When selecting a provider, evaluate their track record, quality assurance processes, and ability to fulfill your project needs.
data annotation providers model performance
Consequences of Poor Data Annotation Quality
Data annotation quality is crucial for the performance and reliability of machine learning models. Poor annotation can lead to numerous negative outcomes, undermining AI solution development efforts. Small AI startups are especially at risk due to limited resources and the need to optimize their investments.
Inaccurate Predictions
Poor annotation quality results in inaccurate predictions from trained models. Models learn from incorrect patterns in the data, leading to flawed outputs. For instance, Zillow's home-buying algorithm made overpayments due to inaccurate data, causing significant financial losses.
Low Model Performance
Models trained on poor data perform suboptimally. Even a small amount of incorrect data can hinder the model's learning and generalization. Improving data annotation is essential for models to reach their full potential and deliver reliable results. High-quality annotation processes can significantly boost model performance and reduce the risk of costly failures.
Misleading Insights
Inaccurate annotations lead to misleading insights from model outputs. These insights can guide poor decisions, potentially harming the organization's goals. For example, the COMPAS algorithm, used in criminal justice, showed racial bias due to inaccurate data, leading to unfair sentencing recommendations. Ensuring accurate annotations is vital to avoid such outcomes and maintain trust in AI-driven insights.
Resource Waste
Training models on poor data is a significant waste of resources. The time, effort, and computational resources spent on flawed data could be better used elsewhere in AI development. Moreover, retraining models due to inaccurate annotations adds to the waste. Effective data annotation strategies from the start can optimize resource allocation and accelerate reliable AI development.
| Consequence | Impact |
|---|---|
| Inaccurate Predictions | Flawed model outputs leading to incorrect decisions |
| Low Model Performance | Suboptimal results and unreliable predictions |
| Misleading Insights | Ill-informed decision-making based on inaccurate data |
| Resource Waste | Inefficient utilization of time, effort, and computational resources |
To avoid these issues, organizations must focus on data annotation quality and establish strong processes for accurate labeling. Regularly assessing model performance and auditing annotations can help evaluate data quality and pinpoint areas for improvement. By investing in high-quality annotation, businesses can unlock AI's true potential and drive sustainable growth in the evolving AI landscape.

Automated Data Annotation: Pros and Cons
Automated data annotation has transformed the way we label data for machine learning projects. It uses artificial intelligence and machine learning to annotate datasets efficiently and cost-effectively. This technology has its pros and cons, affecting businesses in various ways.
Speed and Scalability
Automated data annotation's key advantage is its speed and scalability. It can process vast amounts of data much faster than manual methods. This is crucial for industries like autonomous vehicles or e-commerce, which handle enormous datasets.
Studies show automated data labeling is scalable and efficient for large projects. Gartner forecasts a 30% reduction in operational costs through hyper-automation and process optimization.
Cost-Effectiveness
Automated data annotation is also cost-effective. It reduces the need for manual labor, cutting down on hiring and training costs. Additionally, it minimizes the risk of human error, which can be costly to fix.
The data labeling market was over $1 billion in 2020 and is growing at over 30% annually until 2027. This growth highlights the demand for cost-effective solutions to meet the increasing need for annotated data.
Consistency
Automated data annotation ensures consistent labeling across datasets. Machine learning algorithms apply uniform criteria, unlike human annotators who may vary. This consistency is vital for training accurate AI models.
Techniques like programmatic labeling and transfer learning enhance data annotation consistency. These methods help businesses label data accurately and consistently, leading to better AI model performance.
Limitations
Automated data annotation has its limitations. It may struggle with tasks requiring a deep understanding of context or nuanced data. In such cases, human input is necessary for accuracy.
Another challenge is that automated labeling can become outdated or flawed over time. As data patterns change, systems need updates to maintain accuracy. Neglecting these updates can lead to poor model performance.
| Pros | Cons |
|---|---|
| High speed and scalability | Difficulty with context-specific tasks |
| Cost-effectiveness | Potential for obsolescence or flaws over time |
| Consistency in labeling | Need for periodic updates and fine-tuning |
Automated data annotation offers significant benefits like speed, scalability, cost-effectiveness, and consistency. Yet, it's crucial to recognize its limitations. A balanced approach combining automated and manual methods ensures the highest quality data for machine learning projects.
Optimal Scenarios for Automated Annotation
Automated annotation excels in scenarios where speed and handling large datasets are crucial. These systems swiftly analyze vast datasets, proving invaluable in e-commerce for tasks like basic image recognition. Automation boosts efficiency and overcomes manual data challenges.
In time-sensitive projects, in-house labeling can be economical over time. Yet, it depends on the company's human resources. Crowdsourced labeling offers speed but may introduce data inconsistencies due to varied effort and expertise. Outsourced labeling uses experts for quick, high-quality results, though it's pricier.
Automated labeling enhances efficiency but needs close supervision to avoid errors. Quality control, through regular checks and audits, is vital for maintaining standards and accuracy. Creating a strategic annotation framework that matches machine learning goals streamlines tagging and improves data quality.
For optimal automated annotation workflows, consider these best practices:
- Combine automated annotation with human expertise to efficiently manage large datasets while maintaining high annotation quality.
- Use tools like Keylabs which offers ML-assisted annotation and automated labeling features.
- Provide comprehensive training to your annotation team on procedures, tools, and maintaining high-quality annotations.
- Implement multi-modal annotation, including images, text, audio, and video within a single dataset, to enhance model performance by providing comprehensive multi-contextual data insights.
By 2027, the data annotation market is projected to reach $6.45 billion, highlighting the growing importance of accurate and efficient data labeling across various industries.
Automated annotation is crucial in industries with high-frequency data updates. For example, autonomous vehicles need daily dataset refreshes for better navigation and safety. Healthcare relies on monthly updates for improved diagnostics and patient care. Finance requires high-frequency labeling accuracy for fraud detection and risk management.
The choice between in-house, crowdsourced, and outsourced labeling depends on project length, budget, and expertise needed. By evaluating these factors and applying best practices, organizations can leverage automated annotation to gain valuable insights from their data and drive innovation across various domains. Mastering data annotation is key for success in the AI and machine learning era.
Balancing Manual and Automated Annotation for Optimal Results
In the realm of data annotation, achieving the right balance between manual and automated methods is key. Manual annotation ensures accuracy and precision but is time-consuming and costly. Automated annotation, on the other hand, offers speed and cost savings but might miss the contextual depth that human annotators provide.
Many organizations are adopting a hybrid approach that combines the strengths of both methods. This hybrid strategy allows for efficient annotation while preserving precision. It's about leveraging the best of manual and automated annotation to enhance efficiency and maintain precision.
| Annotation Method | Advantages | Disadvantages |
|---|---|---|
| Manual Annotation |
|
|
| Automated Annotation |
|
|
When adopting a hybrid annotation strategy, it's crucial to evaluate your project's specific needs. Tasks that demand complex decision-making or a deep contextual grasp are ideal for manual annotation. Conversely, tasks that require speed and efficiency are well-suited for automated tools.
"The key to successful data annotation lies in finding the right balance between manual and automated methods. By leveraging the strengths of each approach, organizations can optimize their annotation workflows and achieve the best possible results."
Embarking on your data annotation journey, aim to create datasets that enable your AI models to excel. Balancing annotation methods and ensuring data quality is essential. This approach unlocks the full potential of machine learning, driving innovation within your organization.
Emerging Trends in Data Annotation
The demand for precise and dependable training data is on the rise, pushing the field of data annotation into new territories. This shift is driven by the imperative to refine the annotation process, cut costs, and enhance the caliber of annotated data. We will delve into three pivotal trends in data annotation: augmented annotation, active learning, and transfer learning.
Augmented Annotation
Augmented annotation is revolutionizing the field by melding human expertise with machine learning algorithms. This synergy enhances the annotation process, making it more efficient and accurate. AI tools play a crucial role in this approach, streamlining the labeling process while maintaining high standards.
This method is particularly beneficial for large-scale projects, where manual annotation would be impractical due to its time and cost implications.
Active Learning
Active learning is a trend that focuses on selecting the most informative data points for annotation. It does this by identifying examples that will most improve the model's performance. This approach is essential in scenarios where annotated data is scarce or costly.
Active learning algorithms delve into the data's underlying patterns, selecting samples that are most likely to enhance the model. This enables faster model convergence and reduces the annotation effort required. It's gaining momentum in domains like natural language processing, computer vision, and speech recognition.
Transfer Learning
Transfer learning leverages pre-trained models to enhance annotation efficiency and accuracy in new domains or tasks. It adapts knowledge from one domain to another, reducing the need for extensive annotated data in the target domain. This technique is invaluable in complex or specialized domains with limited annotated data.
By fine-tuning pre-trained models on a smaller set of domain-specific data, transfer learning accelerates the annotation process and elevates the quality of the models produced. This approach is particularly beneficial in leveraging the vast annotated data available in established domains like ImageNet for computer vision or Wikipedia for natural language processing.
| Trend | Key Benefits | Applications |
|---|---|---|
| Augmented Annotation | Improved efficiency and accuracy, reduced annotation time and cost | Large-scale projects, diverse annotation tools and platforms |
| Active Learning | Optimized data selection, reduced annotation effort, faster model convergence | Scenarios with limited annotated data, various domains (NLP, computer vision, speech recognition) |
| Transfer Learning | Leveraging pre-trained models, improved efficiency and accuracy, reduced need for extensive annotated data | Complex or specialized domains with limited annotated data |
As organizations recognize the pivotal role of data annotation in developing accurate AI models, these trends are set to redefine the industry's future.
Reliability of Automatic Annotation
The reliability of automatic annotation is a parameter to watch. As automated systems become more prevalent in text analysis and data processing, understanding their reliability is crucial. It's vital to know what affects their performance and how to make them better.
Factors Influencing Automatic Annotation Reliability
Several factors affect the reliability of automatic annotation systems, including:
- Quality and diversity of training data
- Complexity of the annotation task
- Robustness of machine learning algorithms
- Presence of bias in the data or algorithms
- Level of human oversight and intervention
A study by Volodina et al. showed that two Dutch parsers' performance decreased by 7-8% on L2 learner data compared to L1 data. This highlights the importance of high-quality and diverse training data for accurate annotation.
Strategies for Improving Automatic Annotation Reliability
To make automatic annotation systems more reliable, organizations can try different strategies, such as:
- Implementing human-in-the-loop approaches for quality control
- Continuously monitoring and evaluating system performance
- Applying bias mitigation techniques to reduce systematic errors
- Ensuring annotation consistency through standardized guidelines and training
- Leveraging transfer learning to improve performance on new tasks or domains
In the study by Geri et al., Assess 2.0's sensitivity was between 68.2% and 94.4%, and specificity was between 63.8% and 97.3%. However, the system needed human verification for at least one event in 55.2% of oocytes. This shows the importance of human oversight in ensuring accurate annotations
Busing these strategies and refining automatic annotation systems, organizations can enhance the reliability of their text analysis and data processing. This leads to more accurate insights and better decision-making.
Summary
Automatic annotation is crucial for the development of accurate and reliable machine learning models. As AI evolves, the need for dependable automatic annotation will increase. By grasping the importance of data annotation, assessing annotation accuracy, and balancing manual and automated methods, organizations can refine their annotation processes. This leads to superior results. The ImageNet dataset, a leading dataset in machine learning, contains 3.2 million images across 5,247 categories, illustrating the complexity of modern datasets.
New trends like augmented annotation, active learning, and transfer learning promise to enhance automatic annotation efficiency and effectiveness. Automated annotation cuts down annotation time to mere seconds, significantly speeding up the process. AI-driven annotation ensures uniform labeling, reducing human error and boosting model performance. Yet, ensuring the accuracy of automated annotations necessitates strong quality assurance and human oversight to rectify mistakes and validate outcomes.
Creating AI models for automated annotation requires meticulous training, tuning, and optimization to manage diverse data and labeling needs effectively. Automated annotation scales well for large datasets and evolving project demands, fitting both small-scale experiments and large-scale applications. Yet, tasks like fine-grained segmentation or keypoint labeling might need specialized algorithms and expertise for best results. By harnessing the power of automated annotation, organizations can boost their computer vision capabilities and spur innovation in AI development. As the need for high-quality training data grows, investing in reliable automatic annotation solutions will be vital for staying competitive in the fast-paced AI landscape.
FAQ
What is the importance of data annotation in machine learning?
Data annotation is vital for machine learning as it educates models for better accuracy. It's crucial to maintain data quality to ensure AI models develop effectively. Poor-quality datasets can result in less accurate results.
How can data annotation accuracy be measured?
Metrics like Cohen's kappa, Fleiss' kappa, Krippendorf's alpha, and F1 score assess data annotation accuracy. These metrics evaluate the reliability and consistency of annotations. This is essential for creating precise AI models.
What are the best practices for ensuring data annotation quality?
Ensuring high-quality data annotation involves hiring skilled annotators and providing thorough training. It also includes implementing automated and manual quality checks, defining clear standards, and considering project scope and budget. Partnering with reputable data annotation providers is also beneficial.
What are the consequences of poor data annotation quality?
Poor data annotation quality can lead to inaccurate predictions and low model performance. It may also result in misleading insights and waste resources. These issues significantly affect the reliability and effectiveness of AI models.
When is manual data annotation most beneficial?
Manual data annotation is most beneficial for tasks needing deep context and nuance. Examples include sentiment analysis, medical diagnosis, and legal document analysis. Human annotators are superior at capturing subtle details and cultural nuances in these areas.
What are the advantages of automated data annotation?
Automated data annotation offers speed, scalability, and cost-effectiveness. It ensures consistent labeling of large datasets, significantly reducing manual labeling times and maintaining uniformity in the process.
How can organizations balance manual and automated annotation for optimal results?
The best approach combines manual and automated methods. This hybrid strategy leverages the strengths of both for superior accuracy and efficiency. It allows for automated speed and scalability while retaining human annotators' precision and contextual understanding.
What are some emerging trends in data annotation?
Emerging trends include augmented annotation, active learning, and transfer learning. These methods aim to enhance annotation efficiency, reduce training data needs, and adapt knowledge from one domain to another using pre-trained models.
What factors influence the reliability of automatic annotation?
The reliability of automatic annotation hinges on factors such as training data quality, task complexity, and algorithm robustness. Improving training data quality and using human-in-the-loop approaches, bias mitigation, and consistency checks can enhance automatic annotation reliability.