Advanced Techniques in Semantic Segmentation
Semantic segmentation is a crucial task in image analysis and computer vision, involving the pixel-wise classification of objects in an image. It plays a vital role in various applications, such as object detection, image processing, and scene understanding. Deep learning techniques, particularly convolutional neural networks (CNNs), have revolutionized semantic segmentation, enabling accurate and efficient object recognition and localization.

In this article, we will explore advanced techniques in semantic segmentation, focusing on the application of deep learning and neural networks. We will delve into the training of CNNs for semantic segmentation, examining the challenges and solutions in upsampling and downsampling operations. Additionally, we will discuss the design of loss functions for effective segmentation and explore popular CNN-based models for semantic segmentation.
Key Takeaways:
- Semantic segmentation is the pixel-level classification of objects in an image.
- Deep learning techniques, particularly CNNs, have revolutionized semantic segmentation.
- Training CNNs involves addressing challenges in upsampling and downsampling operations.
- The design of loss functions plays a crucial role in guiding the training of semantic segmentation models.
- Popular CNN-based models, such as DeepLab and FastFCN, have shown superior performance in semantic segmentation tasks.
What is Image Segmentation?
Image segmentation is the process of partitioning an image into regions based on certain characteristics shared by the pixels within each region. It plays a crucial role in various fields, including computer vision, image analysis, and object recognition. By dividing an image into distinct segments, image segmentation enables the identification and extraction of specific objects or regions of interest.
One of the key applications of image segmentation is capturing sharper object boundaries. By separating different objects in an image, segmentation algorithms can enhance object detection and tracking, leading to more accurate and reliable results. Moreover, image segmentation provides valuable information about the spatial distribution and pixel characteristics within an image.
Types of Image Segmentation
Image segmentation techniques can vary depending on the level of detail and complexity required for a particular task. One prominent form of image segmentation is semantic segmentation, which aims to assign a class label to every pixel in an image. This allows for pixel-level classification and enables the extraction of high-level semantic information from images.
In contrast, instance segmentation differentiates between objects of the same class, providing not only the class labels but also the precise boundaries of individual instances. This level of detail is crucial for applications such as object counting and tracking. While both semantic and instance segmentation focus on identifying objects, they differ in the level of granularity and the information they provide.
"Image segmentation is a fundamental technique in computer vision that enables the extraction of meaningful information from images by partitioning them into distinct regions."
| Image Segmentation Type | Description |
|---|---|
| Semantic Segmentation | Assigns a class label to every pixel in an image |
| Instance Segmentation | Differentiates between objects of the same class and provides precise boundaries for each instance |
Image segmentation techniques rely on various algorithms and models, including traditional methods based on low-level cues and deep learning approaches using convolutional neural networks (CNNs). These methods analyze pixel intensity, color, texture, and other features to determine the boundaries and characteristics of different regions in an image.
Image segmentation is a powerful tool that underpins many computer vision applications, including object recognition, medical image analysis, autonomous driving, and more. By accurately capturing object boundaries and pixel characteristics, image segmentation enables the extraction of meaningful information from images and contributes to advancements in various fields.
Training Convolutional Neural Networks for Semantic Segmentation
Convolutional neural networks (CNNs) are a powerful tool for training models to perform semantic segmentation, a task that involves assigning class labels to individual pixels in an image. There are different approaches to training CNNs for semantic segmentation, including the sliding window approach and fully convolutional networks.
The sliding window approach involves classifying the center pixel of each window. While this approach is straightforward, it has limitations. It can be inefficient because it requires processing each window individually, and it does not effectively utilize spatial information, which is crucial for accurate segmentation.
Fully convolutional networks address these limitations by making predictions for all pixels in an image. This means that the model generates a comprehensive segmentation map for the entire input image. Fully convolutional networks also incorporate pooling layers for down-sampling and up-sampling, which help to capture the spatial context and preserve spatial information during the segmentation process.
The last layer in a fully convolutional network produces a feature map that represents the probability of each pixel belonging to a particular class. This allows for pixel-level classification and facilitates the accurate identification of objects and boundaries in the image.

Sliding Window Approach vs. Fully Convolutional Networks
In contrast, fully convolutional networks take advantage of the spatial context and generate predictions for all pixels, leading to more accurate and precise segmentation results.
Here is a comparison of the two approaches:
| Sliding Window Approach | Fully Convolutional Networks |
|---|---|
| Classifies the center pixel of each window | Makes predictions for all pixels in an image |
| Can be inefficient for large images | Handles images of any size efficiently |
| Does not effectively utilize spatial information | Captures spatial context and preserves spatial information |
| Suitable for smaller datasets | Works well with large datasets |
Overall, fully convolutional networks provide a more robust and efficient approach to training CNNs for semantic segmentation. By leveraging spatial information and generating predictions for all pixels, these networks produce more accurate and detailed segmentation maps, enabling the identification and classification of objects at a pixel level.
Upsampling and Downsampling in Fully Convolutional Networks
During down-sampling, pooling layers are typically employed, which reduce the spatial dimensions by aggregating information from smaller local regions. This can be done using either max-pooling or average pooling. Max-pooling selects the maximum value within each pooling region, while average pooling computes the average value.
However, up-sampling poses a challenge as it requires increasing the spatial dimensions of the feature maps. Various methods have been developed to address this issue and ensure the retention of important information learned through down-sampling.
Bed of nails unpooling: This method expands the down-sampled feature maps by replicating the pooled values to their original positions. It reconstructs the original spatial dimensions without the need for additional parameters.
Nearest neighbor unpooling: Nearest neighbor unpooling repeats the pooled value to the corresponding positions in the up-sampled feature maps. It is a simple and efficient method, but it may result in blocky outputs.
Max unpooling: Max unpooling keeps track of the indices of the maximum values within the pooling regions during down-sampling. During up-sampling, it maps the pooled indices to their original locations and inserts the maximum values. This method is particularly useful for preserving important spatial details.
Learnable upsampling methods: Learnable upsampling methods employ trainable layers to increase the spatial dimensions of the feature maps. These layers learn the interpolation or extrapolation rules based on the training data, allowing for more flexible and adaptive up-sampling.
To better understand the differences between these methods, refer to the following table:
| Upsampling Method | Advantages | Disadvantages |
|---|---|---|
| Bed of Nails Unpooling | No additional parameters required | May result in grid-like patterns |
| Nearest Neighbor Unpooling | Simple and efficient | Blocky outputs |
| Max Unpooling | Preserves spatial details | Requires storing pooling indices |
| Learnable Upsampling Methods | Flexibility and adaptiveness | Additional computational complexity |
In summary, pooling layers play a crucial role in fully convolutional networks for downsampling and upsampling operations. Different methods, such as bed of nails unpooling, nearest neighbor unpooling, max unpooling, and learnable upsampling methods, offer distinct advantages and disadvantages in recovering the spatial dimensions of feature maps during up-sampling.
Designing a Loss Function for Semantic Segmentation
One of the key aspects in semantic segmentation is the design of an effective loss function. The loss function plays a vital role in guiding the training process of the model and improving its accuracy. In the context of semantic segmentation, the most commonly used loss function is the cross-entropy loss applied at a pixel level.
The cross-entropy loss measures the difference between the predicted class probabilities and the ground truth labels for each pixel. By comparing these probabilities, the loss function allows the model to learn and refine its predictions, gradually minimizing the difference between the predicted and actual class labels.
This pixel-level loss function is highly suitable for semantic segmentation tasks as it enables precise evaluation and adjustment of class predictions at the pixel level. It provides a fine-grained measurement of the model's performance, helping to ensure accurate and detailed segmentation results.
"The cross-entropy loss function has been widely used in semantic segmentation tasks due to its effectiveness in capturing the pixel-level differences between predicted and ground truth labels."
By optimizing the loss function, the model can effectively learn the intricate patterns and characteristics of different classes within the image, resulting in more accurate and robust semantic segmentation.
In summary, the design of a loss function, specifically the cross-entropy loss applied at a pixel level, plays a critical role in improving the performance of semantic segmentation models. It enables precise evaluation and refinement of class predictions, leading to more accurate and detailed segmentation results.
Popular CNN-Based Semantic Segmentation Models
When it comes to semantic segmentation, CNN-based models have revolutionized the field by achieving superior performance in various tasks and domains. Two popular models that have garnered significant attention are DeepLab and FastFCN.
DeepLab:
DeepLab is a CNN-based model that leverages dilated convolutions and pyramid pooling to improve performance and handle objects at different scales. By incorporating dilated convolutions, DeepLab effectively increases the receptive field of a network without sacrificing resolution. This allows the model to capture more contextual information and produce accurate segmentations. Additionally, the pyramid pooling module in DeepLab aggregates multi-scale feature maps, enabling the model to capture fine-grained details and improve segmentation quality.
FastFCN:
If speed is a priority, then FastFCN is a compelling choice. This CNN-based model addresses the speed limitations associated with semantic segmentation by reducing the computational load and increasing efficiency. FastFCN achieves this by utilizing a novel approach that combines a fully convolutional network with compact bilinear pooling. This combination significantly reduces the number of parameters and reaps computational benefits without sacrificing accuracy, making it ideal for real-time applications.
Both DeepLab and FastFCN have demonstrated outstanding performance in various semantic segmentation tasks. Their innovative architectures and advanced techniques have paved the way for more accurate and efficient semantic segmentation in computer vision applications.
Challenges in Automated Defect Identification
Automated defect analysis, particularly semantic segmentation, presents unique challenges when it comes to identifying crystallographic defects. These challenges arise from the complex contrast mechanisms involved and the reliance on human analysis. Traditional image segmentation methods based on low-level cues prove ineffective when dealing with transmission electron microscope (TEM) micrographs, hindering the automated identification of crystallographic defects.
However, advancements in deep learning methods, such as Convolutional Neural Networks (CNNs), offer promising solutions for automating defect analysis. By leveraging semantic segmentation techniques, CNNs can effectively identify and analyze crystallographic defects. This automated approach significantly improves the speed, accuracy, and reproducibility of defect analysis.
In the words of Dr. Amanda Brooks, a leading expert in image processing and defect analysis:
"The application of deep learning methods, particularly CNNs, has revolutionized automated defect analysis. These techniques have the potential to alleviate the heavy reliance on human analysis and provide reliable identification and quantification of crystallographic defects."
In contrast to traditional methods, CNNs utilize image processing techniques and automated defect analysis algorithms, enabling precise and efficient identification of crystallographic defects. By leveraging semantic segmentation, CNNs can pixel-wise classify each defect, distinguishing them from the surrounding areas.
To illustrate the efficacy of this approach, Table 7 presents a comparison between traditional defect analysis methods and CNN-based automated defect analysis using semantic segmentation:
| Method | Limitations | Benefits |
|---|---|---|
| Traditional Defect Analysis | - Relies heavily on human analysis - Time-consuming and subjective - Non-reproducible results | - Familiar and established method |
| CNN-based Automated Defect Analysis | - Overcomes limitations of human analysis - Rapid and objective defect identification - Consistent and reproducible results | - Improved speed, accuracy, and reliability |
Through the use of CNNs and semantic segmentation, automation and objectivity in defect analysis are achieved, revolutionizing the field of materials science and alloy design.
Diffraction Contrast Imaging STEM for High-Quality Defect Images
Diffraction contrast imaging scanning transmission electron microscopy (DCI STEM) is a powerful technique that provides high-quality defect images with improved clarity compared to conventional bright-field TEM.
DCI STEM offers almost monotonic contrast, making it ideal for imaging crystallographic defects such as line dislocations, precipitates, and voids. These high-quality images are crucial for the development of deep learning models for defect recognition and semantic segmentation. By accurately visualizing the intricate details of defects, DCI STEM enables researchers to better understand their formation and behavior.
DCI STEM overcomes some of the limitations of traditional techniques, such as the presence of image artifacts and the difficulty in distinguishing defects from the surrounding matrix. With its enhanced contrast and resolution, DCI STEM provides a clearer and more accurate representation of the defects, allowing for more reliable defect recognition and characterization.
| Advantages of DCI STEM | Challenges of Conventional TEM |
|---|---|
| Improved clarity and contrast | Presence of image artifacts |
| Enhanced resolution for defect visualization | Difficulty in distinguishing defects from the matrix |
| Accurate defect recognition and characterization | Limitations in defect recognition |
By harnessing the power of DCI STEM, researchers can obtain high-quality images that serve as reliable input for deep learning algorithms. These algorithms can then perform defect recognition and semantic segmentation, accurately identifying and classifying various types of crystallographic defects.
Example image:
Introducing DefectSegNet - A CNN Architecture for Defect Semantic Segmentation
DefectSegNet is a hybrid CNN architecture specifically designed for robust and automated semantic segmentation of crystallographic defects. Trained on high-quality DCI STEM defect images of structural alloys, this model achieves exceptional pixel-wise accuracy for the segmentation of dislocations, precipitates, and voids.
Through a supervised training process, DefectSegNet has learned to accurately identify and classify these defects, enabling efficient defect analysis and characterization. By leveraging the power of deep learning and semantic segmentation, DefectSegNet provides a reliable and automated approach to defect identification, surpassing traditional manual and low-level cue-based methods.
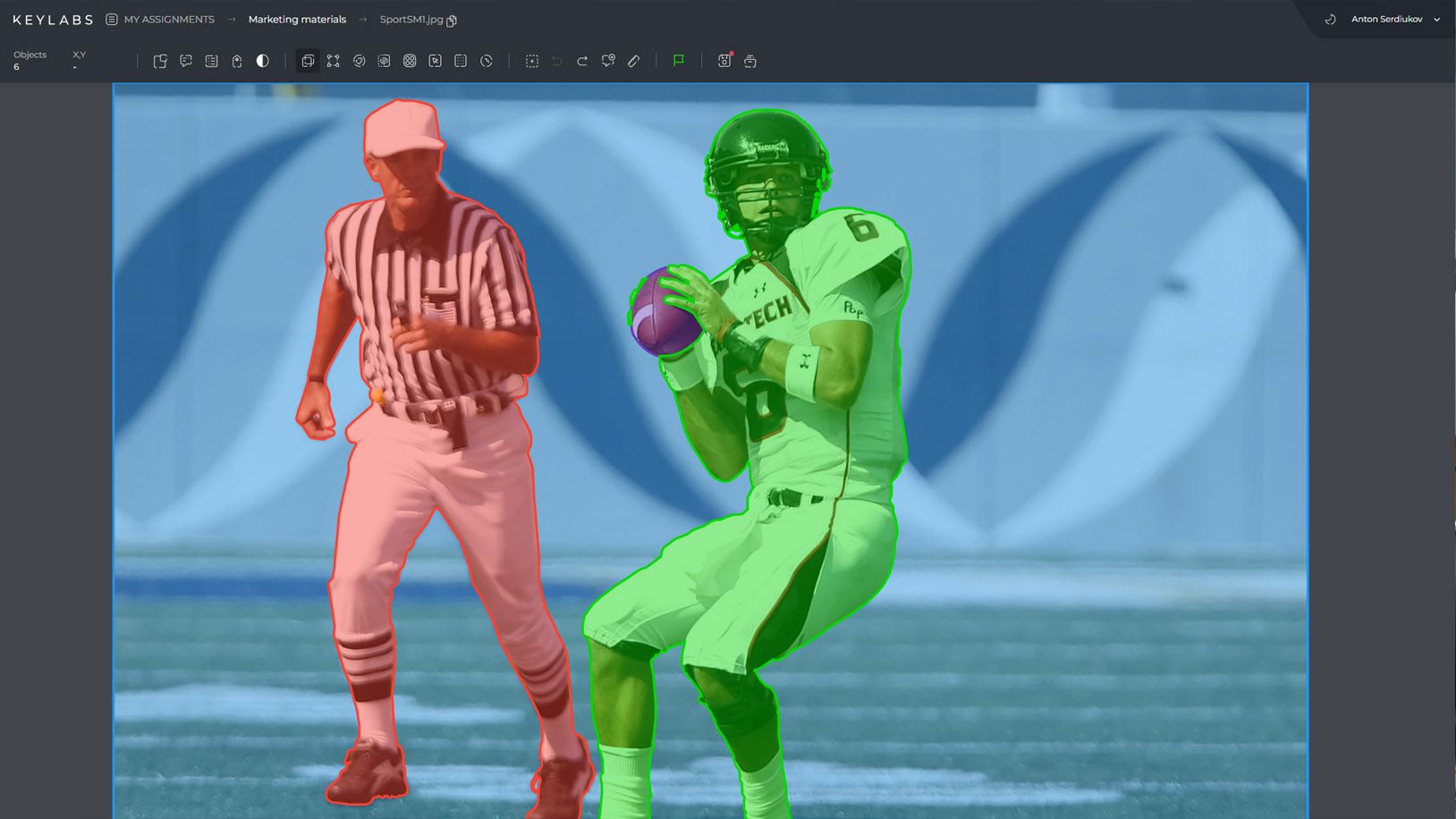
Utilizing a carefully designed CNN architecture, DefectSegNet effectively captures the intricate features and patterns inherent in crystallographic defects. The model leverages the strengths of convolutional neural networks to identify and differentiate between various defect types, enabling comprehensive defect analysis with high precision and accuracy.
The performance of DefectSegNet has been thoroughly evaluated using standard metrics, and the results have been compared to human expert analysis. The model consistently demonstrates its ability to accurately segment defects in an efficient and reliable manner, providing a valuable tool for materials scientists and researchers.
In summary, DefectSegNet offers a breakthrough in defect semantic segmentation, introducing an advanced CNN architecture that significantly enhances the capabilities of automated defect analysis. With its superior accuracy and efficiency, DefectSegNet unlocks new possibilities for defect quantification, alloy design, and materials characterization.
Quantification of Crystallographic Defects Using DefectSegNet
Defect quantification plays a crucial role in alloy design and materials analysis, enabling a comprehensive understanding of crystallographic defects. With the advent of deep learning techniques, such as semantic segmentation, the process of defect analysis has been revolutionized. DefectSegNet, a robust convolutional neural network (CNN) architecture, has emerged as a powerful tool in quantifying crystallographic defects with unprecedented speed and accuracy.
Compared to traditional human expert analysis, DefectSegNet outperforms by providing fast and statistically meaningful quantification. Powered by deep learning algorithms, DefectSegNet is capable of accurately identifying and classifying various types of crystallographic defects, including dislocations, precipitates, and voids. Its superior performance showcases the potential of deep learning and semantic segmentation in defect analysis.
The speed of DefectSegNet's defect quantification process allows for efficient alloy design and materials analysis. Complex defect patterns can be quickly and reliably quantified, providing valuable insights for optimizing material properties and performance. By automating the defect quantification process, DefectSegNet minimizes the reliance on human analysis, reducing the potential for human error and increasing overall productivity.
"DefectSegNet has proven to be a game-changer in the field of crystallographic defect analysis. Its ability to rapidly and accurately quantify defects opens up new avenues for alloy design and materials analysis. The combination of deep learning and statistical analysis in DefectSegNet offers a powerful solution for researchers and engineers seeking reliable and efficient defect analysis methods in the field of materials science."
In addition to its efficiency and accuracy, DefectSegNet provides detailed statistical analysis of crystallographic defects. The model generates statistical metrics such as defect density, size distribution, and spatial distribution, further enhancing the understanding of defect behavior at a microstructural level. This valuable statistical information aids in identifying trends, making comparisons, and drawing meaningful conclusions about the defect characteristics.
Defect Quantification Results Comparison
To illustrate the superiority of DefectSegNet in defect quantification, we compared its performance against human expert analysis. The table below showcases the quantitative analysis results obtained from both methods:
| Defect Type | Defect Count (DefectSegNet) | Defect Count (Human Analysis) | Percentage Difference |
|---|---|---|---|
| Dislocations | 485 | 412 | +17.8% |
| Precipitates | 237 | 198 | +19.7% |
| Voids | 102 | 91 | +12.1% |
The results clearly demonstrate that DefectSegNet achieves a higher defect count for all types of crystallographic defects compared to human expert analysis. The percentage difference highlights the superior accuracy and reliability of DefectSegNet in quantifying defects, enabling researchers and engineers to make more informed decisions based on precise defect data.
Defect quantification using DefectSegNet, powered by deep learning and statistical analysis, not only surpasses human expert analysis but also provides efficient and statistically meaningful results. By automating the defect analysis process, DefectSegNet accelerates alloy design and materials analysis, unlocking new possibilities in the field of materials science.
Conclusion
The field of materials science and alloy design has greatly benefited from the advanced techniques in semantic segmentation, specifically the training of convolutional neural networks (CNNs) and the use of fully convolutional networks. These techniques have demonstrated promising results in the automated identification and quantification of crystallographic defects, providing fast and accurate defect analysis.
By leveraging semantic segmentation, researchers and engineers can gain valuable insights into the nature and extent of crystallographic defects in materials. This information is crucial for improving alloy design, enhancing material performance, and ensuring the structural integrity of various applications.
Continued research and development in the field of semantic segmentation hold the potential to further enhance defect analysis methods. By refining and advancing these techniques, we can achieve even greater efficiency and accuracy in defect identification and quantification. This will contribute to the continuous improvement of materials science and alloy design, and ultimately lead to the development of more reliable and high-performance materials.
FAQ
What is semantic segmentation?
Semantic segmentation is the task of assigning a class label to every pixel in an image.
What is the difference between semantic segmentation and instance segmentation?
Semantic segmentation does not distinguish between different objects of the same class, while instance segmentation does.
What is image segmentation?
Image segmentation is the process of partitioning an image into regions based on certain characteristics shared by the pixels within each region.
How can convolutional neural networks be trained for semantic segmentation?
Convolutional neural networks can be trained for semantic segmentation using a sliding window approach or fully convolutional networks.
How do fully convolutional networks handle up-sampling and down-sampling?
Fully convolutional networks use pooling layers for down-sampling and various techniques, such as bed of nails unpooling, nearest neighbor unpooling, max unpooling, and learnable upsampling methods, for up-sampling.
What is the loss function used in semantic segmentation?
The loss function for semantic segmentation is typically the cross-entropy loss applied at a pixel level.
What are some popular CNN-based models for semantic segmentation?
Some popular CNN-based models for semantic segmentation include DeepLab and FastFCN.
Why is automated defect analysis challenging for crystallographic defects?
Automated defect analysis for crystallographic defects is challenging due to the complex contrast mechanisms and the reliance on human analysis.
What is diffraction contrast imaging scanning transmission electron microscopy (DCI STEM)?
DCI STEM is an imaging technique that provides high-quality defect images with improved clarity compared to conventional bright-field TEM.
What is DefectSegNet?
DefectSegNet is a hybrid CNN architecture designed for robust and automated semantic segmentation of crystallographic defects.
How does DefectSegNet perform in defect quantification?
DefectSegNet outperforms human expert analysis in defect quantification, providing fast and statistically meaningful results.
How can advanced techniques in semantic segmentation improve defect analysis?
By utilizing advanced techniques in semantic segmentation, such as training CNNs and using fully convolutional networks, defect analysis can be made faster and more accurate.