API-First Annotation Solutions for ML Pipelines
Modern algorithms for text transformers and neural networks for computer vision require a large amount of correctly labeled data, and with poor-quality labeling, the model will work inaccurately.
With the growth of data volumes and the variety of their formats, traditional manual approaches to labeling become too slow and time-consuming. The method of integrating the labeling process directly into ML pipelines enables to automate tasks, scale the process more efficiently, and maintain the quality and repeatability of results.
For large projects where data is constantly updated and models are regularly retrained. Integrating labeling into the pipeline helps build a single process where training, testing, and adaptation save time and provide accurate results for training models.
Key Takeaways
- Real-time data synchronization prevents version conflicts in active learning.
- Automated quality protocols maintain consistency across large datasets.
- Scalable solutions adapt to fluctuating project demands seamlessly.
- Strategic implementation requires alignment with existing ML infrastructure.

Why API-First Approaches Matter in AI and ML
Pipeline integration enables markup to be run programmatically via annotation APIs, eliminating the need to click on buttons in the web interface manually. This is especially useful for large projects with substantial amounts of data, where mass quality control, large-scale markup, and control of results are crucial. Programmatic annotation, also known as hybrid mode, enables the first to submit data via API-driven annotation, obtain preliminary markup using scripts or models, and only pass those cases to a human where the model is not confident. This saves time and resources.
Quality control and repeatability are ensured by the fact that the entire process is managed via annotation APIs. This allows it to easily implement checks, data versioning, logging, and re-queries. Flexibility in tasks is demonstrated by the fact that integration API-first solutions standardize work for various types of data, including text, images, video, and 3D content.
Scaling and adaptation enable the processing of tens of thousands or millions of markups quickly and efficiently, thanks to automated workflows and API integration, making the process fully integrated into ML pipelines.
Overview of Annotation and Its Impact on Model Performance
Modern ML pipelines rely on structured and programmatically accessible annotation processes. Using annotation APIs and API-driven annotation allows teams to incorporate labeling directly into ML pipelines, making data preparation faster, more reliable, and repeatable. Programmatic annotation also enables hybrid workflows, where automated models provide preliminary labels and humans review only uncertain cases, reducing manual effort while maintaining quality.
Proper annotation improves generalization, reduces overfitting, and ensures models perform robustly across different scenarios. Well-integrated API integration and automated workflows also enable continuous updates to labeled datasets, supporting ongoing model retraining and improvement.
Understanding Annotation API Integration Basics
- Connecting to pipelines. Teams can embed annotation services directly into existing ML pipelines through API integration, ensuring that labeled data flows seamlessly from raw input to model training.
- Programmatic annotation. Programmatic annotation enables the automation of predictable or repetitive labeling tasks, while humans focus on complex or uncertain cases, thereby reducing manual effort and errors.
- Automated workflows. Annotation APIs support automated workflows, enabling batch processing, real-time updates, and integration with quality checks to maintain consistency across large datasets.
- Managing data and labels. APIs allow tracking, versioning, and updating of labeled data, ensuring that changes in labeling guidelines or schema can be applied systematically across the dataset.
- Scalability and flexibility. Teams can scale labeling operations efficiently by utilizing integration solutions with annotation APIs, handling diverse data types, and adapting quickly to new project requirements.
- Quality control. Tight integration with ML pipelines ensures that annotated data passes through verification steps, supporting automated workflows for quality checks and enabling continuous improvement of datasets.
- Feedback loops. Annotation APIs facilitate feedback loops between model predictions and human review, allowing iterative refinement of labels and directly improving model performance.
Key Concepts and Data Structures
- Annotation tasks. Annotation tasks define what needs to be labeled in a dataset. They can include images, text, video, or 3D data, and specify the type of annotation required, such as classification, bounding boxes, segmentation, or keypoints.
- Labels and taxonomies. Labels represent the categories or values assigned to data. Taxonomies organize these labels hierarchically or thematically, helping maintain consistency and supporting programmatic annotation.
- Data objects. Data objects are the individual units of data to be annotated, such as images, sentences, or point clouds. Each object may include metadata, such as timestamps, source information, or quality flags, which can be tracked through annotation APIs and API-driven annotation processes.
- Annotation schema. The annotation schema defines the structure and rules for labeling, including required fields, label types, and validation constraints. A well-defined schema ensures that annotations are standardized and compatible with automated workflows and integration solutions.
- Tasks, queues, and assignments. In large-scale projects, tasks are often organized into queues and assigned to annotators or computerized systems.
- Versioning and history. Version control tracks changes in annotations over time, allowing teams to maintain previous states, audit changes, and ensure reproducibility within ML pipelines.
- Confidence scores and metadata. Many annotation systems store confidence scores, annotator IDs, timestamps, and other metadata to support quality control, auditing, and iterative improvements via automated workflows.
- Batch and stream processing structures. Data can be organized for batch annotation or real-time streaming, depending on project needs. Structuring data in these ways ensures that annotation APIs can handle scaling and integration efficiently across ML pipelines.
How Integration Enhances Data Workflows
API integration significantly improves the efficiency of ML pipelines, making data workflows more fluid and manageable. Using annotation APIs and programmatic annotation allows to automate data processing, reducing manual labor and increasing the accuracy of annotations. Thanks to integration solutions, data is instantly transferred between different stages of the pipeline, ensuring continuity and reliability of processes. Automated workflows, implemented through API-driven annotation, allow to scale the processing of large volumes of information and standardize the data structure, which simplifies quality control and adaptation of ML pipelines to new tasks.
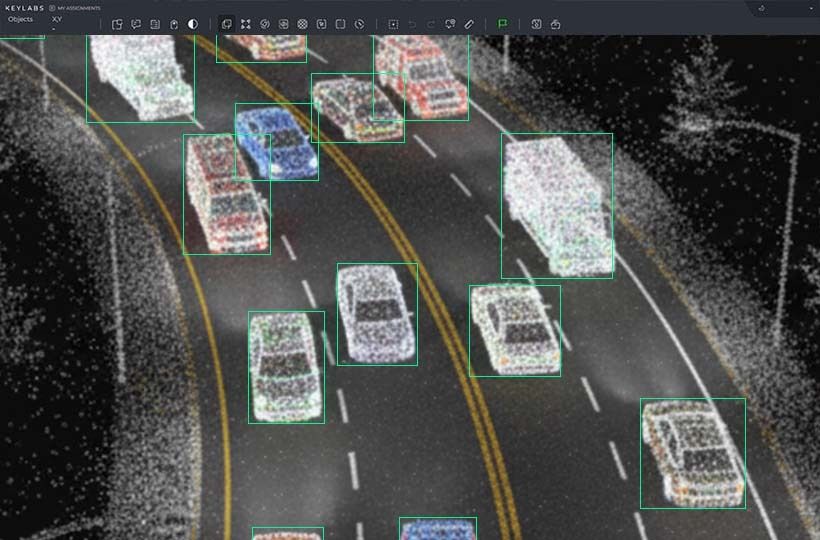
Setting Up Annotation API Environment
First, appropriate annotation APIs are selected that match the data type and annotation requirements. Then, integration solutions are implemented to directly connect the API to existing pipelines, allowing for programmatic annotation and reducing manual work. The environment should support automated workflows, ensuring continuous data processing, including data import, annotation, validation, and export. It is also essential to configure authentication, access control, and define the data structure so that API-driven annotation provides stable and high-quality annotation.
Installation and Configuration Essentials
- Selecting annotation APIs. Choose an API that matches data type and annotation requirements.
- Installing dependencies. Install the necessary libraries and SDKs to integrate with the API.
- Configuring authentication. Create access keys, tokens, or other authentication methods for secure connections.
- Integrating into ML pipelines. Connect the API through integration solutions to automatically transfer data between pipeline stages.
- Data configuration. Define data structures, file formats, and annotation rules to ensure high-quality data.
- Configuring automated workflows. Create automation scripts for importing, annotating, validating, and exporting data.
- Testing and quality control. Verify API operation, annotation correctness, and stability when processing large datasets.
- Monitoring and scaling. Configure logging, error notifications, and the ability to scale API-driven annotation as data volumes grow.
Authentication and Security Mechanisms
API keys and access tokens are used to ensure that only authorized users or systems can interact with annotation APIs. Additionally, OAuth2 or JWT tokens are used for more complex scenarios where delegated authentication or restrictions on rights to different parts of the pipeline are required.
HTTPS encryption is used to protect data during transmission, preventing interception or modification of information. Also necessary are access controls and roles that allow assigning rights to create, edit, or view annotations to individual users or groups. Combined with regular logging and monitoring of requests, these mechanisms provide a secure and reliable API-driven annotation environment that meets the high standards required for ML pipelines.
API Request and Response Formats
API request and response formats are the foundation for annotation APIs to work correctly in ML pipelines. API requests are typically sent in JSON or XML format and contain key parameters such as the data type for annotation, metadata, object identifiers, and configuration settings for programmatic annotation. They can include both single records and data arrays for automated processing of large volumes through automated workflows.
API responses are also generated in a structured format (typically JSON) and contain information about the request status, annotation results, potential errors, and quality metrics. Standardized request and response formats enable seamless integration into ML pipelines and ensure the stability of API-driven annotation. Additionally, they support extensibility, which allows the easy integration of new data types or custom annotation rules without disrupting existing automated workflows.
Summary
An API-first approach to annotation for ML pipelines enables a fully automated, scalable, and reliable data preparation process. It combines programmatic annotation, integration with existing pipelines, and flexible workflows, ensuring efficient updates, quality control, and repeatability of results. Using API-driven solutions enables to standardize work across different data types, facilitate feedback between the model and a human to refine labels, and quickly adapt to changes in data volumes and project requirements. Integration improves model performance, reduces manual labor, and supports continuous learning through centralized and structured data management.
FAQ
What is the main benefit of API integration in ML pipelines?
API integration enables seamless data flow between different stages of ML pipelines, allowing for automated workflows and reducing manual annotation, thereby improving efficiency and data quality.
How do annotation APIs support programmatic annotation?
Annotation APIs allow data to be labeled programmatically, automating repetitive tasks while humans handle uncertain cases, which saves time and ensures consistent results.
Why is API-driven annotation critical for large-scale projects?
It enables automated handling of massive datasets, maintains quality control, and scales easily to meet fluctuating project demands without slowing down ML pipelines.
What role do automated workflows play in ML pipelines?
Automated workflows standardize the annotation process, ensure continuous data processing, and allow integration solutions to manage real-time updates and batch processing efficiently.
How does integration with ML pipelines improve model performance?
By embedding annotation APIs into pipelines, labeled data is updated continuously, supporting accurate training, reducing overfitting, and enabling iterative improvements via programmatic annotation.
What types of data API integrations are handled?
Integration solutions support a diverse range of data types, including text, images, video, and 3D content, enabling programmatic annotation and hybrid workflows across all formats.
How is quality control maintained in API-driven annotation?
Annotation APIs enable automated checks, logging, versioning, and feedback loops, ensuring consistent and reproducible results across large datasets.
What is the advantage of programmatic annotation in hybrid workflows?
Programmatic annotation enables models to label data automatically, forwarding only uncertain cases to humans, thereby reducing manual effort while maintaining high-quality labels.
How does API integration support scalability?
API-driven annotation and integration solutions can efficiently process tens of thousands or millions of markups, adapting to growing data volumes and evolving ML pipeline needs.
Why is setting up an annotation API environment essential?
A properly configured environment, complete with authentication, data structures, and automated workflows, ensures a stable, secure, and high-quality API-driven annotation that is integrated directly into ML pipelines.