Automated Data Labeling: Revolutionizing AI Development
Automated data labeling techniques have emerged as a game-changer in the field of AI development. Efficient data labeling is crucial for training accurate and robust machine learning models, and automation plays a pivotal role in streamlining this process.
Data labeling involves annotating data to provide meaningful information for machine learning algorithms. Traditional manual labeling methods are time-consuming and costly, posing challenges to organizations working with large datasets. However, with the advent of automated data labeling techniques, these limitations are being overcome.
Automated data labeling offers numerous benefits to AI development. By leveraging advanced annotation algorithms and smart data labeling systems, organizations can achieve increased efficiency, accuracy, scalability, and cost-effectiveness. This allows them to accelerate their AI development projects and gain a competitive edge in the market.

There are different types of automated data labeling techniques, including rule-based labeling, active learning, and semi-supervised learning. Each technique has its own advantages and can be applied based on specific project requirements. Implementing these techniques can significantly enhance the productivity of data labeling processes.
Fortunately, there are a variety of data labeling automation tools available in the market. These tools provide intuitive interfaces and functionalities that simplify and expedite the data labeling process. They seamlessly integrate with AI development workflows, enabling organizations to efficiently label their data and train high-performing machine learning models.
While automated data labeling brings remarkable advantages, it also presents challenges. Noise, biased labeling, and handling diverse data types are some of the common issues organizations may encounter. However, industry best practices and strategies can mitigate these challenges and ensure accurate and reliable data labeling.
Evaluating the performance of automated data labeling techniques is crucial. Metrics such as precision, recall, and F1 score help assess the effectiveness of these techniques. Advanced annotation algorithms and machine learning annotation methods can be employed to further enhance the quality of labeled datasets.
Implementing automated data labeling requires ethical considerations as well. Biases, fairness issues, and privacy concerns must be addressed to ensure responsible data labeling practices. Organizations must strive for transparency, fairness, and accountability in their automated data labeling processes.
The future of automated data labeling techniques looks promising. Advancements in smart data labeling systems, natural language processing, and computer vision technologies are expected to revolutionize AI development across various industries. Organizations that embrace these trends will stay ahead of the curve and unlock new possibilities for innovation.
In conclusion, automated data labeling techniques are transforming the landscape of AI development. By adopting efficient data labeling solutions, organizations can build robust and accurate machine learning models, paving the way for breakthroughs in various domains.
Key Takeaways:
- Automated data labeling techniques streamline the process of data annotation for machine learning models.
- They offer benefits such as increased efficiency, accuracy, scalability, and cost-effectiveness.
- Different types of automated data labeling techniques, such as rule-based labeling and active learning, cater to specific project requirements.
- Data labeling automation tools simplify the data labeling process and integrate with AI development workflows.
- Evaluating performance, addressing ethical considerations, and staying updated with emerging trends are crucial for successful implementation of automated data labeling techniques.
Understanding Data Labeling
Data labeling is a crucial process in training machine learning models, enabling them to understand and make accurate predictions from data. By assigning meaningful labels to data, machine learning algorithms can learn patterns, identify relationships, and make informed decisions. Traditionally, data labeling has been done manually, requiring human annotators to carefully analyze and tag each data point. However, this approach poses significant challenges in terms of time and cost efficiency.
The Challenges of Manual Data Labeling
Manual data labeling methods are labor-intensive and time-consuming. They involve hiring and managing a team of annotators who meticulously label each data sample according to specific guidelines. This process can be slow and error-prone, especially when dealing with large datasets. Additionally, the need for human intervention makes scaling data labeling operations expensive and logistically complex.
"Manual data labeling methods can be slow, error-prone, and expensive."
Moreover, human annotators may introduce bias or inconsistency while labeling data, potentially impacting the quality and integrity of the labeled dataset. The subjective interpretation of labeling guidelines and cognitive limitations can lead to variations in labeling decisions across annotators. Such inconsistencies can significantly affect the performance and reliability of machine learning models.
Efficient Data Labeling Solutions
To address the challenges posed by manual data labeling, efficient and automated solutions have emerged. These solutions leverage machine learning annotation methods and advanced algorithms to streamline the data labeling process.
One approach is to use rule-based labeling techniques, where predefined rules are used to assign labels to data. This method is suitable for cases where the labeling rules are well-defined and consistently applicable. For example, in a sentiment analysis task, specific keywords or phrases can be used to determine the sentiment of a text sample.
Active learning is another technique that combines manual and automated data labeling. It iteratively selects data samples that are difficult for the model to label confidently. These samples are then labeled by human annotators, improving the model's performance over time. Active learning reduces the reliance on manual labeling while effectively utilizing human expertise.
Semi-supervised learning is yet another approach, where a small amount of labeled data is combined with a larger amount of unlabeled data. The model learns from the labeled samples and generalizes its understanding to the unlabeled data. This approach reduces manual labeling efforts by leveraging the available labeled data more effectively.
By adopting efficient data labeling solutions, organizations can overcome the limitations of manual labeling methods, improve labeling accuracy, and realize significant time and cost savings.
In the next section, we will delve into the benefits of automated data labeling techniques and explore how they revolutionize AI development.
Benefits of Automated Data Labeling Techniques
Automated data labeling techniques offer numerous advantages for AI development. These advanced solutions, powered by cutting-edge technologies such as auto data labeling software and advanced annotation algorithms, have revolutionized the data labeling process, enhancing efficiency and accuracy.
One of the key benefits of automated data labeling is increased efficiency. By employing intelligent algorithms, these techniques significantly reduce the time and effort required to label large datasets. Manual data labeling can be a labor-intensive task, often prone to errors and inconsistencies. Automated solutions streamline this process, enabling organizations to label data at scale while maintaining high levels of productivity.
Moreover, automated data labeling techniques offer enhanced accuracy. Traditional manual labeling methods are subject to human errors and biases, which can impact the quality of labeled datasets and subsequently affect the performance of machine learning models. Advanced annotation algorithms, however, leverage machine learning capabilities to ensure precise and consistent labeling, resulting in highly accurate datasets for training AI models.
Scalability is another advantage of automated data labeling techniques. As organizations handle increasingly large volumes of data, manual labeling becomes impractical and time-consuming. Automated solutions can efficiently label massive datasets, allowing businesses to scale their AI development efforts without compromising data quality or project timelines.
Cost-effectiveness is a significant benefit of utilizing automated data labeling techniques. Traditional manual labeling methods require extensive manpower, which can be expensive, especially for organizations with limited resources. Automated solutions minimize the need for manual intervention, reducing labor costs and increasing overall cost efficiency.
In addition to the above advantages, automated data labeling techniques also pave the way for the development of smart data labeling systems. These systems have the ability to self-learn and improve over time, enhancing the accuracy and efficiency of data labeling processes. Smart data labeling systems leverage artificial intelligence and machine learning capabilities to adapt to different data types, handle complex labeling tasks, and optimize the overall data labeling workflow.
Overall, automated data labeling techniques equipped with advanced annotation algorithms and intelligent software offer significant advantages, including increased efficiency, accuracy, scalability, and cost-effectiveness. These solutions play a pivotal role in accelerating AI development by providing high-quality labeled datasets essential for training robust and accurate machine learning models.
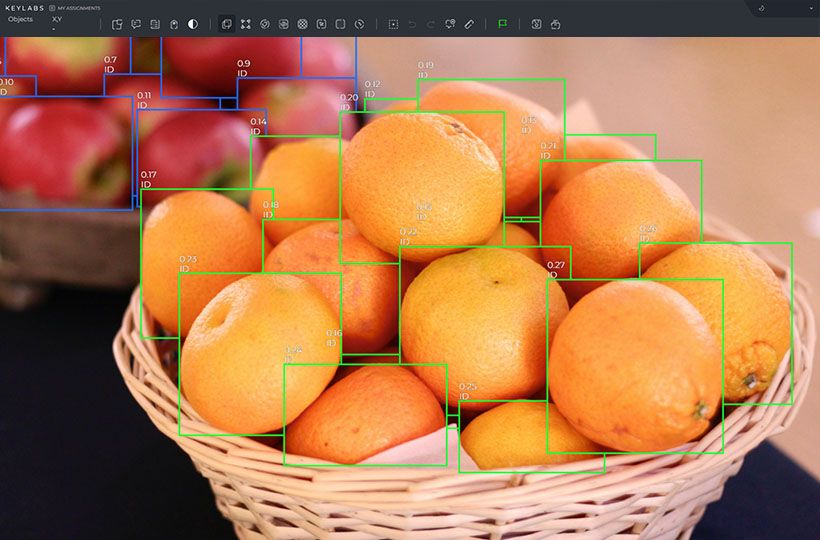
Types of Automated Data Labeling Techniques
Automated data labeling techniques employ various methods to streamline and optimize the process of annotating data for AI development. This section provides an overview of different approaches to automated data labeling, including rule-based labeling, active learning, and semi-supervised learning.
Rule-based Labeling
Rule-based labeling is a technique that relies on predefined rules and patterns to assign labels to data. These rules are created by domain experts and can be based on specific criteria, such as keywords, patterns, or logical conditions. Rule-based labeling is especially useful in scenarios where the labeling criteria are well-defined, and the data follows a clear and consistent structure. It offers a fast and efficient way to label large volumes of data without human intervention.
Active Learning
Active learning is a data labeling technique that utilizes machine learning algorithms to intelligently select the most informative samples for human annotation. Initially, a small set of labeled data is provided to the algorithm. The algorithm then actively identifies and prioritizes instances that are likely to improve the model's performance the most. These selected samples are sent for human annotation, and the model is retrained using the newly labeled data. Active learning reduces the labeling effort by focusing on the data points that provide the most learning value, making it a cost-effective approach.
Semi-Supervised Learning
Semi-supervised learning is a hybrid approach that combines labeled and unlabeled data during the training process. This technique takes advantage of the fact that labeled data is often scarce and expensive to obtain, while unlabeled data is more readily available. The algorithm uses the small labeled dataset to build an initial model and then leverages the unlabeled data to improve the model's performance. By incorporating unlabeled data, semi-supervised learning enables the AI model to learn from a larger and more diverse dataset, leading to enhanced accuracy and generalization.
| Technique | Description | Benefits |
|---|---|---|
| Rule-based Labeling | Predefined rules and patterns | - Quick and efficient labeling - Well-suited for structured data |
| Active Learning | Machine learning algorithms select informative samples | - Reduces labeling effort - Focuses on high-value data |
| Semi-Supervised Learning | Combines labeled and unlabeled data for training | - Utilizes abundant unlabeled data - Improves model accuracy |
Each automated data labeling technique offers unique advantages and is suitable for different use cases. Understanding these techniques can help organizations choose the most appropriate approach to efficiently annotate their data and accelerate AI development.
Data Labeling Automation Tools
When it comes to automating the data labeling process, there are a variety of AI data labeling tools available in the market that can significantly streamline and enhance the efficiency of the task. These tools offer advanced features and functionality designed to simplify the labeling workflow and integrate seamlessly with AI development pipelines.
One popular data labeling tool is Keylabs. It is a comprehensive platform that enables users to create, manage, and collaborate on data labeling projects. Keylabs offers a user-friendly interface, custom labeling templates, and the ability to integrate with popular AI frameworks for seamless data ingestion.
With its intuitive labeling interface, team collaboration features, and robust automation capabilities, Keylabs is ideal for complex data labeling projects.
Keylabs offers a sophisticated platform that combines human labeling with efficient AI algorithms, delivering accurate and reliable results. The tool supports a wide range of data types, including images, videos, and text, making it versatile for various AI applications.
The use of automated data labeling techniques brings several challenges and limitations that need to be addressed to ensure accurate and reliable data labeling. These challenges can impact the quality of labeled data and subsequently affect the performance of machine learning models.
Noise in Data Labeling
One of the challenges in automated data labeling is dealing with noisy data. Noise refers to the presence of irrelevant or incorrect labels in the dataset. It can occur due to human errors or inconsistencies in the labeling process. Noise can negatively affect the training of machine learning models, leading to inaccurate predictions and reduced model performance.
Efficient data labeling solutions should incorporate techniques or algorithms that can identify and handle noisy data effectively. By minimizing the impact of noise, these solutions can improve the quality of labeled datasets and enhance the overall performance of AI models.
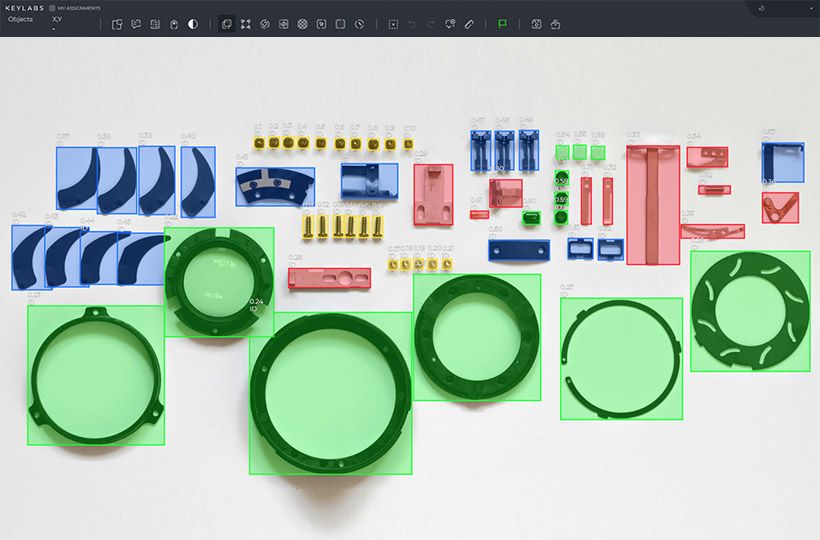
Biased Labeling
Automated data labeling techniques can also face challenges related to biased labeling. Bias in data labeling occurs when certain groups or classes are overrepresented or underrepresented in the labeled datasets. Biased labeling can lead to biased predictions, which can have significant ethical and fairness implications.
To address bias in automated data labeling, it is crucial to implement strategies that promote fairness and diversity in the labeling process. This may involve carefully designing labeling guidelines, incorporating diverse human annotators, or using techniques like active learning to ensure an unbiased representation of the data.
Handling Diverse Data Types
Automated data labeling techniques often need to handle diverse data types, including text, images, audio, and video. Each data type requires specific labeling methods and algorithms, posing a challenge for efficient data labeling.
To overcome this challenge, advanced annotation algorithms and smart data labeling systems are essential. These technologies can provide specialized tools and techniques tailored to different data types, improving the accuracy and efficiency of the labeling process.
"Addressing the challenges in automated data labeling is crucial for achieving accurate and reliable data labeling, ultimately enhancing the performance of machine learning models."
In summary, automated data labeling techniques present challenges such as noise in data labeling, biased labeling, and handling diverse data types. These challenges can be mitigated through the use of efficient data labeling solutions, advanced annotation algorithms, and smart data labeling systems. By addressing these challenges, organizations can ensure the production of high-quality labeled datasets and improve the overall performance of machine learning models.
| Challenges | Impact | Solution |
|---|---|---|
| Noise in Data Labeling | Reduced model performance | Implement noise detection techniques and data cleaning algorithms |
| Biased Labeling | Biased predictions, fairness issues | Incorporate fairness guidelines, diverse annotators, and active learning techniques |
| Handling Diverse Data Types | Efficient labeling for different data types | Utilize advanced annotation algorithms and smart data labeling systems |
Best Practices for Implementing Automated Data Labeling
Implementing automated data labeling techniques effectively requires careful planning and adherence to best practices in the field. By following industry guidelines, organizations can maximize the benefits of automated data labeling and enhance the accuracy of their machine learning models.
1. Leverage Domain Expertise
Domain expertise plays a crucial role in automated data labeling. It is essential to involve subject matter experts who possess in-depth knowledge of the data being labeled. These experts can provide valuable insights and establish the right labeling guidelines, ensuring that the labeled data accurately represents the real-world scenarios.
2. Establish Quality Control Mechanisms
Quality control is paramount in automated data labeling to ensure the accuracy and reliability of labeled datasets. Implement mechanisms to validate the quality of the labels, such as inter-rater reliability assessments or double-checking a percentage of labels. Regularly monitor and evaluate the performance of the automated data labeling system to identify and address any potential issues.
3. Continuously Improve Labeling Process
Continuous improvement is key to refining the automated data labeling process. Actively gather feedback from data labelers and domain experts to identify areas for enhancement. Leverage insights gained from analyzing labeled data to iteratively refine the labeling guidelines and improve the accuracy of the automated labeling system.
4. Employ Machine Learning Annotation Methods
Machine learning annotation methods can significantly enhance the accuracy of automated data labeling. By incorporating machine learning techniques into the annotation process, organizations can leverage algorithms to improve the precision and efficiency of the labeling system. This enables the automated system to adapt and learn from human-labeled examples, leading to better results over time.
"Implementing automated data labeling techniques effectively requires careful planning, domain expertise, quality control, and continuous improvement. By incorporating machine learning annotation methods into the process, organizations can achieve accurate and reliable data labeling for their machine learning models."
5. Ensure Robust Data Sampling
When implementing automated data labeling, it is crucial to ensure a robust data sampling strategy. The labeled data should be representative of the entire dataset, covering diverse scenarios and edge cases. Adequate sampling minimizes bias and ensures that the machine learning models are trained on a comprehensive set of labeled examples.
6. Regularly Evaluate Performance
Periodically evaluate the performance of the automated data labeling system. Use metrics such as precision, recall, and F1 score to assess the quality of the labeled datasets. This evaluation helps identify any issues or limitations in the labeling process and enables organizations to make necessary adjustments to improve the system's performance.
By following these best practices, organizations can maximize the benefits of automated data labeling techniques. Leveraging domain expertise, establishing quality control mechanisms, continuously improving the labeling process, employing machine learning annotation methods, ensuring robust data sampling, and regularly evaluating performance are key to achieving accurate and reliable automated data labeling for machine learning models.
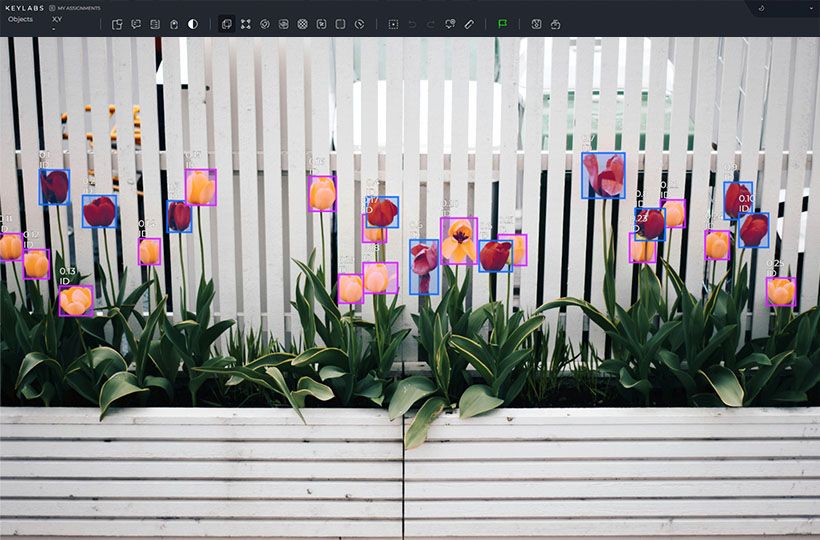
Evaluating the Performance of Automated Data Labeling Techniques
When implementing automated data labeling techniques, it is crucial to evaluate their performance and efficacy. By assessing the quality of labeled datasets, organizations can ensure the reliability and accuracy of their machine learning models. In this section, we will explore several methods for evaluating the performance of automated data labeling techniques and discuss the role of advanced annotation algorithms and machine learning annotation methods in this process.
One commonly used method for evaluation is through the use of metrics such as precision, recall, and F1 score. These metrics provide valuable insights into the effectiveness of automated data labeling techniques in correctly identifying and categorizing data points. Precision measures the proportion of correctly labeled instances out of the total number of instances labeled as positive. Recall, on the other hand, calculates the proportion of correctly labeled instances out of all the actual positive instances. The F1 score combines precision and recall to provide a balanced measure of the model's performance.
Advanced annotation algorithms play a vital role in evaluating the quality of labeled datasets. These algorithms employ sophisticated techniques to identify and rectify labeling errors, ensuring the accuracy and reliability of the data. By leveraging these algorithms, organizations can improve the efficiency and effectiveness of their evaluation processes.
Machine learning annotation methods also contribute significantly to the evaluation of automated data labeling techniques. These methods utilize machine learning models to compare the labeled datasets with ground truth annotations. By analyzing the disparities between the two, organizations can identify and address potential biases or discrepancies in the labeled data. This iterative process helps improve the overall quality of the labeled datasets and enhances the performance of the machine learning models.
In conclusion, evaluating the performance of automated data labeling techniques is essential for building robust and accurate machine learning models. Through the use of metrics, advanced annotation algorithms, and machine learning annotation methods, organizations can ensure the reliability and efficacy of their data labeling processes. By continuously evaluating and refining these techniques, organizations can achieve higher levels of accuracy and enhance the overall performance of their AI systems.
Ethical Considerations in Automated Data Labeling
As organizations increasingly rely on automated data labeling techniques to streamline the process of training machine learning models, it is important to address the ethical considerations associated with these techniques. Beyond the technical aspects of efficient data labeling solutions and automated data tagging techniques, there are potential biases, fairness issues, and privacy concerns that may arise.
One of the main challenges in automated data labeling is the presence of biases in the labeled datasets. Biases can be introduced either through biased training data or biased labeling algorithms. This can result in AI models that perpetuate and amplify existing biases, leading to unfair or discriminatory outcomes. It is crucial to develop strategies to detect and mitigate biases in labeled datasets to ensure fairness and equal representation.
"Ethical considerations in automated data labeling extend beyond technical aspects, addressing potential biases, fairness issues, and privacy concerns."
Privacy is another important ethical consideration when it comes to data labeling. Automated data labeling techniques often rely on large amounts of personal data, which raises concerns about privacy infringement. Organizations must adopt robust data protection measures, including anonymization and data encryption, to safeguard individuals' privacy rights.
Implementing responsible and ethical data labeling practices is essential to avoid negative consequences and maintain public trust. Organizations should establish guidelines and frameworks that promote transparency, accountability, and the inclusion of diverse perspectives in the data labeling process. Additionally, ongoing monitoring and audits are necessary to ensure compliance with ethical standards.
Ethical considerations in automated data labeling go hand in hand with the responsible development and deployment of AI technologies. By addressing biases, fairness, and privacy concerns, organizations can foster trust, promote fairness, and mitigate potential harm. It is crucial to prioritize ethical considerations alongside the adoption of automated data labeling techniques to build AI systems that benefit society as a whole.
Key Ethical Considerations in Automated Data Labeling:
- Bias in labeled datasets and algorithms
- Fairness in AI model outcomes
- Privacy protection and data security
- Transparency and accountability
- Inclusion and diversity in data labeling
Strategies for Ensuring Ethical Data Labeling Practices:
- Implement robust bias detection and mitigation techniques
- Adopt privacy protection measures, such as anonymization and encryption
- Create guidelines and frameworks for transparent and accountable data labeling
- Conduct ongoing monitoring and audits to ensure ethical compliance
- Foster diverse and inclusive perspectives in the data labeling process
Future Trends in Automated Data Labeling Techniques
As technology continues to evolve, the future of automated data labeling techniques looks promising. Advancements in smart data labeling systems, natural language processing, and computer vision technologies are expected to revolutionize AI development in various industries.
Smart Data Labeling Systems
One of the key future trends in automated data labeling techniques is the development of smart data labeling systems. These systems leverage artificial intelligence and machine learning algorithms to automate the data labeling process more efficiently. By utilizing advanced annotation algorithms, smart data labeling systems can accurately label large volumes of data with minimal human intervention.
Smart data labeling systems offer several benefits over traditional labeling methods. They improve efficiency by reducing manual efforts and streamlining the data labeling workflow. Additionally, these systems enhance accuracy by leveraging machine learning models trained on high-quality labeled data, ensuring precise and reliable annotations.
Natural Language Processing (NLP)
Another significant trend in automated data labeling is the application of natural language processing (NLP) techniques. NLP enables computers to understand, interpret, and generate human language, facilitating the automated labeling of textual data.
With NLP, automated data labeling systems can analyze text at a deeper level, extracting meaningful insights and categorizing information more effectively. This enables the efficient labeling of text-based datasets, enhancing the performance of AI models in natural language understanding and text-based applications.
Computer Vision Technologies
Computer vision technologies are also poised to shape the future of automated data labeling. These technologies enable machines to interpret and understand visual information, making it possible to automate the labeling of image and video datasets.
Advanced computer vision algorithms can accurately identify objects, features, and patterns in visual data, enabling precise and efficient labeling. By leveraging computer vision technologies, automated data labeling systems can significantly reduce the manual effort and time required to label large-scale image datasets. This enhances the development of computer vision models and applications, such as object recognition, autonomous vehicles, and medical imaging.
"The advancements in smart data labeling systems, natural language processing, and computer vision technologies hold immense potential for accelerating AI development and unlocking new opportunities across industries."
With the continued evolution of automated data labeling techniques, organizations can harness the power of labeled data more efficiently, paving the way for faster and more accurate AI model development. As smart data labeling systems, NLP, and computer vision technologies continue to advance, the possibilities for AI-driven innovation are endless.
Conclusion
Automated data labeling techniques have revolutionized AI development, providing a transformative impact on the industry. By streamlining the data labeling process, these techniques have enabled efficient and accurate training of machine learning models. Organizations can now leverage advanced annotation algorithms and smart data labeling systems to label data at scale, improving efficiency and reducing costs.
The benefits of automated data labeling techniques are evident. They not only offer increased accuracy and scalability but also help in building robust and reliable machine learning models. With rule-based labeling, active learning, and semi-supervised learning, organizations can choose the most suitable approach based on their specific needs, ensuring optimal results.
As the demand for automated data labeling grows, so does the availability of data labeling automation tools. These tools provide a wide range of features, usability, and integration options, empowering organizations to implement automated data labeling seamlessly into their AI development workflows.
However, challenges such as biased labeling, handling diverse data types, and potential ethical concerns need to be carefully addressed. Organizations must adopt best practices, leverage machine learning annotation methods, and continuously evaluate the performance of automated data labeling techniques to ensure accurate results and uphold ethical standards. As advancements in smart data labeling systems and AI technologies continue, the future holds immense potential for further improvements in automated data labeling techniques, propelling the AI development landscape into new horizons.
FAQ
What is data labeling?
Data labeling is the process of annotating or tagging data to provide meaning and context to machine learning algorithms. It involves assigning labels or tags to data points, such as images, text, or videos, to create labeled datasets that are used to train AI models.
What are the benefits of using automated data labeling techniques?
Automated data labeling techniques offer several advantages, including increased efficiency, accuracy, scalability, and cost-effectiveness. Advanced annotation algorithms and smart data labeling systems can streamline the labeling process and reduce human effort, resulting in faster and more reliable data annotation.
What are the types of automated data labeling techniques?
There are various types of automated data labeling techniques, including rule-based labeling, active learning, and semi-supervised learning. Rule-based labeling involves applying predetermined rules to assign labels. Active learning selects the most informative samples for human annotation, while semi-supervised learning combines labeled and unlabeled data to create labeled datasets.
What are the challenges in automated data labeling?
Automated data labeling techniques can face challenges such as noise in the data, biased labeling, and handling diverse data types. Ensuring the quality and reliability of the labeled datasets is crucial. Proper strategies, including quality control measures and domain expertise, are essential to mitigate these challenges.
What are the best practices for implementing automated data labeling techniques?
Implementing automated data labeling techniques effectively requires domain expertise, quality control mechanisms, and continuous improvement. Leveraging machine learning annotation methods can also enhance the accuracy and reliability of automated data labeling.
Are there any successful case studies of automated data labeling implementation?
Yes, there have been successful implementations of automated data labeling techniques. Organizations in various industries have achieved efficiency gains, improved model performance, and accelerated AI development. Some notable technologies and strategies employed include advanced annotation algorithms and auto data labeling software.
How can the performance of automated data labeling techniques be evaluated?
The performance of automated data labeling techniques can be evaluated using metrics such as precision, recall, and F1 score. Advanced annotation algorithms and machine learning annotation methods can also be used to assess the quality and effectiveness of the labeled datasets.
What are the ethical considerations in automated data labeling?
Ethical considerations in automated data labeling include potential biases, fairness issues, and privacy concerns. It is important to ensure ethical and responsible data labeling practices, and mitigate any unintended consequences that may arise from automated data tagging techniques or efficient data labeling solutions.
What are the future trends in automated data labeling techniques?
The future of automated data labeling techniques is expected to see advancements in smart data labeling systems, natural language processing, and computer vision technologies. These developments are likely to have a transformative impact on AI development across various industries.
