Best Datasets for Semantic Segmentation Training
Semantic segmentation plays a crucial role in computer vision applications, enabling the precise identification and labeling of objects within an image. To train highly accurate and effective semantic segmentation models, it is essential to have access to high-quality training datasets. These datasets not only provide the necessary labeled examples for model training but also contribute to the development and advancement of deep learning algorithms.

When it comes to semantic segmentation datasets, researchers and practitioners have a wide range of options to choose from. These datasets can vary in size, complexity, annotation quality, and application focus. Therefore, selecting the right datasets is vital to ensure the success of the model development process.
- Choosing the right semantic segmentation datasets is crucial for training accurate and robust models.
- The availability of labeled examples in these datasets is essential for model training.
- High-quality datasets contribute to the development and advancement of deep learning algorithms.
- Researchers and practitioners have access to a wide range of semantic segmentation datasets.
- Proper dataset selection ensures successful model development and state-of-the-art results.
Image Segmentation Techniques and Architectures
Image segmentation is a fundamental task in computer vision that involves dividing an image into distinct regions. To achieve accurate and reliable segmentation, advanced techniques and architectures are employed.
One of the most common architectures used for image segmentation is the encoder-decoder architecture. This architecture consists of an encoder network that learns the high-level features of the input image and a decoder network that reconstructs the segmented output. An example of an encoder-decoder architecture is U-Net, which has been widely used and proven effective in various segmentation tasks.
In addition to the encoder-decoder architecture, there are other architectures that have shown promising results in image segmentation. Joint Pyramid Upsampling (JPU) is an architecture that combines the advantages of both encoder-decoder and pyramid pooling modules, resulting in improved segmentation accuracy. Gated Shape CNNs utilize a gating mechanism to enhance shape information and improve the segmentation performance. DeepLab with atrous convolution is another architecture that incorporates dilated convolutions to capture multi-scale contextual information.
"The encoder-decoder architecture, including U-Net, is a popular choice for image segmentation. However, other architectures like JPU and Gated Shape CNNs, as well as DeepLab with atrous convolution, offer alternative approaches with promising results."
These image segmentation architectures leverage different techniques and module designs to address the challenges of accurate object delineation.
| Architecture | Advantages |
|---|---|
| U-Net | Efficient in capturing both local and global contextual information |
| Joint Pyramid Upsampling (JPU) | Combines the advantages of encoder-decoder and pyramid pooling modules |
| Gated Shape CNNs | Enhanced shape information and improved performance |
| DeepLab with atrous convolution | Effectively captures multi-scale contextual information |
These image segmentation techniques and architectures continue to evolve as researchers explore innovative approaches to improve accuracy and efficiency in segmentation tasks. By leveraging the strengths of these architectures, computer vision systems can effectively identify and classify objects within images, enabling a wide range of applications across various domains.
Importance of Annotated Image Datasets
To train image segmentation models effectively, annotated image datasets play a crucial role. These datasets consist of images paired with pixel-level annotations, which serve as ground truth masks for model training. By providing detailed annotations, annotated image datasets enable the development of accurate segmentation models across various object categories and scenes.
One of the widely recognized annotated image datasets is the COCO dataset. It contains a vast collection of labeled images spanning multiple object categories, making it a valuable resource for training image segmentation models. The ImageNet dataset is another well-known annotated image dataset that offers a large-scale collection of labeled images encompassing a wide range of object classes.
In addition to COCO and ImageNet, the PASCAL VOC 2012 dataset is a popular choice for training image segmentation models. It provides labeled images specifically curated for the challenges of visual object recognition and has been widely used in research and benchmark evaluations. The Cityscapes dataset is yet another important annotated image dataset that focuses on street scenes, making it suitable for training models targeting urban scene understanding.
These annotated image datasets provide the necessary training data for developing accurate segmentation models. The combination of images and pixel-level annotations allows models to learn the intricate details of object boundaries and segmentation boundaries, enabling precise object identification and labeling.
"Annotated image datasets are essential for training image segmentation models as they provide the necessary ground truth masks for accurate and reliable model training."
With access to annotated image datasets like COCO, ImageNet, PASCAL VOC 2012, and Cityscapes, researchers and practitioners can leverage high-quality training data to advance the field of image segmentation and develop state-of-the-art models.
Object Detection Datasets for Semantic Segmentation
Object detection and semantic segmentation are closely intertwined, requiring high-quality labeled datasets to train accurate models. Several datasets are widely recognized for their effectiveness in training object detection algorithms for semantic segmentation tasks. These datasets encompass a wide range of object categories, enabling the development of robust and versatile models.
One prominent dataset is the COCO dataset, which stands for Common Objects in Context. COCO provides a comprehensive collection of images covering 80 object categories, making it a valuable resource for object detection and semantic segmentation tasks. With over 330,000 labeled images, COCO offers a vast training set for developing high-performance models.
Another notable dataset is the Open Images dataset, a large-scale dataset that contains over 9 million annotated images spanning multiple object categories. This dataset includes diverse scenes and offers a broad range of annotations, making it suitable for various computer vision tasks, including semantic segmentation.
The Pascal VOC 2012 dataset is a popular dataset widely used for object detection and semantic segmentation evaluation. It comprises over 11,500 fully annotated images covering 20 distinct object classes, making it an ideal choice for benchmarking and comparing different models.
The Cityscapes dataset focuses on urban scenes and provides pixel-level annotations for semantic segmentation. It contains high-resolution images captured from street scenes in various cities, enabling the development and evaluation of models specifically designed for urban object detection and semantic segmentation.
Object Detection Datasets for Semantic Segmentation
| Dataset Name | Object Categories | Number of Images |
|---|---|---|
| COCO dataset | 80 | Over 330,000 |
| Open Images dataset | Multiple | Over 9 million |
| PASCAL VOC 2012 dataset | 20 | Over 11,500 |
| Cityscapes dataset | Urban scenes | High-resolution images |
These object detection datasets, including COCO, Open Images, PASCAL VOC 2012, and Cityscapes, provide a wealth of training data for developing highly accurate and efficient semantic segmentation models. By leveraging these datasets, researchers and practitioners can advance the field of computer vision and drive innovation in object detection and semantic segmentation algorithms.
Computer Vision Datasets for Semantic Segmentation
Computer vision datasets are an integral part of training and evaluating semantic segmentation models. These datasets provide the necessary labeled images to train deep learning models and assess their performance accurately. When it comes to computer vision, several datasets are widely used for pre-training and benchmarking semantic segmentation models.
One of the most prominent datasets in computer vision is the ImageNet dataset. It consists of millions of high-resolution images spanning thousands of object categories, making it a valuable resource for training deep learning models. ImageNet has played a critical role in advancing computer vision research and has become a benchmark for semantic segmentation tasks.
In addition to ImageNet, there are other popular computer vision datasets that can be utilized for pre-training semantic segmentation models. These include:
- CIFAR-10: A dataset of 60,000 32x32 color images in 10 distinct classes, commonly used for image classification but can be adapted for semantic segmentation tasks.
- CIFAR-100: Similar to CIFAR-10, but with 100 classes, providing a wider variety of objects for training and evaluation.
- STL-10: A dataset containing 96x96 pixel color images in 10 different classes, often used as a benchmark for unsupervised learning and transfer learning.
- MNIST: Although primarily used for handwritten digit recognition, the MNIST dataset can also be employed for simple semantic segmentation tasks due to its labeled grayscale images.
- Fashion-MNIST: An extension of the MNIST dataset that consists of clothing and fashion-related images, suitable for training models in the context of semantic segmentation in the fashion domain.
These computer vision datasets cover various object classes, allowing deep learning models to learn and generalize effectively in semantic segmentation tasks. By leveraging these datasets, researchers and practitioners can develop and refine their models to achieve state-of-the-art results in computer vision applications.
Semantic Segmentation Dataset Creation and Conversion
Creating and converting semantic segmentation datasets are essential steps in preparing the data for training accurate and robust models. These datasets consist of images, annotated with pixel-level segmentation masks, that serve as ground truth for model training. To ensure the datasets are in the proper format and ready for training, various tools and frameworks are available to simplify the dataset creation and conversion process.
When creating semantic segmentation datasets, several steps are involved:
- Data Preparation: This initial step involves gathering and organizing the images that will be part of the dataset. The dataset should represent a diverse range of objects and scenes relevant to the target application. In this phase, image quality and preprocessing techniques can be applied to enhance the dataset's overall quality and consistency.
- Object Labeling: Once the dataset's images are prepared, the next step is to label the objects in the images. This process involves manually identifying and marking the objects or regions of interest, using bounding boxes or other annotation techniques. Each object should be labeled accurately to generate precise segmentation masks.
- Mask Generation: After labeling the objects, pixel-level segmentation masks need to be generated. These masks represent the ground truth annotations for each labeled object in the images. The masks should be aligned accurately with the labeled objects, as they would be used for training the semantic segmentation models. The process of mask generation can involve manual annotation or leveraging automated tools that utilize machine learning algorithms.
Converting existing datasets to a semantic segmentation format may also be necessary for certain projects. For example, if a dataset consists of images with bounding box annotations, the annotations can be converted to pixel-level segmentation masks. This process requires mapping the bounding boxes to corresponding regions in the images and generating masks accordingly.
"Effective dataset creation and conversion are vital for building accurate and robust semantic segmentation models. Proper preparation, precise labeling, and accurate mask generation are key steps that contribute to the success of the models."
Datasets for Specialized Semantic Segmentation Tasks
In addition to general-purpose semantic segmentation datasets, there are specialized datasets available for specific tasks. These datasets focus on domains such as medical image segmentation, satellite imagery, and aerial imagery, providing valuable resources for training models tailored to these specific areas.
Medical image segmentation datasets offer a wide range of medical imaging data, including MRI scans, CT scans, and X-ray images. These datasets are meticulously labeled with pixel-level annotations, enabling the development of accurate models for tasks such as tumor detection, organ segmentation, and disease diagnosis.
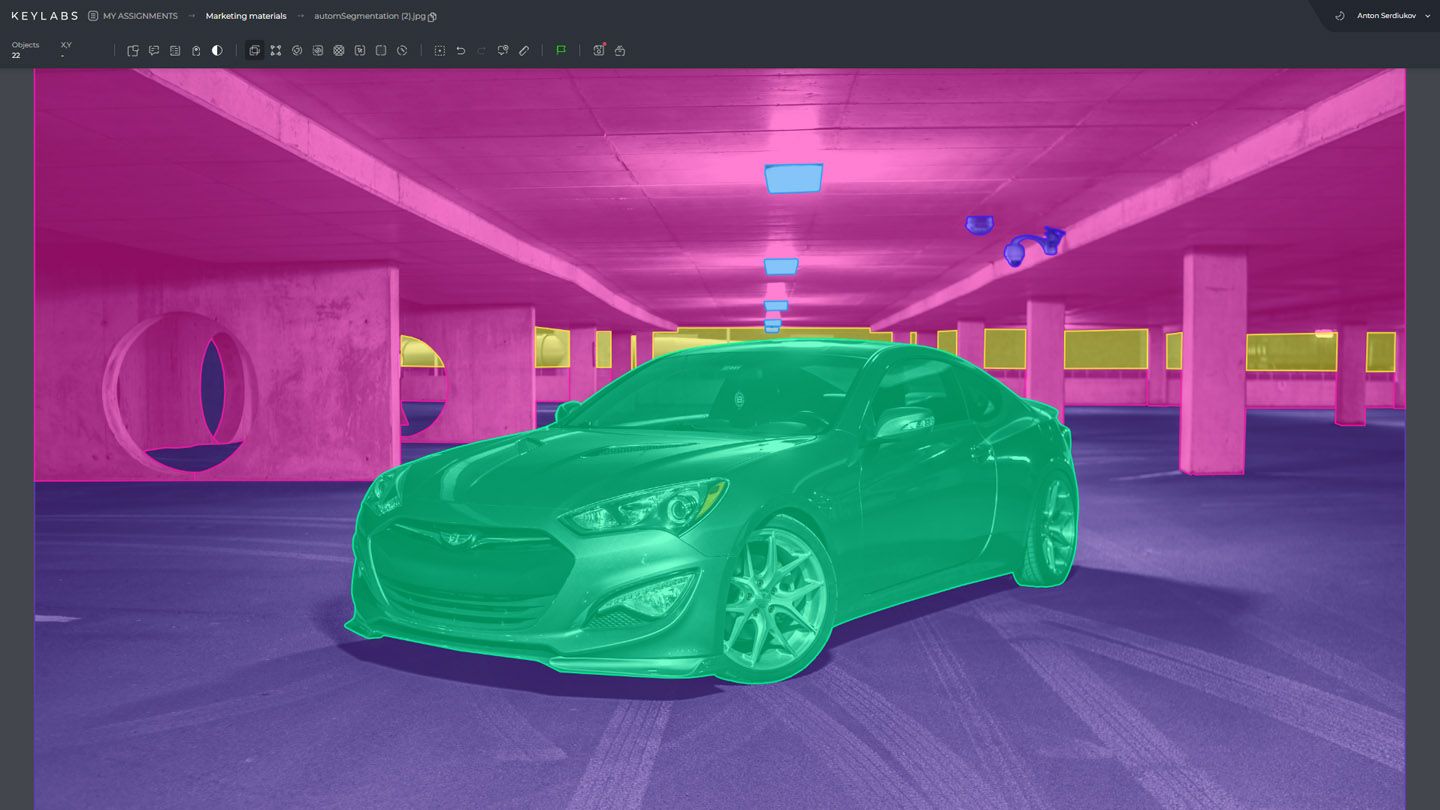
Satellite imagery datasets, on the other hand, consist of high-resolution images captured by satellites orbiting the Earth. These datasets allow researchers and practitioners to train models for applications such as land cover mapping, urban planning, and environmental monitoring. They provide valuable insights into large-scale geographic areas and facilitate the analysis of complex landscapes.
Similarly, aerial imagery datasets provide detailed views of the Earth's surface from an elevated perspective. These datasets are particularly useful in applications such as object detection, infrastructure monitoring, and disaster response. By training models on aerial imagery datasets, researchers can develop accurate and specialized solutions for a wide range of aerial-based tasks.
Challenges and Considerations in Using Semantic Segmentation Datasets
While utilizing semantic segmentation datasets is essential for training accurate and robust models, there are several challenges and considerations that need to be addressed in order to ensure optimal results. It is important to take into account factors such as dataset size, task complexity, and available computing resources. By carefully considering these aspects, practitioners can make informed decisions regarding dataset selection and model development.
Dataset Size
The size of the dataset plays a crucial role in the performance of a semantic segmentation model. Large-scale datasets with a diverse range of images and annotations provide a broader representation of the target domain and contribute to better generalization. However, larger datasets require considerable storage and computational resources for training. On the other hand, smaller datasets may result in overfitting and limited model performance. Striking a balance and determining an optimal dataset size is crucial to ensure both accuracy and efficiency in training the models.
Task Complexity
The complexity of the semantic segmentation task should also be considered when selecting a dataset. Certain applications may require models to identify fine-grained details or handle a large number of object classes. In such cases, it is important to choose a dataset that adequately represents the desired complexity level. For instance, medical image segmentation datasets often contain intricate structures and require specialized models. By aligning the dataset complexity with the task requirements, practitioners can ensure that the models can handle the specific challenges posed by their application.
Computing Resources
The availability of computing resources is another crucial consideration. Training semantic segmentation models requires significant computational power, especially for large-scale datasets and complex tasks. High-performance GPUs and sufficient memory are essential for efficient model training. It is important to assess the computational capabilities and limitations of the hardware resources to determine the feasibility and speed of training. Additionally, practitioners should consider the time and cost implications associated with computing resources, particularly when working with limited budgets or time constraints.
By carefully considering dataset size, task complexity, and computing resources, practitioners can navigate the challenges associated with semantic segmentation datasets and develop models that deliver accurate and efficient segmentation results. Furthermore, leveraging data augmentation techniques and conducting hyperparameter tuning can further enhance model performance and address specific challenges unique to the dataset and task at hand.
| Challenges | Considerations |
|---|---|
| Dataset Size | Choose an optimal dataset size that balances generalization and computational resources. |
| Task Complexity | Select a dataset that adequately represents the complexity of the semantic segmentation task. |
| Computing Resources | Assess the availability and limitations of computational resources for efficient model training. |
Evaluating Semantic Segmentation Models with Datasets
Accurately evaluating the performance of semantic segmentation models is crucial in the field of computer vision. This evaluation is achieved through the use of evaluation datasets and metrics that provide valuable insights into the model's effectiveness. Evaluation datasets serve as a benchmark, providing ground truth annotations for comparison and ensuring the reliability of the assessment.
One widely used evaluation metric for semantic segmentation is the mean Intersection over Union (mIoU). This metric quantifies the level of overlap between the predicted segmentation mask and the ground truth mask, providing a measure of the model's accuracy. A higher mIoU indicates better segmentation performance.
Another common metric is pixel accuracy, which measures the percentage of pixels that are correctly classified by the model. Pixel accuracy is a simple yet effective measure of overall model performance, particularly in situations where class imbalance is present.
Choosing appropriate evaluation datasets is crucial for accurate model assessment. These datasets should cover a diverse range of object categories and scenes relevant to the specific application. By evaluating models on diverse datasets, researchers and practitioners can ensure that their models generalize well and perform consistently across different scenarios.
Example of semantic segmentation evaluation metrics:
| Evaluation Metric | Description |
|---|---|
| Mean Intersection over Union (mIoU) | Calculates the average intersection over union for all classes. Higher mIoU indicates better segmentation performance. |
| Pixel Accuracy | Measures the percentage of correctly classified pixels. Provides a simple measure of overall model performance. |
It is important to note that the choice of evaluation metrics should align with the specific requirements and goals of the application. Different metrics may be more suitable for certain tasks or datasets, and it is essential to consider the unique characteristics of each evaluation scenario.
Evaluating semantic segmentation models with appropriate datasets and metrics not only provides valuable insights into model performance but also enables researchers to fine-tune their models for optimal results. By leveraging evaluation datasets and carefully selected metrics, practitioners can drive advancements in semantic segmentation and push the boundaries of computer vision.

Conclusion
In conclusion, the availability of high-quality semantic segmentation datasets is crucial for training accurate and robust models in the field of computer vision. By utilizing these datasets, researchers and practitioners can develop advanced deep learning algorithms and achieve state-of-the-art results in various applications.
Understanding the different types of datasets, such as image segmentation benchmark datasets and annotated image datasets, is essential for selecting the most suitable data for model training. Furthermore, the utilization of specialized datasets for specific tasks, such as medical image segmentation or satellite imagery, enables the development of targeted and accurate models for specialized domains.
Alongside dataset selection, architectural techniques like the encoder-decoder architecture and established models like U-Net, JPU, and DeepLab contribute to achieving accurate and reliable semantic segmentation. However, it is crucial to consider factors like dataset size, task complexity, and available computing resources when utilizing these datasets effectively.
By leveraging the power of semantic segmentation datasets and considering the challenges and considerations in their usage, researchers, and practitioners can push the boundaries of computer vision and continue to advance the field. With careful dataset selection, architectural expertise, and evaluation using appropriate datasets and metrics, the development of highly accurate and robust semantic segmentation models is within reach.
FAQ
What are some of the best datasets for semantic segmentation training?
Some of the best datasets for semantic segmentation training include semantic segmentation datasets, image segmentation datasets, semantic segmentation benchmark datasets, semantic segmentation labeled datasets, semantic segmentation evaluation datasets, semantic segmentation datasets for machine learning, semantic segmentation datasets for deep learning, and open-source semantic segmentation datasets.
What are the commonly used image segmentation techniques and architectures?
Commonly used image segmentation techniques and architectures include the encoder-decoder architecture, U-Net, Joint Pyramid Upsampling (JPU), Gated Shape CNNs, and DeepLab with atrous convolution.
Why are annotated image datasets important for semantic segmentation?
Annotated image datasets are crucial for semantic segmentation as they provide pixel-level annotations and ground truth masks necessary for training accurate segmentation models. Popular annotated image datasets include COCO, ImageNet, PASCAL VOC 2012, and Cityscapes.
What are some recommended object detection datasets for semantic segmentation?
Recommended datasets for object detection and semantic segmentation include the COCO dataset, Open Images dataset, PASCAL VOC 2012 dataset, and Cityscapes dataset. These datasets offer diverse object categories and ample training data for developing robust models.
Which computer vision datasets are commonly used for pre-training deep learning models?
Commonly used computer vision datasets for pre-training deep learning models include ImageNet, CIFAR-10, CIFAR-100, STL-10, MNIST, and Fashion-MNIST. These datasets consist of labeled images spanning various object classes and scenes.
What is involved in creating and converting semantic segmentation datasets?
Creating and converting semantic segmentation datasets involve preparing the images, labeling the objects, and generating pixel-level segmentation masks. Various tools and frameworks are available to assist in this process.
Are there specialized datasets available for specific semantic segmentation tasks?
Yes, there are specialized datasets available for specific tasks such as medical image segmentation datasets, satellite imagery datasets, and aerial imagery datasets. These datasets focus on specific domains and provide valuable resources for training specialized models.
What are some challenges and considerations when using semantic segmentation datasets?
Some challenges and considerations when using semantic segmentation datasets include dataset size, task complexity, and available computing resources. Data augmentation techniques and hyperparameter tuning can also optimize model performance.
How can the performance of semantic segmentation models be evaluated?
The performance of semantic segmentation models can be evaluated using evaluation datasets and metrics. Evaluation datasets provide ground truth annotations for comparison, and metrics like mean Intersection over Union (mIoU) and pixel accuracy quantify the model's performance.
What is the importance of high-quality semantic segmentation datasets in model development?
Access to high-quality semantic segmentation datasets is crucial for training accurate and robust models. These datasets aid in the development and advancement of computer vision algorithms and enable researchers and practitioners to achieve state-of-the-art results.