Complete Guide to LiDAR Point Cloud Annotation for Autonomous Driving
The development of autonomous driving is impossible without high-precision sensor data, among which LiDAR is a key player. With its ability to accurately measure the distance to objects and form a three-dimensional model of the environment, LiDAR provides autonomous vehicles with a detailed view of the scene regardless of lighting conditions.
However, LiDAR data alone is of no value to machine learning algorithms without proper and high-quality annotation. Point clouds need to be described in a structured way, identifying objects, surfaces, and spatial relationships, so that models can learn to recognize traffic situations, predict the behavior of road users, and make safe decisions in real-time.
Key Takeaways
- High-rate laser sensing yields dense 3D data that improves perception beyond 2D images.
- Annotating in three dimensions demands temporal consistency and careful scene navigation.
- Camera fusion reduces occlusion issues and speeds review cycles.
- Coordinate standards and dataset hygiene boost model stability and reuse.
- Practical workflows connect sensing, labeled data, model training, and safe deployment.

Why LiDAR Point Clouds Matter for Autonomous Driving Right Now
The current stage of autonomous driving development is characterized by the transition from experimental prototypes to real commercial solutions. In this context, LiDAR point clouds play a crucial role, as they provide the vehicle with accurate and stable three-dimensional information about the environment.
Unlike cameras, LiDAR does not depend on lighting, shadows, or sun brightness. It enables the determination of the shape, size, and distance to objects with high accuracy, which is crucial for building 3D bounding boxes around cars, pedestrians, and other road users. It is these 3D bounding boxes that underlie spatial perception and collision prediction algorithms.
Another key factor is the increasing complexity of road scenarios. Urban environments with a large number of dynamic and static objects require a deep understanding of the scene. Here, semantic segmentation of LiDAR becomes particularly important, allowing for the classification of each point in the cloud as a road, sidewalk, building, vehicle, or vegetation. This approach provides more reliable traffic planning and decision-making.
The industry is actively moving towards sensor fusion — a combination of LiDAR, camera, and radar data. In this architecture, LiDAR point clouds act as a spatial “framework” on which visual and velocity information from other sensors is superimposed. Without high-quality point cloud labeling, such integration would be impossible or too inaccurate.
Present-day constraints: weather, range, and sensor reliability
Despite significant progress, LiDAR systems for autonomous driving still have several practical limitations that directly impact the quality of environmental perception and the operation of algorithms. Understanding these limitations is crucial for accurately interpreting LiDAR point clouds and constructing reliable sensor fusion systems.
- Impact of weather conditions. Rain, snow, fog, and dust significantly reduce the quality of LiDAR data. Laser beams are reflected from water droplets or snowflakes, creating noise and false points in the cloud. This complicates point cloud labeling, as the boundaries of objects become less clear, and the number of artifacts increases. In such conditions, even the construction of correct 3D bounding boxes requires additional filters and checks.
- Range limitations. Although modern LiDAR can operate at hundreds of meters, the effective range for accurate object recognition is much shorter. At long distances, the density of points decreases, and objects become “sparse” in the cloud. This directly affects the quality of semantic segmentation of LiDAR, as the model does not receive enough information to consistently classify distant objects.
- Reliability and stability of sensors. LiDAR is a complex hardware component that is sensitive to vibrations, lens contamination, and temperature fluctuations. Even minor calibration failures can lead to systematic errors in determining distances. That is why modern autonomous systems rely on sensor fusion, where LiDAR is supplemented with cameras and radars, rather than working in isolation.
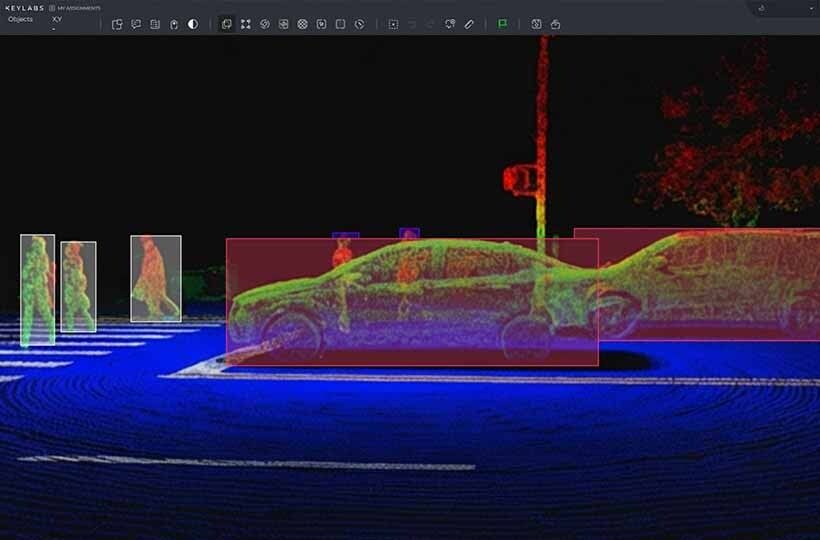
What LiDAR Point Cloud Annotation Involves
CVAT for 3D: Cuboid-First Annotation and Workflow Essentials
CVAT (Computer Vision Annotation Tool) is a popular tool for image and video annotation, also supporting 3D point cloud labeling. In 3D mode, CVAT employs a cuboid-first approach, where the primary element of the annotation is a three-dimensional box, or 3D bounding box, surrounding the objects in the point cloud. This approach enables the rapid creation of basic annotations for autonomous driving algorithms and facilitates their easy integration into sensor fusion systems.
Steps of the cuboid-first workflow in CVAT:
- Import data. Load point clouds in .pcd, .bin, or .las formats.
- Create 3D bounding boxes.
- Select an object in the point cloud.
- Construct a cuboid around the object with precise position, dimensions, and orientation.
- Assign an object class (car, pedestrian, cyclist).
- Point cloud labeling.
- Each cuboid automatically highlights the points that fall into the box.
- Manual adjustment enhances the accuracy of semantic segmentation LiDAR, enabling the classification of points as road, sidewalk, vehicle, or building.
- QA and validation.
- Verify the accuracy of cuboids and the correctness of points.
- Ensure consistency between frames for 4D annotation.
- Export annotations to KITTI, nuScenes, or Waymo formats for training models.
- Tips for efficient work.
- A cuboid-first approach enables quick form basic annotations, saving annotators time.
- Use BEV projections and sliders to more accurately position 3D bounding boxes in space.
- Always perform data validation after the first pass, especially for distant objects and areas with occlusion.
- Combining CVAT with automatic pre-annotation algorithms significantly speeds up the point cloud labeling process.
LATTE: Accelerating Annotation with Sensor Fusion and One-Click Tools
Data Foundations: Datasets, Formats, and Coordinate Systems
Common Challenges in 3D Annotation and How to Handle Them
- Misaligned 3D bounding boxes – the annotator uses BEV projections and automatic hints in point cloud labeling to accurately position the boxes.
- Sparse points at long distances – the system applies noise filters, interpolation, and combines camera data via sensor fusion to improve semantic LiDAR segmentation.
- Occluded or partially hidden objects – the annotator tracks objects between frames (4D annotation) and uses multi-sensor data to reconstruct the full shape of the object.
- Inconsistent annotations between frames or sensors – the team ensures careful sensor calibration and annotation consistency for reliable sensor fusion and tracking.
- Time-consuming manual annotation – the annotator uses automatic pre-annotation, one-click tools, and a cuboid-first workflow to speed up point cloud labeling.
Summary
High-quality annotation of LiDAR point clouds is the foundation for autonomous driving. The use of 3D bounding boxes allows for precise localization of objects, point cloud labeling provides a structured representation of data, and semantic segmentation of LiDAR adds semantic context to each point. The effective integration of different sensors through sensor fusion enhances the accuracy and reliability of systems. Optimal workflows, automated tools, and quality control help speed up annotation, minimize errors, and prepare data for training advanced autonomous driving models.
FAQ
What is the main purpose of LiDAR point cloud annotation in autonomous driving?
LiDAR point cloud annotation provides structured 3D data for training models. It enables accurate 3D bounding boxes, semantic segmentation LiDAR, and object recognition for safe autonomous navigation.
What are 3D bounding boxes used for?
3D bounding boxes define the size, position, and orientation of objects in 3D space. They are essential for object detection and tracking in autonomous driving systems.
What does point cloud labeling involve?
Point cloud labeling assigns semantic or instance-level information to each point in the cloud. This process enables models to understand the environment and differentiate between objects and surfaces.
How does semantic segmentation LiDAR improve scene understanding?
Semantic segmentation using LiDAR classifies each point into categories such as road, vehicle, or pedestrian. It provides detailed scene context for planning, navigation, and collision avoidance.
Why is sensor fusion important in LiDAR annotation?
Sensor fusion combines LiDAR, cameras, and radar data for more accurate perception. It reduces errors caused by sparse points, occlusions, or sensor-specific limitations.
What are the common challenges in 3D annotation?
Challenges include misaligned 3D bounding boxes, sparse points at long distances, occluded objects, inconsistent frames, and time-consuming manual annotation.
What tools are commonly used for LiDAR annotation?
Tools like CVAT (3D mode), LATTE, and commercial platforms offer point cloud labeling, cuboid-first workflows, and one-click creation of 3D bounding boxes.
Why is a cuboid-first approach useful in 3D annotation?
Cuboid-first approaches prioritize creating 3D bounding boxes first, which speeds up annotation and ensures consistency for point cloud labeling workflows.
How does quality assurance improve LiDAR annotations?
QA ensures 3D bounding boxes, semantic segmentation LiDAR, and sensor fusion data are accurate and consistent. It reduces errors and improves the reliability of datasets for model training.
