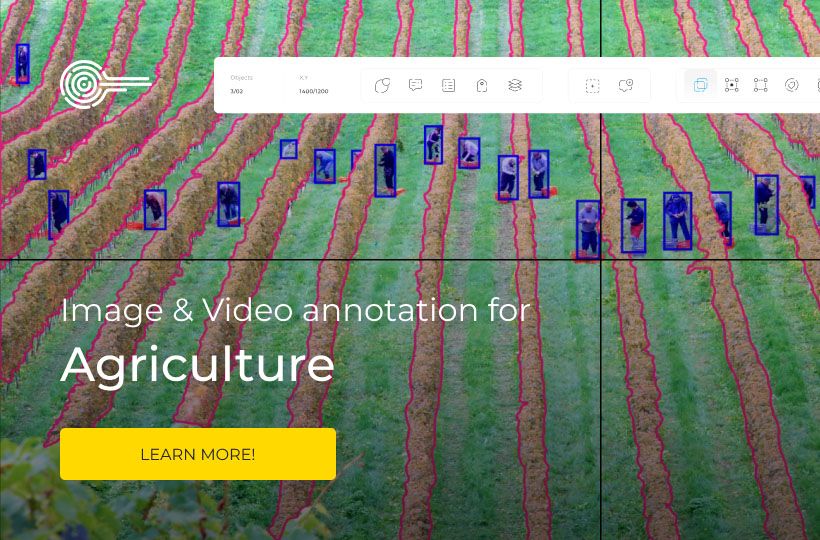
Data Annotation Best Practices for Successful Machine Learning
Flawed algorithms and often poorly structured training materials break AI models before they reach real-world applications.
Teams waste months fixing mislabeled images or conflicting tags because they miss one critical step: defining precise annotation rules up front. Without clear standards, raw information becomes noise. This gap between intent and execution creates costly rework cycles that stall deployment.
High-performing AI models thrive on consistent, human-verified input data, shaped by purpose-built workflows.
Quick Take
- Clarity of annotations impacts AI reliability and speed of deployment.
- Early investment in labeling protocols reduces post-development refactoring.
- Cross-functional team consistency prevents conflicting tagging patterns.
- Specialized tools accelerate quality assurance of training materials.\

Overview of Data Annotation in Machine Learning
Artificial intelligence systems do not interpret raw data intuitively, they need structured instructions to recognize patterns. Artificial intelligence systems do not interpret raw data intuitively, so they rely on structured ML training best practices, including labeling protocols. The foundation is precise labeling protocols that transform chaotic input data into algorithm learning points.
Data Annotation Definition and Its Role in AI
Data annotation is the process of labeling information in raw data to make it understandable to machine learning algorithms. It is an important step in AI development because the quality and accuracy of annotations affect models' effectiveness and reliability. Annotation gives data a structure that allows AI to recognize objects, analyze language, detect anomalies, or make pattern-based decisions. Without high-quality annotated data, no AI model can learn to interpret the real world correctly.
Four main formats dominate this field:
- Text classification for sentiment analysis.
- Boundary constraints in visual recognition systems.
- Timestamp markers in speech-to-text.
- Event tagging in surveillance recordings.
Benefits of machine learning models
Properly executed annotation strategies yield measurable improvements over deployment cycles. Teams that use structured frameworks achieve faster bug resolution than those that rely on ad hoc methods.
Consistent tagging protocols enforce strong annotation standards, reducing rework and ensuring alignment across teams. This accuracy is critical when scaling solutions.
Implementing Data Annotation Practices in Machine Learning Projects
Implementing clear labeling guidelines and annotation rules helps eliminate gaps in annotators' knowledge. This process begins with a clear definition of the project goals, the types of data required, and the criteria for their annotation. It is followed by forming a team of annotators, who are trained to ensure consistency and accuracy of the markup. Implementing clear annotation guidelines to eliminate gaps in annotators' knowledge is equally important.
Three elements distinguish functional guidelines from ineffective ones:
- Visual examples that show edge case interpretations.
- Glossaries that explain industry terminology.
- Cross-references to existing golden datasets.
Choosing appropriate annotation tools that allow you to work effectively with the selected data type and ensure quality control is important. Data validation, regular feedback, and updated instructions should be used throughout the process to avoid discrepancies and maintain high-quality markup. This is achieved by implementing weekly consensus sessions between annotators and engineers to identify new patterns. Automated quality checks detect deviations, and human reviewers assess contextual accuracy. This two-tiered approach ensures that AI models are trained on well-structured input data, rather than on assumptions that are prone to error.
Successfully implementing annotation practices leads to accurate, robust AI models that are better adapted to real-world conditions and provide value for business or scientific purposes.
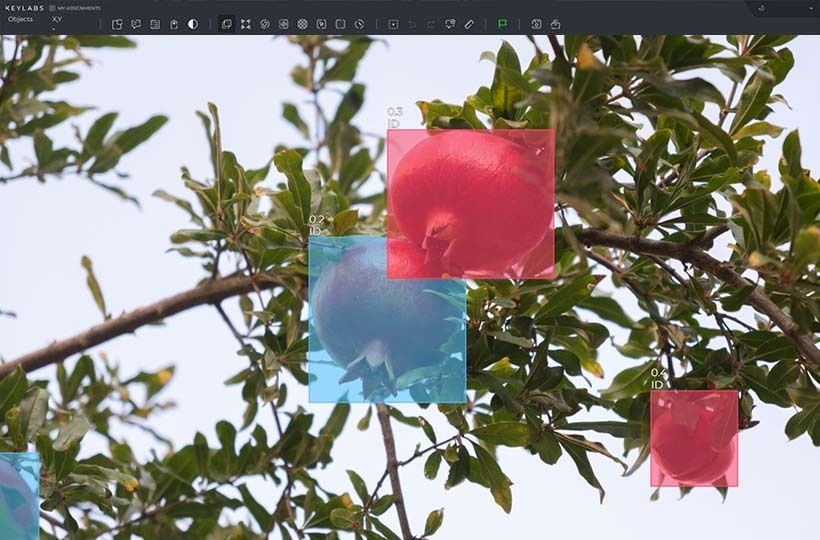
Preparing and Managing Data Annotation Projects
Preparing and managing data annotation projects involves a comprehensive approach that includes careful planning, selecting appropriate tools, and developing clear instructions for annotators. At the initial stage, defining the project goals, the data types to be processed, and the annotation formats that meet artificial intelligence tasks is important. This is followed by preparing a variety of data sets and prioritizing edge cases over volume. Choosing annotation tools best suited to the project's specifics is also essential. The choice of tools focuses on confidentiality, integration capabilities, and ease of use. Effective management includes building a quality control pipeline, regularly updating guidelines, checking the consistency of task execution, and training the team. Also critical is integrating tools for monitoring progress and automating processes, which allows the project to scale without losing accuracy. Proper organization of such processes ensures the creation of high-quality datasets, which are the basis for reliable and fair AI solutions.
Using annotation tools and technologies
Organizations that use specialized annotation tools reduce AI model training time. These tools often include built-in features for data quality assurance, minimizing human error and bias. The right software turns chaotic workflows into streamlined pipelines, especially when performing complex tasks such as video analysis or medical imaging.
Choosing the right annotation tool
Prioritize platforms that meet three criteria: task complexity, team size, and deliverable requirements. Open source options work for basic constraints, while enterprise projects require robust systems with built-in quality checks.
Key differences include:
- Multiple format support for images, video, and sensor data.
- Real-time collaboration features for distributed teams.
- Version control to track annotation iterations.
It's always important to test platforms for specific edge cases before committing.
Workflow Integration and Optimization
Workflow integration and optimization involves high-quality interaction between teams, technologies, and data. It is essential to ensure a seamless combination of the stages of data collection, annotation, validation, and transfer to models. A streamlined annotation workflow ensures seamless collaboration between data engineers, annotators, and QA teams. Optimization is achieved by automating repetitive tasks, implementing tracking systems, quality control, and continuous performance monitoring. This approach allows you to increase project efficiency, reduce implementation time, and ensure consistent quality of annotated data at all stages of the AI system lifecycle.
Ensuring quality control and accuracy
AI models trained on erroneous inputs are ineffective in the real world. To avoid this, multi-level validation protocols are used. Rigorous checks maintain the integrity of the training and its relevance to real-world scenarios. Automatic labeling detects inappropriate labels using statistical benchmarks. Human reviewers then evaluate the labeled elements using consensus scoring.
Edge case and discrepancy handling
Ambiguous scenarios require expert intervention. This is achieved using specialized annotators for complex medical or legal contexts and weekly reconciliation sessions. Edge case modeling in the early stages of testing prevents production errors in computer vision systems.
FAQ
How does clear documentation improve labeling results?
Clear documentation provides a common standard for all annotators, reducing errors and increasing consistency. It also provides a reference point for complex cases and speeds up the decision-making process.
What metrics indicate successful model training?
Successful model training is defined by high accuracy, completeness, predictive accuracy, and F1-measure. Low loss on validation data and stability of results during testing are also considered.
Why should edge cases be prioritized during quality assurance?
Edge cases are the most error-prone AI models because they fall outside standard scenarios. Thoroughly testing them helps improve the reliability and accuracy of AI systems in real-world environments.
When should teams update annotation protocols?
Teams should update annotation protocols when project requirements, data types, or target models change. They should also update when systematic errors or degradation in annotation quality are detected.
How do labeling errors affect computer vision systems?
Labeling errors reduce the accuracy and reliability of computer vision models because algorithms are trained on inaccurate or faulty data. This leads to incorrect object recognition and unsafe decisions in critical applications.