Data Augmentation to Improve Image Classification Accuracy
Data augmentation for image classification artificially augments training datasets by applying various transformations to existing images. This method overcomes the limitations of small datasets and the problem of overfitting in deep learning models, especially convolutional neural networks (CNNs). Data augmentation improves an AI model's ability to handle changes in lighting, viewpoints, and object orientation.
Data augmentation expands the dataset by 10-100, improving an AI model's performance on unseen data. It uses techniques ranging from fundamental geometric transformations to complex generative adversarial networks (GANs) and neural style transfer.
Quick Take
- Data augmentation expands training datasets for better AI model accuracy.
- Data augmentation addresses the issues of overfitting and data limitations in deep learning models.
- Methods include geometric transformations, color correction, and GAN-based methods.
- Data augmentation increases the robustness of AI models to changes in lighting, viewpoints, and object orientation.

Understanding Data Augmentation in Image Classification
Data augmentation is a method of artificially expanding the size of a training dataset by modifying existing examples without changing their essence. This helps improve the accuracy of AI models, avoid overfitting, and diversify training data in tasks with a limited number of them.
Benefits of image classification models
- Better AI model robustness.
- Better performance on real-world data.
- Better generalization capabilities.
These benefits apply when working with limited datasets or unpredictable input data.
Overcoming Overfitting and Data Limitation
Data augmentation expands the training set, allowing AI models to learn to generalize better and avoid memorizing specific examples. This is useful in tasks with small datasets, such as medical image analysis or industrial manufacturing.
Geometric transformations for image enhancement
Geometric transformations include rotation, scaling, translation, and flipping. These methods enrich the training data for image classification models.
Rotation rotates an image through different angles. Scaling changes the size of an image. Translation shifts the image horizontally or vertically. Flipping mirrors the image. These transformations change the positions of objects and angles.
These transformations are included in libraries such as OpenCV or PIL. These libraries have functions for each transformation, making them easy to add to datasets.
Photometric transformations: improving color and lighting
Photometric transformations improve images and colors, change lighting conditions, and make the AI model effective in real-world situations.
Adjusting brightness and contrast helps AI models adapt to different lighting conditions. Brightness changes simulate various lighting levels, and contrast adjusts for differences in pixel intensity. These adjustments help AI systems perform correctly in different visual conditions.
Color dithering methods introduce random color variations. This method distorts colors, making AI models less dependent on specific colors. This method helps AI models recognize objects better under different lighting and colors.
Frameworks such as PyTorch have built-in photometric transformation tools. These tools help you adjust brightness, contrast, and color dithering during data loading or training, improving the performance of AI models under different lighting conditions.
Advanced Addition Methods: Noise and Deformation
Popular methods for adding Gaussian noise and elastic deformation. They increase the robustness of the AI model and generalization capabilities.
These advanced methods are integrated using specialized functions in image processing libraries or creating custom modules within the deep learning framework.
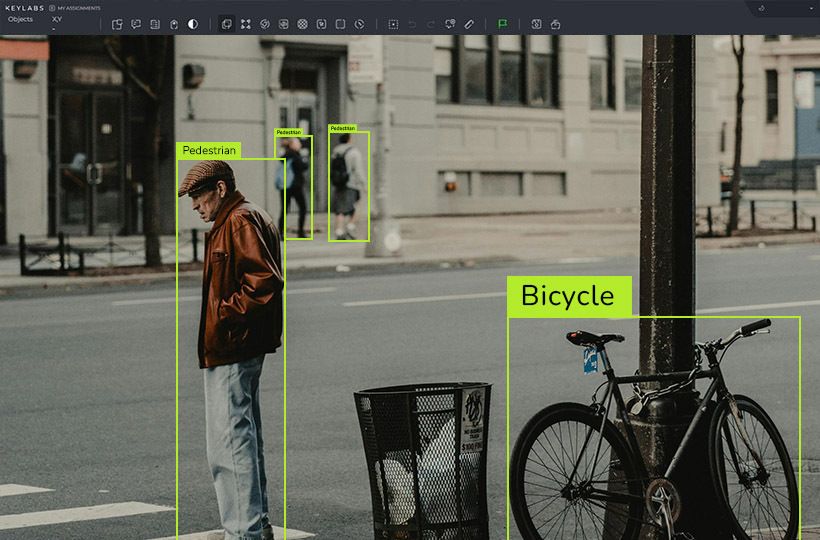
Augmentation Strategies for Image Classification
To optimize an AI model's performance, it is important to find the right balance in the amount of augmentation. Too much augmentation distorts the image beyond recognition, while too little augmentation does not provide enough variability. Experiment with different levels of transformation and monitor the accuracy of the AI model to find the optimal balance.
Combining Multiple Augmentation Methods
Combining different augmentation methods creates a complete training set. Combining geometric transformations such as rotation and scaling with photometric adjustments such as contrast and color jitter will make the AI model more robust in real-world scenarios.
To evaluate augmentation strategies, metrics like classification accuracy and F1 score should be considered. Visualization methods provide valuable insight into how augmentation affects an AI model's training process.
Deep Learning Frameworks for Data Augmentation
Data augmentation in deep learning prevents overfitting and improves the performance of AI models. The TensorFlow and PyTorch frameworks have tools for image augmentation in classification projects.
In TensorFlow, the ImageDataGenerator class augments data during training. It contains various parameters for transformations. Consider this simple example:
- Resizing images using tf.keras.layers.Resizing
- Scaling pixel values using tf.keras.layers.Rescaling
- Random flips are applied using tf.keras.layers.RandomFlip
- Rotating images using tf.keras.layers.RandomRotation
You can also create an augmentation pipeline using the Dataset and DataLoader classes with the PyTorch framework. This method provides flexible data management during training.
The Augmentor, Albumentations, and Imgaug data augmentation libraries have more sophisticated options. These libraries integrate with TensorFlow and PyTorch, have a wide range of transformations, and can create their pipelines.
Generative Adversarial Networks (GANs) for Data Augmentation
GANs use adversarial learning to create synthetic images that resemble real images.
Introduction to GANs in Data Augmentation
GANs consist of a generator and a discriminator. The generator synthesizes images, and the discriminator distinguishes real samples from fake ones. Through the adversarial process, high-quality synthetic data is generated.
Advantages and Challenges of GAN-Based Augmentation
FAQ
What is data augmentation in image classification?
Data augmentation in image classification is a technique of artificially augmenting the training set of images by applying random transformations.
What are the benefits of data augmentation for image classification models?
Data augmentation reduces overfitting and increases the robustness of an AI model. As a result, models become adaptive to unexpected changes and errors.
What geometric transformations are used in data augmentation?
Transformations include rotation, scaling, translation, and reflection.
How do photometric transformations improve data augmentation for image classification?
They improve the color and lighting in images. Techniques such as brightness adjustment, contrast enhancement, and color dithering make AI models robust.
What are the best augmentation techniques for image classification?
Adding Gaussian noise and applying elastic deformations simulate real-world noise and distortion.
How can data augmentation strategies be optimized for image classification tasks?
Strategies involve selecting methods based on the task and the dataset. It is important to balance the amount of augmentation and combine multiple techniques.
How is data augmentation implemented in deep learning frameworks?
The frameworks TensorFlow and PyTorch have built-in or custom augmentation functions. TensorFlow's ImageDataGenerator augments data during training. PyTorch's transform module defines a transformation pipeline for datasets.
What are Generative Adversarial Networks (GANs), and how are they used for data augmentation?
GANs consist of a generator and a discriminator trained in an adversarial manner. They generate synthetic images, remove class imbalance, and provide different samples for augmentation.