Data Labeling for Deep Learning: A Comprehensive Guide
The accuracy of data labeling directly affects AI and machine learning model performance. Deep learning projects rely heavily on accurately labeled datasets. Every task from image labeling to NLP text annotations and video annotation for computer vision is crucial. These tasks ensure models can make precise predictions.
Key Takeaways:
- Data labeling is crucial for the accuracy of AI and machine learning models
- Labeled datasets are especially important for supervised learning projects
- Data labeling involves identifying objects in raw data and tagging them with labels
- The process of data labeling can be done manually or using data annotation services
- Choosing the right data labeling platform or outsourcing can enhance efficiency and quality

Why Use Data Labeling?
Data labeling is key for developing supervised learning models accurately. It establishes the basis for well-labeled datasets. These datasets are vital for training models to process data effectively.
In the fields of autonomous vehicles, digital assistants, and security, annotated data is critical. For instance, in autonomous vehicles, labeled datasets help AI systems identify objects on the road to react for safe driving. Digital assistants, on the other hand, use labeled data to understand and respond better to user commands, improving user interactions.
Through data labeling, we can observe patterns and trends in the data. This helps us evaluate our models, recognize their shortcomings, and refine their accuracy. Data labeling is a key component in the training of models, ensuring they function at their best.
Labeled Dataset Creation
Creating labeled datasets requires a methodical approach. Often, data annotation services or internal resources are used. These tools and experts are critical in correctly labeling various data, from images to texts and videos.
"Accurate data annotation helps autonomous vehicles, digital assistants, and security cameras perform their tasks effectively."
In supervised learning data labeling, human labelers manually annotate data, tagging specific data elements. Despite the rise of AI, manual annotation remains significant. Nowadays, AI-powered platforms can aid in facilitating this process, improving both accuracy and efficiency in dataset creation.
| Benefits of Data Labeling |
|---|
| Enhanced accuracy in model predictions |
| Improved performance of AI systems |
| Realization of the full potential of supervised learning models |
Utilizing supervised learning data labeling ensures our AI systems make more accurate predictions. This leads to superior performance and enables our models to reach their full potential.
How Does Data Labeling Work?
Data labeling is the collection of varying data sets to meet specifics for your modeling needs. This is crucial, whether for natural language processing or projects in computer vision. The accuracy in annotating data is vital. It ensures that your machine learning models are trained effectively.
There are different paths to obtaining labeled data. The manual method is one, involving human labelers to annotate data. This is particularly important in tasks like text annotation for NLP, relying on human expertise.
Open-source datasets, on the other hand, are available to the public and pre-labeled. These are created by researchers or organizations, and they are valuable for training AI models. They are especially useful in computer vision projects that require a wide variety of data, like video annotation.
Creating synthetic data is a unique way to get labeled data. This involves using generative models to mimic real-world settings. It's ideal when gathering real data is tough or time is a constraint.
"Synthetic data generation has transformed our computer vision work. It enables us to build essential large and diverse datasets."
After acquiring the data, labeling it is the next step. Human labelers use a platform to tag and identify specific elements in the data. These platforms allow labelers to label data with ease, improving efficiency and ensuring accuracy.
Putting great care into quality assurance for the labeled data is mandatory. This includes peer reviews, feedback, and checks for quality. These steps help maintain the reliability and usefulness of the dataset.
What Keylabs Offers Your Team
| Features | Benefits |
|---|---|
| Intuitive interface | Easy and user-friendly platform |
| Collaborative tools | Efficient workflow management |
| Quality control mechanisms | Ensures accurate and reliable annotations |
| Advanced reporting | Track progress and performance |
Common Types of Data Labeling
Data labeling is key in different fields, helping machine learning models understand data accurately. There are various labeling methods for tasks, like large language models and computer vision. This section digs into the data labeling in these areas.
Large Language Models
In natural language processing (NLP), large language models need precise data labeling. This labeling helps AI systems grasp human language well. Tasks in NLP focus on tagging and categorizing text elements, boosting language understanding.
Computer Vision
Conversely, computer vision relies on clear, rich training data for spotting things accurately in visuals. In machine learning, labeling images pinpoints and names objects, letting AI recognize and process visual data. Video annotation, on the other hand, involves tagging activities and objects in videos, supporting deep video analysis and automated decisions.
Other Specialized Labeling Tasks
Data labeling goes beyond NLP and computer vision, covering unique areas and needs. In healthcare, labeling might mean marking up medical images or patient records, aiding in diagnosis. In the realm of self-driving cars, it could be marking road elements, making autonomous travel safer.
Using targeted supervised labeling, organizations can build datasets that fuel smart, precise AI solutions.
Best Practices for Data Labeling
Data labeling plays a vital role in creating datasets for supervised learning. Aiming for accuracy and reliability is key. Follow these crucial strategies for effective data labeling:
1. Prioritize Data Privacy and Security:
Opt for a data labeling solution that values data security. The selected platform should employ strong security protocols. This ensures your data is safe from any breaches or misuse.
2. Emphasize Quality over Quantity:
Focusing on the quality of labeled data is paramount. It’s better to ensure precision and accuracy in annotations than to hurry through. This strategy produces datasets that significantly improve machine learning model performance.
3. Consider Domain Expertise:
Labeling tasks in various domains demand distinct subject knowledge. Match your data sourcing method with the necessary expertise. Working with experts in the field or specialized annotation services ensures your labeled data is both accurate and insightful.
4. Evaluate Budget Constraints and Project Timelines:
Deciding on a data labeling approach requires careful consideration of budget and schedule. Outsourcing can be cost-effective, offering speed and expertise. Yet, it might impact your budget. Balancing these aspects is crucial for a successful project.
Adhering to these best practices enhances the quality of your supervised learning model's data. Data labeling, being fundamental, deserves your time and effort. The improvements in dataset accuracy will reflect in the performance of your AI applications.
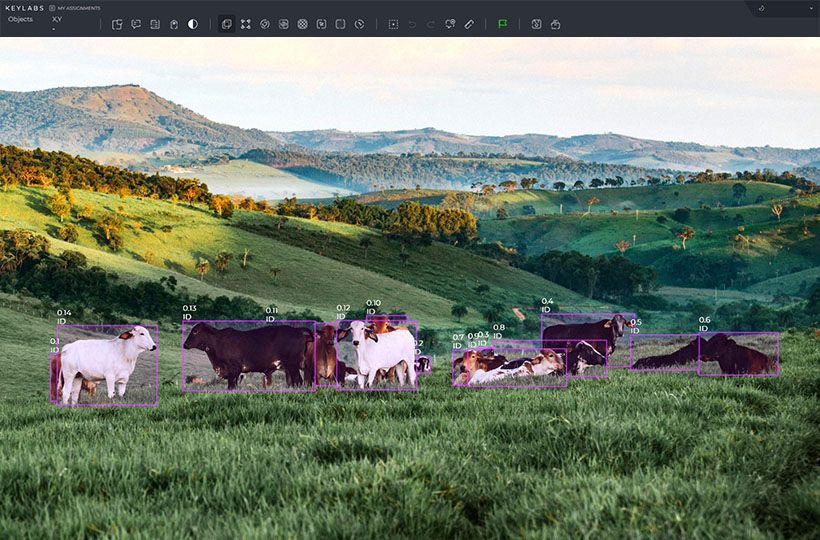
Choosing a Data Labeling Platform
Selecting the right data labeling platform is critical for your AI or machine learning project. To choose wisely, consider factors that meet your project's goals and needs. This guide will walk you through key considerations for picking the best platform for your requirements.
Data Privacy and Security
When deciding, data privacy and security should top your list. Choose platforms that value privacy and follow regulations. Ensure the platform has strong security to keep your data safe from misuse or breaches.
Quality Control
Accuracy and reliability in the labeled data are essential. Pick a platform with strict quality control measures and continuous monitoring. This keeps your datasets reliable and boosts your AI model's performance.
Scalability
Think about whether the platform can grow with your project's size and complexity. It's crucial to select a platform that can scale to fit your changing needs, no matter the project's scope.
Cost-Effectiveness
Budget is a key factor in your decision-making. Compare the pricing structures of different platforms against your project's budget. Don't forget to look at the value they bring, in terms of accurate and efficient data labeling.
Domain-Specific Expertise
Some projects might need specific expertise, like natural language processing (NLP) or computer vision. Consider if your project requires this specialized knowledge. Having experts in your project's area could significantly improve the labeled data's quality.
Choosing the right data labeling platform is pivotal for the success of AI and machine learning projects. Key factors to consider include data privacy, security, quality control, scalability, and cost-effectiveness. Ensure your decision aligns with your project's specific requirements and goals.
Features to Consider when Choosing a Data Labeling Platform
| Factors | Description |
|---|---|
| Data Privacy and Security | Ensure the platform complies with industry regulations and provides robust security measures to protect your data. |
| Quality Control | Look for platforms that implement stringent quality control processes to ensure the accuracy and reliability of labeled data. |
| Scalability | Consider the platform's ability to handle the size and complexity of your project. |
| Cost-Effectiveness | Evaluate the pricing structure of different platforms and assess their value in relation to your project's budget constraints. |
| Domain-Specific Expertise | Assess whether the platform offers domain-specific expertise in areas such as NLP or computer vision. |
Outsourcing Data Labeling
Choosing to outsource data labeling for deep learning projects can prove to be advantageous. Specialized companies such as Keymakr speed up your labeling process through their data annotation services. They ensure top-notch results by employing experienced labelers who provide precise annotations.
Outsourcing grants you access to the strict quality control followed by these companies. They maintain accuracy and consistency using established protocols and standards. Their focus on detail and quality promises a dataset you can trust.
Companies that specialize in this arena also bring deep expertise and domain knowledge to the mix. Their wide-ranging experience across industries equips them to tackle any labeling task, be it image annotation or text annotation. This guarantees your specific needs are met.
Active Learning and Semi-Supervised Techniques
Active learning and semi-supervised techniques offer efficient paths to minimize the need for labeled data in supervised learning. They follow a method of selecting data points for labeling that is both iterative and informative. This ultimately lessens the costs tied to creating labeled datasets.
Active learning shines when labeled data is scarce. It picks out specific examples from the unlabeled pool to add value to model training. Such an approach optimizes the labeling process, focusing on the toughest or most ambiguous cases. This is where human expertise makes a real difference.
Using active learning, models become more knowledgeable by strategically adding labels. This guides the selection of unlabeled items to capture key data features more accurately.
Semi-supervised techniques blend labeled and unlabeled data for model training. They tap into a large pool of unlabeled data, making efficient use of scarce labels. This way, these methods cut down on the resources needed for creation of labeled datasets.
Note: These methods work wonders in scenarios with little labeled data or tight time and budget constraints.
Differences and Benefits
Active learning and semi-supervised techniques, though alike in curbing the need for large labeled datasets, operate differently and offer distinct advantages. Active learning focuses on precise selection of data for labeling, whereas semi-supervised methods use both labeled and unlabeled data.
Their benefits include:
- Lessening manual labeling by pinpointing most critical data for annotation.
- Maximizing resource efficiency using both labeled and unlabeled data.
- Boosting model performance by targeting complex data patterns and variations.
Example Use Cases
These techniques are widely applicable, with examples like:
- In image classification, active learning spotlights tricky images needing human insight, aiding complex feature recognition.
- For text classification, semi-supervised methods blend few labeled documents with many unlabeled, fostering strong models.
- In speech recognition, active learning improves transcription by focusing on hard-to-translate samples.
| Active Learning | Semi-Supervised Techniques |
|---|---|
| Focuses on selecting informative instances from the unlabeled dataset. | Combines labeled and unlabeled data for model training. |
| Reduces manual labeling effort by optimizing instance selection. | Leverages unlabeled data to reduce resource requirements. |
| Enhances model performance by capturing crucial patterns. | Makes effective use of available data to improve model accuracy. |
Together, active learning and semi-supervised methods are changing the game in labeled dataset creation. This leads to better resource use and model accuracy.
Continue reading: Using ML-assisted data labeling in your process
Conclusion
Acquiring top-notch labeled data is vital for supervised learning success and for forming precise datasets in deep learning work. The accuracy and trustworthiness of labeling affects how well AI and machine learning models perform.
When picking a strategy for data labeling, certain aspects must be weighed. These include the data's quality and the expertise of the labelers, along with its cost-effectiveness and data security. Choosing the correct data sourcing method and obtaining top-quality labeled data powers your AI and machine learning projects with essential information.
Accurate datasets lead to better model function and predictions.
FAQ
What is data labeling for deep learning?
Data labeling stands critical in the realm of machine learning. It tasks users with identifying objects within raw data. Then, it requires the categorization of these objects with specific labels. This process fine-tunes algorithms for more accurate predictions and analyses.
Why is data labeling important?
For supervised learning models, a foundation of labeled datasets proves invaluable. These datasets arm the models with the capability to comprehend the input data they receive.
How does data labeling work?
The initial step is data collection, ensuring diversity and relevant quantity. Humans are then tasked with annotating this data. A data labeling platform provides the interface for this annotation.
What are the common types of data labeling?
Common categorizations for data labeling include large scale language models and computer vision. These categories also encompass other, more specialized labeling tasks. The choice depends largely on the project's needs.
What are the best practices for data labeling?
Key practices in data labeling focus on quality rather than volume. Integrating experts in the relevant field for labeling can significantly improve the process. Also, it's crucial to take into account budget constraints and project deadlines.
How do I choose the right data labeling platform?
In selecting a platform for data labeling, essential considerations include privacy, quality control, and scalability. The platform's adherence to industry regulations is important. Look for platforms that grant you autonomy over your data.
Should I outsource data labeling?
Outsourcing data labeling can provide several benefits. These include process efficiency, high quality of data, and domain-specific expertise. However, it involves finding the right partner to handle your data for you.
What are active learning and semi-supervised techniques in data labeling?
Active learning and semi-supervised techniques revolutionize data labeling. They focus on selecting the most impactful data points for labeling in an iterative fashion. This minimizes the required labeled data volume for training.
