Data Labeling vs Data Annotation: Key Differences Explained
The terms "data labeling" and "data annotation" are often used interchangeably, yet they reflect different facets of how raw data is prepared for training models. As industries increasingly rely on automated systems to interpret complex visual, textual, and auditory inputs, the processes that shape training data have come under closer scrutiny whether tagging objects in an image or segmenting audio clips by speaker, both labeling and annotation play essential roles, but understanding how they differ can reveal a lot about the workflows, tools, and quality standards behind AI development.
Understanding Data Labeling
Data labeling is assigning predefined tags or categories to raw data so that machine learning models can learn from it. This typically involves identifying specific features within the data, such as objects in an image, sentiment in a sentence, or events in a video. Labels are often binary or categorical, depending on the task, and are used to train supervised learning algorithms. The goal is to create structured inputs that help models make accurate predictions when exposed to new, unseen data.
Labeling can be performed manually by human annotators or automatically using pre-trained models, depending on the complexity and scale of the task. Labelers usually work with detailed guidelines to ensure uniformity across large volumes of data. Common steps in the data labeling process include:
- Data selection – choosing representative samples for labeling.
- Labeling task definition – specifying what labels are needed and how they should be applied.
- Annotation – applying the labels to the data using tools or platforms.
- Review and validation – checking for consistency and correcting errors.
- Finalization – preparing the labeled dataset for use in model training.

The Engine of Supervised Learning
Machine learning models have no guidance for understanding patterns or making predictions without labeled data. Labels act as ground truth, enabling algorithms to map inputs to correct outputs and gradually improve accuracy. The quality and consistency of these labels directly influence how well a model performs, especially when deployed in real-world scenarios. In that sense, data labeling is the core mechanism that drives learning in supervised systems.
High-performing AI applications, from recommendation engines to diagnostic tools, rely on meticulously labeled datasets to function reliably. This has made data labeling a technical task and a strategic one involving decisions about label granularity, workforce management, and quality assurance.
Practical Implementation Strategies
Implementing data labeling effectively requires more than just assigning tags to data; it involves planning, infrastructure, and quality controls tailored to the use case. The first step is defining clear labeling guidelines that align with model objectives and reduce ambiguity for annotators. Depending on the complexity and scale, teams might combine manual labeling with automated pre-labeling to balance efficiency and precision.
A practical strategy often includes the following key steps:
- Define labeling objectives – identify what the model needs to learn and determine the labels required.
- Develop clear guidelines – create documentation with examples and edge cases to ensure consistency among annotators.
- Select the right tools – use platforms that support version control, quality checks, and scalable workflows.
- Train and manage annotators – onboard labelers with training sessions and continuous feedback to maintain high performance.
- Monitor quality and adapt – track metrics like agreement rates and labeling speed, and refine processes as needs evolve.
For sensitive or high-risk domains, multi-pass reviews and consensus labeling can improve reliability and reduce data noise. Labeling pipelines should be designed to evolve as data types shift or model requirements change.
Understanding Data Annotation
Data annotation is the broader process of adding context or meaning to raw data so that machines can interpret it correctly. Unlike labeling, which often involves assigning predefined tags, annotation can include activities like highlighting text spans, drawing bounding boxes, transcribing speech, or segmenting video frames. It provides the structural cues that enable machine learning models to understand what something is and where and how it appears.
Annotation workflows vary widely depending on the domain and data type. In NLP tasks, annotators might tag entities, relationships, or sentiment, while in computer vision, they might trace object boundaries or mark keypoints. Teams may implement review loops, use model-assisted annotation, or apply hierarchical schemas to handle edge cases.
Annotation Process
The annotation process typically involves several coordinated steps:
- Define the annotation task – determine what information needs to be extracted or marked up, based on model requirements.
- Prepare annotation guidelines – create detailed instructions, examples, and decision rules to guide annotators.
- Use specialized tools – choose platforms that support the specific annotation type, such as bounding boxes, segmentation, or text markup.
- Annotate and review – have trained annotators add metadata to the data and review it for consistency and accuracy.
- Refine and finalize – resolve ambiguities, handle edge cases, and prepare the annotated dataset for training or evaluation.
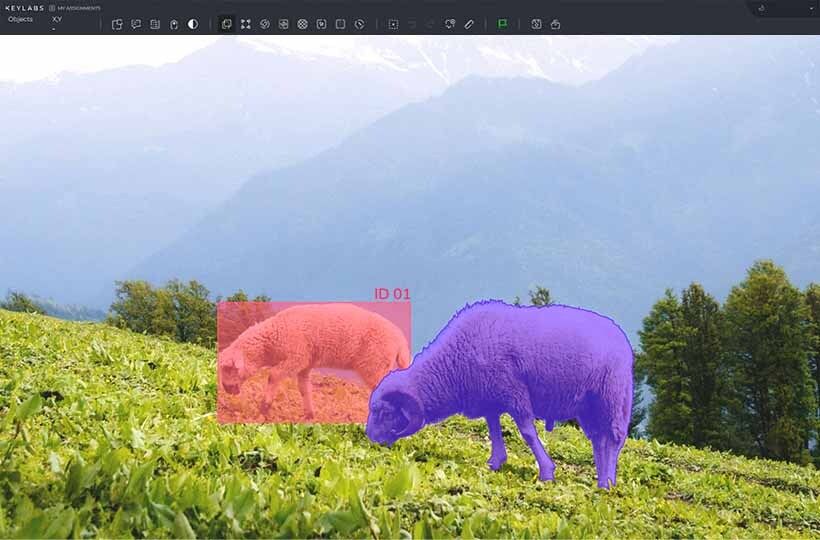
Annotation Techniques
Data annotation techniques vary based on the type of data being used and the complexity of the task. In natural language processing, standard techniques include named entity recognition (NER), where specific words or phrases are tagged as people, organizations, or locations, and part-of-speech tagging, which identifies the grammatical role of each word in a sentence. For computer vision, techniques like bounding boxes, polygon annotation, and semantic segmentation are used to identify and localize objects within images. In audio data, annotation may involve transcription, speaker diarization, or marking sound events like alarms or background noise. Each technique adds a different layer of context, helping models extract patterns and relationships from raw inputs.
The choice of technique depends on the model's intended use and the precision required. Some tasks, like face detection, may need only bounding boxes, while others, like autonomous driving, require pixel-level segmentation and labeling of multiple object classes. Many teams use a combination of manual annotation, automated pre-annotation, and review loops to strike a balance between speed and accuracy. Advanced tools often support multi-format data and offer features like real-time feedback, hierarchical tagging, and automated quality checks.
Comparative Analysis: data labeling vs annotation
Scope:
- Labeling typically involves assigning simple, predefined tags or categories to data points.
- Annotation encompasses a broader set of activities, including adding detailed metadata, drawing shapes, or marking relationships within the data.
Complexity:
- Labeling is generally more straightforward and focused on classification tasks.
- Annotation often requires more detailed and nuanced work, such as outlining objects in images or tagging entities in text.
Use Cases:
- Labeling is commonly used for sentiment analysis, image classification, or binary categorization.
- Annotation supports complex tasks like object detection, semantic segmentation, named entity recognition, and speech transcription.
Tools and Techniques:
- Labeling can be done with simpler interfaces, often by clicking or selecting tags.
- Annotation requires specialized tools that support drawing, segmenting, transcribing, or hierarchical tagging.
Output Detail:
- Labeling results in high-level tags or categories attached to data samples.
- Annotation produces rich, structured metadata with spatial, temporal, or contextual information.
Impact on Model Training:
- Labels provide the basic "answers" that supervised learning models rely on.
- Annotations give models deeper context, enabling more precise understanding and complex decision-making.
Quality Assurance:
- Labeling quality checks focus on consistency and correctness of category assignment.
- Annotation requires additional validation layers to ensure detailed accuracy, especially in complex or multi-step tasks.
Scalability:
- Labeling can often be scaled quickly with semi-automated tools or crowdsourcing.
- Annotation tends to be more resource-intensive, sometimes requiring expert knowledge and multi-pass reviews.
Key Differences in Complexity
Task Detail:
- Data labeling usually involves applying straightforward tags or categories to entire data points.
- Data annotation requires detailed, often multi-dimensional input such as drawing boundaries, marking relationships, or adding context within the data.
Skill Level:
- Annotators can often perform labeling with minimal training, as it involves selecting from predefined options.
- Annotation frequently demands specialized knowledge or training, especially for medical imaging or linguistic tagging tasks.
Time Investment:
- Labeling tasks are generally quicker to complete since they focus on assigning single or limited labels per data item.
- Annotation tasks take longer due to their intricate nature and the precision needed, such as outlining objects or transcribing speech.
Tool Requirements:
- Labeling often uses simpler interfaces, like dropdown menus or checkboxes.
- Annotation requires advanced tools that support features like polygon drawing, multi-layer tagging, or audio waveform editing.
Quality Control Complexity:
- Labeling quality checks focus on verifying the correctness of assigned categories.
- Annotation quality control involves multiple review stages, cross-validation, and handling ambiguous or edge cases to ensure detailed accuracy.
Summary
The complexity differences between data labeling and annotation affect how each process is planned and executed. Data labeling generally involves applying simple, predefined tags or categories to data, making it a faster and more straightforward task that can be completed with minimal training and basic tools. In contrast, data annotation encompasses various activities, such as drawing precise boundaries, adding contextual information, or marking relationships within the data. This makes annotation more time-consuming and demanding, requiring specialized skills, advanced software, and multiple quality control steps to ensure accuracy.
FAQ
What is the central role of data labeling in machine learning?
Data labeling assigns predefined tags or categories to raw data, creating structured inputs that supervised learning models use to make accurate predictions.
How does data annotation differ from data labeling?
Annotation is broader and involves adding detailed metadata, such as drawing boundaries or marking relationships, while labeling mainly focuses on applying simple tags or categories.
Why is data labeling considered the engine of supervised learning?
Because it provides the ground truth that models learn from, guiding algorithms to map inputs to correct outputs and improve accuracy.
What are standard data annotation techniques in computer vision?
Techniques include bounding boxes, polygon annotation, and semantic segmentation, which help precisely identify and localize objects within images.
What types of annotation are common in natural language processing (NLP)?
Named entity recognition, part-of-speech tagging, and text classification are frequently used to add linguistic context and structure to text data.
How does complexity differ between labeling and annotation tasks?
Labeling is more straightforward and quicker, often involving basic category assignment, while annotation is more detailed, requiring specialized skills and precise input like drawing or transcribing.
What tools are typically needed for data annotation compared to labeling?
Annotation demands advanced tools that support drawing, multi-layer tagging, or audio editing, whereas labeling can be done with simpler interfaces like dropdown menus or checkboxes.
How do quality control processes vary between labeling and annotation?
Labeling quality checks focus on consistency of category assignment, while annotation requires multiple review rounds and handling of ambiguous cases to ensure detailed accuracy.
What strategies improve the efficiency of data labeling?
Combining manual labeling with automated pre-labeling, clear guidelines, and workforce training can balance speed and precision.
Why is understanding the differences between labeling and annotation important for AI projects?
It helps select the appropriate approach, tools, and resources to match project goals, data types, and desired model accuracy, ultimately enhancing training effectiveness and outcomes.