Enriching Annotations with Metadata: Adding Context to Your Labels
Enriching annotations with metadata means including additional information in the labels to provide a deeper understanding of the data they describe. This goes beyond basic tagging and includes relevant contextual details such as time, location, or source information. Metadata can cover various elements, from environmental factors and user interaction to technical parameters, all contributing to a richer and more complete picture.
In practical applications, adding metadata is particularly useful when working with complex or heterogeneous data sets, as it offers a way to capture nuances that simple labels might miss. For example, in image recognition projects, information about lighting conditions or camera settings can show why certain features look the way they do, helping algorithms distinguish subtle differences. Significantly, including metadata does not fundamentally change the labeling process but encourages a conscious expansion of what is recorded alongside each data point.
Key Takeaways
- Automated business term assignments ensure governance compliance.
- Machine learning models reduce manual classification efforts.
- Self-service access boosts cross-team collaboration.
- Enhanced search precision drives faster insights.
- Quality metrics transform raw inputs into trusted assets.

Understanding the Fundamentals of Data Annotation and Enrichment
Data annotation is the process of labeling raw data to make it understandable and usable for machine learning models, and it serves as the basis for many AI applications. It involves identifying and labeling relevant features in data sets, whether images, text, audio, or video, so that algorithms can learn to recognize patterns and make predictions. While basic annotation focuses on assigning simple labels, enrichment adds additional information, or metadata, that provides context and depth to those labels. This extra layer helps create more informative data sets that better reflect the complexity of the real world, allowing models to learn from the data and the conditions or nuances surrounding it.
Essentially, enrichment involves supplementing labels with additional details, such as timestamps, location information, sensor settings, or notes about user behavior, depending on the nature of the data. For example, in natural language processing, metadata about the author or publication date can influence the understanding of text. At the same time, in computer vision, lighting or camera angles can explain variations in the appearance of an image. Thus, enrichment bridges raw data and more complex understanding, an embedding context that basic labels alone cannot convey.
Defining Contextual Tagging and Its Business Value
Contextual tagging refers to adding meaningful, situation-specific information to data labels, allowing those labels to carry more than an identifier. Instead of labeling data points with basic tags, contextual tagging includes details about the environment, conditions, or background surrounding each item. This approach helps create a richer, more nuanced data set that reflects the complexity of the real world, making it easier for machines and humans to interpret the information correctly.
From a business perspective, contextual tagging offers several benefits that can improve decision-making and operational efficiency. For example, it allows companies to gain deeper insights by understanding the data and the circumstances under which it was created or collected. This additional dimension can reveal trends, patterns, or anomalies that might otherwise remain hidden, leading to more informed strategies and actions. It also helps with compliance and risk management by tracking relevant factors affecting data reliability or relevance.
Driving AI Accuracy Through Strategic Labeling
Strategic labeling takes into account the structure of the dataset, the goals of the model, and the types of errors that are most costly or common, aiming to guide the training of the model in a targeted manner. Rather than treating all labels equally, this method emphasizes labeling decisions most likely to impact model performance, such as edge cases, ambiguous examples, or rare classes. By focusing on the most informative or influential data points, teams can improve the efficiency of model training and generalization without exponentially increasing the amount of labeled data.
In many cases, models perform poorly not because of a lack of data but because of inconsistently or ambiguously labeled data or because the labeled examples do not reflect the diversity of real-world scenarios. Strategic labeling helps to correct this by identifying gaps or imbalances in the dataset and addressing them through targeted annotation efforts. This can include adding examples highlighting subtle differences between similar categories or ensuring that boundary conditions are adequately represented.
For enterprises and research groups, strategic labeling results in faster development cycles, reduced labeling costs, and models that perform more reliably during deployment. Rather than labeling every data point the same way or at the same pace, teams can allocate resources more intelligently by prioritizing high-impact examples and using metadata or contextual cues to guide labeling decisions.
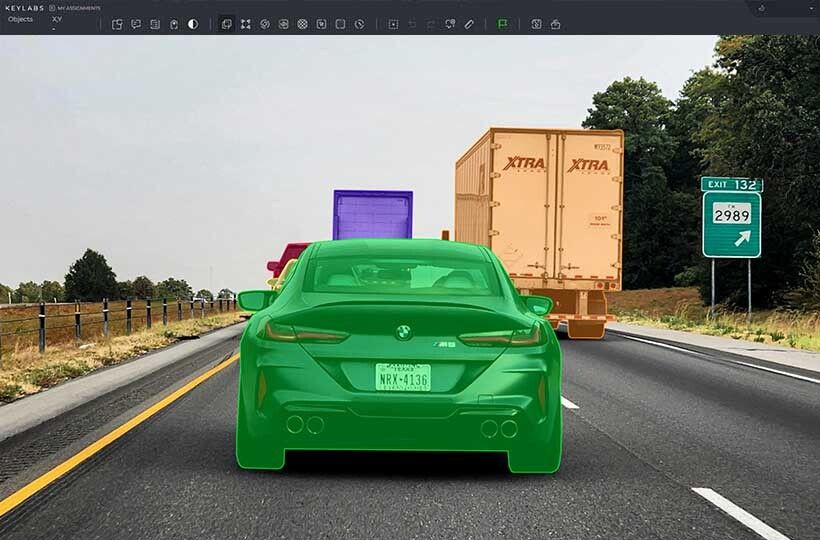
Implementing Metadata Enrichment Techniques in Practice
Implementing metadata enrichment techniques in practice involves embedding additional layers of context into existing annotations through a structured yet flexible process that adapts to the specific needs of the dataset and project. The first step often involves determining which metadata fields will be relevant and valuable, such as timestamps, device specifications, user demographics, or environmental conditions, based on the model's goals and the data's nature. Once these fields have been identified, enrichment can be performed manually during the annotation process, automatically using scripts or semi-automatically using tools that extract metadata from file properties or external sources. This metadata is then stored along with the underlying tags, typically in structured formats such as JSON or CSV, to ensure compatibility with subsequent tools and systems.
In real-world workflows, metadata enrichment can be integrated into existing annotation platforms through custom fields, plugin extensions, or automated preprocessing steps that add context before annotation begins. For example, image data collected from mobile devices can automatically include location and sensor data that can be extracted and added to the dataset without manual input. In more domain-specific scenarios, such as healthcare, manufacturing, or autonomous systems, metadata can come from internal logs, expert notes, or synchronized sensor readings that must be analyzed and matched to relevant data points.
Proper documentation, clear instructions, and consistent quality checks help ensure not only that metadata is available but also that it is accurate and relevant across the entire dataset. Whether used for training, validation, or analysis, rich annotations provide additional dimensions that enable more targeted behavior modeling and informed decision-making.
Step-by-Step Guide to Enrich Your Data with Metadata
- Clarify project goals. Every metadata enrichment process begins by defining the goals it needs to serve. These goals help determine what contextual information is useful and what metadata types will provide meaningful value. Depending on the application, this may include improving model accuracy, providing better filtering, or supporting interpretability.
- Select contextual metadata fields. After defining the goals, the next step is determining which metadata fields are most relevant to the dataset. These may include timestamps, geographic location, device identifiers, user types, or other domain-specific descriptors. Each selected field should be clearly defined to ensure consistency across the dataset.
- Develop a structured storage format. To support integration and reuse, metadata should be stored in a clear, structured format, such as JSON, CSV, or a relational database. This format should allow for easy association between each data point and the corresponding metadata without disrupting the annotation process. Following standardized naming conventions and maintaining compatibility with existing tools or data infrastructure is essential.
- Implement metadata collection methods. Depending on the data source, metadata can be obtained through automated extraction, manual input, or a hybrid. Automated pipelines are appropriate when metadata is embedded in file headers, logs, or sensor data, while manual input may be necessary for contextual details not available through automated means. Clear annotation instructions and input interfaces help ensure reliability when using manual enrichment.
- Verify and monitor metadata integrity. Once metadata has been added, verifying its completeness, consistency, and compliance with planned definitions is essential. Validation may include automated scripts to flag anomalies, regular spot checks, or comparisons with known data sources. Ongoing monitoring ensures that metadata meets quality standards as the dataset grows.
Integrating Business Context and Quality Assessments
Integrating business context and quality assessment into the annotation process involves aligning data enrichment efforts with the practical goals and performance expectations specific to the organization or domain. Rather than viewing metadata labeling and enrichment as separate technical steps, this approach links them to the broader goal of creating and using a dataset. The business context may include regulatory considerations, operational constraints, customer behavior analysis, or product-specific nuances that influence how data should be labeled and interpreted.
Quality assessment, in turn, becomes a way to assess whether annotation and metadata enrichment meet technical and business expectations. This involves verifying the consistency, completeness, accuracy, and relevance of data points labeled and enriched using domain-aware benchmarks or validation workflows.
Summary
Integrating business context and quality assessments into data annotation ensures that labels and metadata are technically accurate and meet the organization's real-world needs and goals. Datasets become more relevant and actionable by incorporating practical considerations such as regulatory requirements, user behavior, or domain-specific nuances into the labeling process. Quality assessments further support this consistency by verifying annotations' consistency, completeness, and usefulness through automated checks and expert reviews. Together, these practices make annotation a strategic, iterative process that contributes to building robust and context-aware AI systems.
FAQ
What does it mean to integrate business context into data annotation?
It means aligning labels and metadata with real-world conditions, such as operational goals, regulatory needs, or customer behavior. This ensures that annotated data reflects the environment in which it will be used.
Why is business context important during the annotation process?
It helps prevent mismatches between data and model use cases, improving the relevance and reliability of predictions. Contextual alignment also supports better decision-making based on the model's output.
What role do quality assessments play in metadata enrichment?
They verify that annotations and metadata are accurate, consistent, and complete. Quality assessments help maintain dataset integrity and reduce downstream errors.
How can quality be assessed in enriched annotations?
A mix of automated validation tools and manual review by domain experts allows for both broad checks and in-depth context-specific evaluations.
What types of business context might be added during annotation?
Examples include compliance rules, usage scenarios, target user profiles, or environmental conditions. These factors shape how data should be labeled and interpreted.
How does business context affect model performance?
It makes the training data more representative of real-world conditions, leading to more accurate and adaptable models. This also improves generalization in deployment.
Who is responsible for ensuring annotations reflect the business context?
This usually involves collaboration between annotators, data scientists, and domain experts. Each contributes knowledge to make the dataset more meaningful.
Why should annotation be seen as an iterative process?
Real-world needs evolve, and model feedback often reveals new requirements or errors. Iterative annotation allows teams to refine labels and metadata over time.
How do quality assessments support collaboration across teams?
They provide a shared standard for evaluating data, making communicating and coordinating between technical and non-technical stakeholders easier. This builds trust in the dataset.
What is the overall benefit of combining business context with quality assessments?
It produces training data that is both technically sound and practically relevant. This leads to more reliable AI systems that better serve their intended purpose.