Feature Engineering for Better Precision
Data scientists often spend up to 80% of their time on feature engineering. It's essential for data preprocessing and machine learning optimization, serving as the foundation for successful models.
Feature engineering converts raw data into actionable insights, thereby improving model accuracy and simplifying complex data transformations. It enhances predictive power across various learning tasks. This process is crucial for effectively addressing real-world business challenges.
The art of feature engineering encompasses several key steps: feature creation, transformations, extraction, exploratory analysis, and benchmarking. Each step is vital for refining data for superior model performance. Delving into feature engineering reveals its capability to uncover hidden patterns and relationships in your data.
Key Takeaways
- Feature engineering significantly improves model accuracy
- It simplifies complex data transformations
- Creates new variables for both supervised and unsupervised learning
- Enhances predictive power in machine learning models
- Crucial for addressing real-world business problems
- Involves multiple processes from creation to benchmarking

Understanding Feature Engineering in Machine Learning
Feature engineering is essential in machine learning. It transforms raw data into features that enhance model performance. This process is crucial for developing accurate and efficient models.
Definition and Importance
Feature engineering selects, manipulates, and transforms data to boost model accuracy. It bridges the gap between raw data and the final model. By creating relevant features, models can better detect patterns and predict outcomes.
Role in Improving Model Accuracy
Effective feature engineering enhances model efficiency and pattern detection. It facilitates better data fitting and increases flexibility. In both supervised and unsupervised learning, it significantly improves model performance.
Common Challenges in Feature Engineering
Feature engineering faces several challenges, including:
- Handling missing data
- Encoding categorical variables
- Scaling features
- Creating new features
- Reducing dimensionality
Overcoming these challenges is vital for successful feature selection and extraction. It's an iterative process requiring experimentation and continuous refinement to identify the optimal feature set for precise predictions.
| Feature Engineering Task | Importance | Impact on Model Performance |
|---|---|---|
| Data Cleaning | High | Improves data quality |
| Feature Selection | Medium | Reduces input complexity |
| Feature Extraction | High | Captures complex relationships |
| Feature Scaling | Medium | Enhances algorithm performance |
The Fundamentals of Data Preprocessing
Data preprocessing is essential for effective feature engineering. With 59 zettabytes of data created in 2020, the significance of data cleaning is immense. Data scientists dedicate 80% of their time to preparing data, underscoring its critical role.
Handling missing values is a common challenge in real-world datasets. Techniques like mean, median, or mode can impute these gaps, maintaining the dataset's integrity. Feature scaling is equally vital, addressing the disparity in value ranges across different columns.
When dealing with high-dimensional data, dimensionality reduction techniques are indispensable. These methods reveal hidden patterns and enhance model efficiency. Principal Component Analysis (PCA) and t-SNE are among the most popular approaches.
"Data preparation is the key to unlocking the full potential of your machine learning models."
Outlier detection and treatment are crucial in data preprocessing. Outliers, which deviate significantly from the norm, can be spotted using standard deviation or percentile methods. Depending on the situation, these outliers might be removed or capped to maintain data quality.
| Preprocessing Step | Technique | Purpose |
|---|---|---|
| Data Cleaning | Imputation | Handle missing values |
| Feature Scaling | Min-Max Scaler | Normalize feature ranges |
| Dimensionality Reduction | PCA | Reduce feature space |
| Outlier Treatment | Capping | Manage extreme values |
By excelling in these fundamental data preprocessing techniques, you can notably improve your data quality and machine learning model performance.
Feature Selection Techniques
Selecting the right features is key to effective machine learning model development. Feature selection enhances model precision, minimizes overfitting, and accelerates training. We'll delve into three primary techniques: filter, wrapper, and embedded methods.
Filter Methods
Filter methods employ Statistical Methods to evaluate Feature Importance. They assess features by their correlation with the target variable. This approach is swift and suitable for large datasets.
- Correlation coefficients
- Chi-square test
- Information gain
Wrapper Methods
Wrapper methods evaluate feature subsets using a specific machine learning algorithm. They are more resource-intensive but often produce superior results. Notable wrapper techniques include:
- Forward selection
- Backward elimination
- Recursive feature elimination
Embedded Methods
Embedded methods integrate feature selection with model training. They use Model-Based Selection to assess Feature Importance during the learning process. Examples include:
- LASSO regression
- Random forest importance
- Gradient boosting feature importance
| Method | Speed | Accuracy | Interpretability |
|---|---|---|---|
| Filter | Fast | Moderate | High |
| Wrapper | Slow | High | Moderate |
| Embedded | Moderate | High | Moderate |
The choice of feature selection technique hinges on your dataset size, computational resources, and specific needs. By applying these methods, you can improve your models and extract valuable insights from your data.
Feature Extraction: Uncovering Hidden Patterns
Feature extraction is a crucial technique in data science that reveals hidden patterns within your data. It transforms existing features into new ones, boosting your model's performance while simplifying computations. Let's delve into some of the top methods employed in this process.
Principal Component Analysis (PCA) stands out as a leading technique for reducing data dimensionality. It redefines your data in a new coordinate system, focusing on the most critical information. This method is invaluable for identifying the most influential features in your dataset, simplifying complex data visualization and analysis.
For text data, Latent Dirichlet Allocation (LDA) is a preferred choice. It excels in topic modeling, uncovering the underlying themes within large document collections. LDA is instrumental in revealing hidden structures in text data, offering profound insights for applications such as content categorization or recommendation systems.
Autoencoders, a subset of neural networks, present another avenue for feature extraction. These algorithms adeptly compress input data into a lower-dimensional form and then reconstruct it. The resulting compressed form often encapsulates essential features that can significantly enhance your model's efficacy.
| Technique | Best For | Strengths |
|---|---|---|
| Principal Component Analysis | High-dimensional data | Reduces dimensionality, preserves variance |
| Latent Dirichlet Allocation | Text data | Uncovers topics, improves text understanding |
| Autoencoders | Complex data patterns | Learns compact representations, handles non-linear relationships |
By leveraging these feature extraction methods, you can expose hidden patterns in your data, potentially resulting in more precise predictions and deeper insights. The selection of technique should align with your specific dataset and the problem you aim to solve.
Dimensionality Reduction for Enhanced Precision
Dimensionality reduction is essential for managing high-dimensional data and boosting model precision. It's vital for overcoming the hurdles of feature compression and manifold learning. Let's delve into some top methods used in this domain.
Principal Component Analysis (PCA)
PCA is a leading technique for reducing dimensions. It simplifies data into a lower-dimensional space, keeping as much variance as possible. This approach is ideal for datasets with numerous features.
t-SNE and UMAP
t-SNE and UMAP are non-linear methods that excel at maintaining local structure in high-dimensional data. They are invaluable for visualizing intricate datasets and discovering hidden patterns.
Autoencoders for Feature Compression
Autoencoders, a form of neural network, learn efficient data encodings. They compress features effectively while keeping crucial information. This makes them excellent tools for dimensionality reduction in complex datasets.
Adopting these techniques can notably uplift your model's performance. They facilitate in visualizing complex datasets, reducing computational complexity, and alleviating the curse of dimensionality. By employing these methods, you can refine the precision of your machine learning models when dealing with high-dimensional data.
| Technique | Best Use Case | Complexity |
|---|---|---|
| PCA | Linear data with high variance | Low |
| t-SNE | Non-linear data visualization | Medium |
| UMAP | Large-scale data reduction | Medium |
| Autoencoders | Complex, non-linear relationships | High |
Choosing the optimal dimensionality reduction technique hinges on your dataset and objectives. Experiment with various methods to discover the best fit for your project.

Feature Engineering for Precision: Advanced Techniques
Feature engineering is key to enhancing machine learning model performance. Advanced techniques transform raw data into insights, significantly boosting model precision. Let's delve into powerful methods that can uplift your machine learning endeavors.
Interaction Features revolutionize by capturing complex relationships between variables. By merging multiple features, you forge new, more insightful attributes. These uncover hidden patterns in your data, especially in non-linear relationships that simple models overlook.
Polynomial Features introduce non-linearity by combining existing features in diverse ways. This technique enables your model to discern complex patterns and relationships within the data. For instance, squaring or cubing a feature can expose trends that linear models often miss.
Domain Knowledge Integration leverages expert insights to craft highly relevant features. By incorporating industry-specific knowledge, you develop features specific to your problem domain. This strategy frequently results in more precise and interpretable models.
"Good feature engineering can augment the value of existing data and improve the performance of machine learning models."
Here's a comparison of these advanced techniques:
| Technique | Advantages | Challenges |
|---|---|---|
| Interaction Features | Captures complex relationships | Can lead to feature explosion |
| Polynomial Features | Introduces non-linearity | Increases model complexity |
| Domain Knowledge Integration | Creates highly relevant features | Requires expert input |
By excelling in these advanced feature engineering techniques, you'll be adept at extracting valuable insights from your data. This will enable you to craft more precise machine learning models.
Handling Missing Data and Outliers
Data cleaning is essential for building robust models. It ensures your machine learning models are precise and reliable. Let's delve into effective strategies for managing these data challenges.
Imputation Strategies
Missing values can significantly reduce your sample size and introduce bias. Identifying these gaps is the initial step in data cleaning. Utilize functions like .isnull() or .isna() to pinpoint missing data in your dataset. Once located, you have several imputation strategies at your disposal:
- Mean/Median/Mode Imputation: Replace missing values with the average, middle value, or most frequent value.
- Forward/Backward Fill: Use the previous or next non-missing value to fill gaps.
- KNN Imputation: Estimate missing values based on similar data points.
The imputation method you select depends on your data type and the nature of missingness. For time series data, forward or backward fill is often suitable to maintain temporal order.
Outlier Detection and Treatment
Outliers can distort your analysis and impact model performance. Anomaly detection techniques are vital for identifying these unusual data points. Common methods include:
- Statistical approaches: Z-score or Interquartile Range (IQR)
- Machine learning methods: Isolation Forest or Local Outlier Factor
Once outliers are detected, you can address them by removing them, capping extreme values, or employing robust statistical methods. These methods are less sensitive to outliers.
Effectively managing missing data and outliers sets the stage for more accurate and reliable machine learning models. These data cleaning steps are vital for developing robust models that can adeptly handle real-world data challenges.
| Missing Data Type | Description | Handling Strategy |
|---|---|---|
| MCAR (Missing Completely at Random) | Uniform probability of missing data | Listwise deletion or simple imputation |
| MAR (Missing at Random) | Missingness depends on observed data | Multiple imputation or maximum likelihood |
| MNAR (Missing Not at Random) | Missingness related to unobserved data | Sensitivity analysis or modeling the missing data mechanism |
Feature Scaling and Normalization
Feature scaling is essential in machine learning. It ensures all features have an equal impact on your model's performance. This process is crucial for algorithms that are sensitive to the varying scales of dataset features.
Min-Max Scaling, also known as normalization, rescales features between 0 and 1. It's ideal for features with known bounds and no significant outliers. The formula used is:
X_scaled = (X - X_min) / (X_max - X_min)
Standardization, or Z-score Scaling, transforms features to have zero mean and unit variance. It's suitable for features with unknown or non-normal distributions. Standardization uses this formula:
X_scaled = (X - X_mean) / X_std
Robust Scaling is another technique that's particularly useful when dealing with outliers. It uses the median and interquartile range (IQR) instead of mean and standard deviation:
X_scaled = (X - X_median) / IQR
The choice between these scaling methods depends on your data characteristics and the algorithm you're using. For instance, gradient descent-based algorithms like linear regression require scaled data for smooth convergence. Distance-based algorithms such as KNN are significantly affected by feature ranges and benefit from scaling.
| Scaling Method | Best For | Sensitive to Outliers |
|---|---|---|
| Min-Max Scaling | Bounded range features | Yes |
| Standardization | Unknown distributions | Yes |
| Robust Scaling | Data with outliers | No |
Remember, it's crucial to fit your scaler on training data and apply the same transformation to your test data. This practice prevents data leakage and ensures consistent scaling across your datasets.
Domain-Specific Feature Engineering Strategies
Feature engineering is a pivotal step in machine learning, with approaches varying by data type. We'll delve into strategies tailored for specific domains to enhance model precision.
Text Data Preprocessing
Natural Language Processing techniques are essential for text data. Begin with tokenization, splitting text into words or phrases. Then, eliminate stop words, which are common but lack significant meaning. Utilize TF-IDF or word embeddings to numerically represent your text, capturing its core for easier model processing.
Time Series Feature Engineering
Time series data requires a focus on temporal features. Create lag features, using past values to forecast future ones. Incorporate rolling statistics, such as moving averages or standard deviations, to capture temporal trends. Seasonality, recurring patterns, should also be considered to enrich your model's understanding of the data's time-based structure.
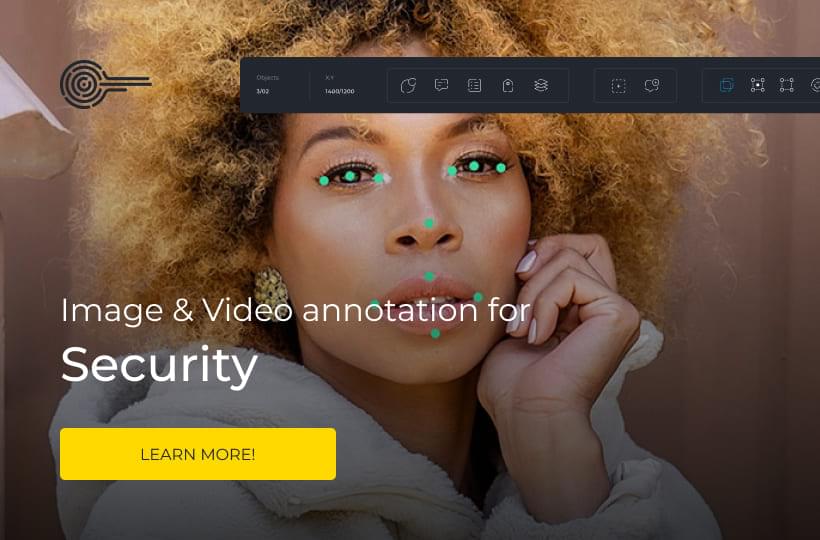
Image Feature Extraction
In Computer Vision, extracting relevant features from images is crucial. Techniques like edge detection identify object boundaries, while color histograms capture color distributions. For more intricate tasks, convolutional neural networks can automatically learn and extract features from images. These methods transform pixel data into informative features, significantly boosting model performance.
FAQ
What is feature engineering?
Feature engineering is the process of selecting, manipulating, and transforming raw data into features for supervised learning. It involves feature creation, transformations, feature extraction, exploratory data analysis, and benchmarking to improve model accuracy and simplify data transformations.
Why is feature engineering important?
Feature engineering is crucial for extracting meaningful information from data and enhancing the performance of machine learning models. It addresses challenges like missing data, high-dimensional data, and categorical variables, ultimately allowing for more informed decision-making.
What are some common data preprocessing techniques in feature engineering?
Common data preprocessing techniques include handling missing data, converting variables to numeric format, scaling features, creating new features, and addressing sequential data patterns. These steps are essential for preparing data for effective feature engineering.
What are some feature selection techniques?
Feature selection techniques aim to identify the most relevant features for a machine learning model. Filter methods assess feature characteristics using statistical measures, wrapper methods evaluate feature subsets iteratively, and embedded methods combine feature selection with model training, such as LASSO regression.
What is feature extraction?
Feature extraction is the process of deriving new features from existing ones to uncover hidden patterns in the data. Techniques like Principal Component Analysis (PCA), Latent Dirichlet Allocation (LDA), and autoencoders are used to create more informative features that capture underlying relationships in the data.
How do dimensionality reduction techniques help in feature engineering?
Dimensionality reduction techniques like PCA, t-SNE, UMAP, and autoencoders help in handling high-dimensional data, improving model precision, and reducing computational complexity. They transform data to lower-dimensional spaces while preserving important information.
What are some advanced feature engineering techniques?
Advanced techniques include creating interaction features, polynomial features, integrating domain knowledge, using embedding layers for text data, automated feature generation, and innovative scaling methods. These techniques aim to extract deeper insights and provide more predictive power to machine learning models.
How do you handle missing data and outliers in feature engineering?
Imputation strategies like numerical and categorical imputation are used for missing data, while techniques like removal, replacement, capping, and discretization are employed for outliers. Outlier detection methods such as statistical approaches or machine learning-based methods can be used to identify anomalies.
Why is feature scaling and normalization important?
Feature scaling and normalization techniques like Min-Max scaling, standardization, and robust scaling ensure that all features contribute equally to the model and prevent features with larger magnitudes from dominating the learning process, ultimately improving model performance and convergence.
What are some domain-specific feature engineering strategies?
Domain-specific strategies include techniques tailored to particular types of data, such as text preprocessing (tokenization, stop word removal, TF-IDF, word embeddings), time series feature engineering (lag features, rolling statistics, seasonality), and image feature extraction (edge detection, color histograms, convolutional neural networks).