Few-Shot and Zero-Shot Labeling
Zero training reduces the time and resources required to annotate data. Continuous learning and zero training transform AI model training and reduce the need for data annotation. With few or no labeled data, it is possible to train machine learning models with this method.
Key Takeaways
- Continuous learning and zero learning make it easier to create annotations.
- Training an AI model is efficient with a minimal amount of labeled data.
- These methods save money on data annotation.
- Recent research shows progress in large language models that follow instructions.

Understanding Fine-Tuning with Minimal Labels
Fine-tuning with minimal labels uses pre-trained models to fine-tune specific tasks with small, selected datasets.
What is fine-tuning?
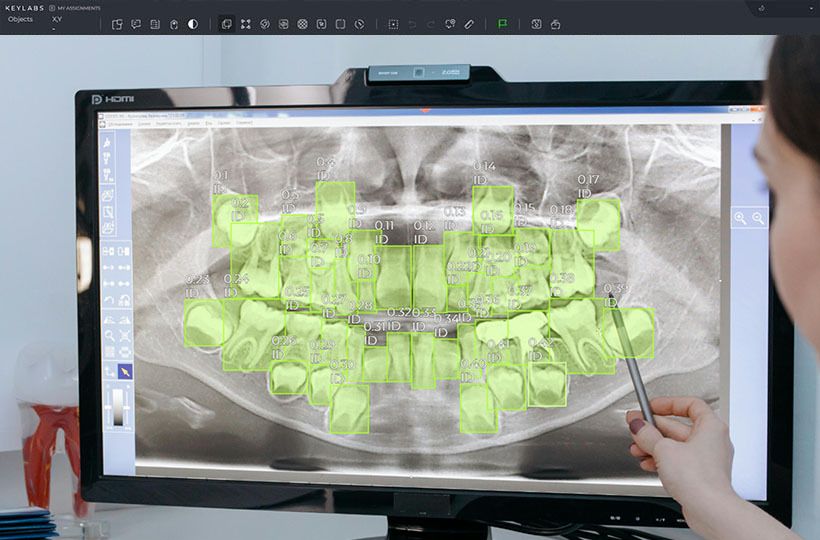
Fine-tuning retrains a pre-trained model with a small dataset. Minimal labels are a small set of annotated data to retrain a model. This technique is used in automatic annotation, computer vision, medicine, and finance.
The Importance of Minimal Labels
Minimal labels reduce data and computational requirements. Data with multiple labels is stored in JSON format for proper evaluation. JSON (JavaScript Object Notation) is a text-based data interchange format that stores and transfers information between servers, web applications, and other systems. Fine-tuning uses semi-supervised learning to adapt models on smaller datasets.
Key Terminology
- Adaptive Machine Learning. Models adjust their parameters based on new data.
- Semi-supervised learning uses both labeled and unlabeled data.
- Model adaptation is the refinement of artificial intelligence or machine learning to work on specific data or under specific conditions.
- Parameter-Efficient Fine Tuning (PEFT) is a technique that updates selected model parameters to reduce the need for computation.
Understanding these terms and their meanings is important for fine-tuning with minimal labels.
Basic Concepts of Few-Shot Learning
Single-pass training trains models to perform tasks with a small number of examples. It uses transfer learning to improve existing models. Thus, AI can be trained with a limited amount of data. The strength of this method is its ability to adapt to new data using the knowledge already acquired.
Areas of use
Multiple-pass training is standard in various industries:
- Healthcare. Used in medical diagnostics, where data is limited and expert annotations are needed.
- Finance. To detect fraud or predict stock price movements.
- Autonomous driving. It helps autonomous vehicles recognize rare obstacles or scenarios.
Zero-Shot Learning Definition and Principles
Zero-shot learning allows models to classify new instances without labeled examples during training. This method is helpful in cases where annotating new data is impossible. It aims to recognize and classify new classes of objects without labeled data. The model can learn about hidden categories by passing information from visible classes. It simplifies similarity searching without the need for class labels.
Few-Shot Learning vs. Zero-Shot Learning
Small training requires a few labeled examples to group new classes. Zero-shot learning groups' new courses without any labeled examples. Zero-shot object detectors pass information to expand the number of objects that can be detected.
Advantages of Zero-Shot Labeling
Techniques to Minimize Annotation Effort
A mix of different methods can reduce the need for manual data labeling. We will look at a few strategies.
Labeled Data Distribution Methods
Labeled data distribution methods are strategies for efficiently attaching labels or annotations to datasets. Labels are needed to train models; they tell them how to classify or recognize data correctly. These methods reduce the time and resources required to train AI models.
Transfer Learning
Transfer learning is a method that uses knowledge gained from solving one problem to solve a similar problem. This method has two stages of learning:
- Large Dataset Training. The model is trained on a large amount of data for a single problem.
- Knowledge Transfer. The model is adapted to a new problem with a small amount of data.
Such techniques allow you to apply existing knowledge to new problems, optimizing the model's training process.
Impact of fine-tuning on Model Performance
Fine-tuning large language models adapts them to specific tasks. The main advantage of this method is the quality of the data. It is achieved by fine-tuning an already-trained model to solve specific tasks. During this process, the model adapts to different data, which increases its accuracy.
Measuring Model Performance
Evaluating model fine-tuning metrics:
- Comparing performance before and after fine-tuning.
- Testing models on different datasets and outside the domain.
- Examining the positive and negative effects of transfer on tasks.
Fine-tuned large language models have significantly improved natural language recognition. Data quality should be prioritized over quantity in training and maintaining AI models.
Problems with labeling
The problem of data scarcity is a hindrance to machine learning, especially in few and zero-chance scenarios.
Few-shot learning is a training method in which a model is trained to solve problems with a small number of examples. Zero-shot learning is an advanced method in which a model solves new problems without previous examples. It occurs when there is not enough quality and variety of data to train the models. Here are some methods to prevent this problem: collect more data, perform data quality control, augment data, and use synthetic data.
Quality control with Minimal Labeling
Any errors in quality control can affect the model's performance and generalization ability. To solve this problem, it is important to adopt data validation and annotation standards. Methods such as operational learning, pre-training on large data sets, and fine-tuning on smaller data sets are used.
Computational limitations
Training models with limited data requires complex, computationally intensive algorithms. Transfer learning addresses this problem. This involves pre-training models on large datasets and fine-tuning them on smaller datasets.
Best Practices for Implementation
A strategic approach to fine-tuning methods with limited labels. It includes the type and availability of the data. This aspect can improve the performance of the model in different applications.
Choosing a fine-tuning approach involves analyzing both structured and unstructured data. Structured data, such as customer information or product descriptions, requires precise processing. Unstructured data, such as images, videos, or text, does not require precise processing. Supervised fine-tuning methods are helpful for efficiently fine-tuning large language models (LLMs).
Pre-trained models optimize our resources. Models trained on a variety of datasets can be tuned for specific tasks. This practice reduces development time.
Develop a robust annotation strategy.
A strategic approach to data annotation optimizes the fine-tuning process. A combination of manual and automated methods ensures high-quality annotated datasets. Annotation strategies should be continuously evaluated to meet the task's changing needs.
- Supervised fine-tuning updates and trained language models using labeled data.
- Contextual learning improves the effectiveness of model prompts using examples.
- Instruction fine-tuning adjusts tasks to align with desired outcomes.
Future directions in labeling techniques
The future of AI labeling focuses on creating high-quality labeled datasets. Principal component analysis (PCA) and autoencoders help visualize data. These AI labeling tools simplify data manipulation.
Semi-supervised and transfer learning are being introduced. These methods leverage existing data and knowledge. Advanced labeling methods recognize objects in self-driving cars and detect fraud in financial services. High-quality labeling is essential for combating disinformation and ensuring the integrity of media content.
It is important to evaluate the performance of these algorithms. This improvement in future data annotation methods will ensure their effectiveness in various applications.
FAQ
What is Few-Shot Learning?
Few-shot learning is a cutting-edge technique in machine learning. It enables models to learn and generalize from a small amount of labeled data, which is critical when gathering large amounts of labeled data is impractical or too expensive.
How does Zero-Shot Learning work?
Zero-shot learning allows models to infer about unseen classes using semantic information. It relies on textual descriptions or other auxiliary information to predict classes the model hasn't seen before.
What is Fine-Tuning?
Fine-tuning involves adjusting a pre-trained model with a new, minimal dataset for specific tasks.
Why are Minimal Labels important in AI model training?
Minimal labels reduce the time and resources needed for data annotation. Strategic sampling of small datasets can lead to impressive results, making it possible to develop high-performing models without needing extensive labeled data.
What are some real-world applications of Few-Shot Learning?
Few-shot learning is applied in various fields, such as healthcare for medical image analysis, finance for fraud detection, and autonomous driving for object recognition in low-data environments. These sectors benefit from few-shot learning due to data scarcity and the need for precise model performance.
How does Zero-Shot Learning differ from Few-Shot Learning?
Few-shot learning trains models on a small amount of labeled data. On the other hand, zero-shot learning doesn't require labeled instances of unseen classes. Zero-shot models use auxiliary information to predict new categories not seen during training.
What techniques help in minimizing annotation effort?
Techniques like label propagation and transfer learning are key. Label propagation spreads labels from a small set to unlabeled data. Transfer learning uses pre-trained models to reduce the need for extensive new data. Combining different models also helps reduce labeling efforts.
How does fine-tuning impact model performance?
Fine-tuning can greatly enhance model performance by balancing data quality and quantity. Optimizing the fine-tuning process involves measuring model efficacy through various metrics. Adjusting strategies ensures superior outcomes even with minimal labels.
What challenges exist in few-shot and zero-shot labeling?
Challenges include data scarcity, quality control in sparse labeled data environments, and computational constraints. These limitations can affect the scalability and training of models.
What are the best practices for implementing fine-tuning techniques with minimal labels?
Best practices include selecting the right fine-tuning approach based on data type and availability. Utilizing pre-trained models can bypass the initial training phases. Developing robust annotation strategies maximizes data efficiency and model performance.
What future trends might shape the landscape of labeling techniques in machine learning?
Innovations like advanced semi-supervised and label-efficient training methods will likely transform the landscape. These technologies could address current limitations and impact various industries by improving AI's adaptability and efficiency in low-resource settings.
What are some examples of successful implementations of fine-tuning with minimal labels?
Many industries have successfully implemented fine-tuning with minimal labels. Healthcare, finance, and autonomous driving case studies highlight effective techniques and lessons learned from real-world applications.