Human-in-the-Loop Annotation: Building Feedback Loops for Continuous Improvement
In the modern information environment, data is a critically important resource for the development of AI technologies. The effectiveness of automated systems largely depends on the ability of models to undergo iterative refinement and continuous improvement based on feedback from annotators. The processes of model retraining and the formation of quality improvement loops ensure increased accuracy and reliability of systems, facilitating their adaptation to new tasks and complex conditions. This approach lays the groundwork for the continuous development of technologies and the effective utilization of data in practical applications.
Key Takeaways
- Structured cycles improve model alignment.
- Traceability and oversight are essential for Responsible AI.
- Well-run systems boost performance without slowing development.
- Data quality and expertise drive measurable improvements over time.

Why Human-in-the-Loop Matters Now
Modern AI systems are becoming increasingly complex and are being integrated into critical areas, including healthcare, finance, and autonomous vehicles. In these contexts, the reliability of results and risk management are of paramount importance. Automated models, even with large amounts of data, are not always able to accurately interpret complex or atypical scenarios, which increases the potential for errors.
Involving the human factor through Human-in-the-Loop (HITL) allows for the creation of quality improvement loops, where annotator feedback directly influences the iterative refinement process of the model. Each correction and refinement of data from humans increases the accuracy of predictions and minimizes the risks of critical errors. Additionally, the integration of HITL into the model retraining cycle enables systems to adapt more quickly to new or unpredictable conditions, resulting in more stable and reliable operation in real-world applications.
Defining the Practice: Human-in-the-Loop Annotation and Continuous Feedback
Human Expertise in the Annotation Process
Active Learning, Edge Cases, and Higher-Impact Labeling
Not all data affects model quality equally, and labeling large amounts of standard examples can be an inefficient process. This is where active learning comes in handy — a method in which the model independently identifies the most “uncertain” or informative examples for manual verification. This approach allows annotators to focus their efforts on edge cases — complex or rare cases that have the greatest potential impact on model accuracy.
Focusing on edge cases provides higher-impact labeling, because even a small amount of correctly labeled complex data can significantly improve model performance. This process creates effective quality improvement loops, where each data refinement, informed by annotator feedback, is used for iterative refinement and subsequent model retraining. Thanks to this approach, models become more reliable, adaptive, and capable of correctly handling rare or complex scenarios, thereby reducing the risk of errors in critical tasks.
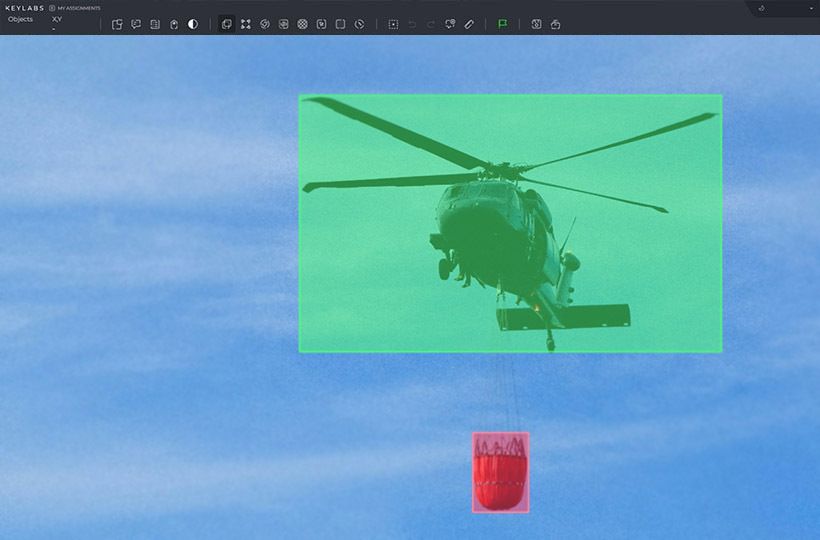
Evaluation Workflows in Training vs. Production
Summary
Focusing on complex or rare examples (edge cases) through active learning and high-impact labeling allows for more efficient use of human resources and significantly improves system performance. These processes generate annotator feedback, which is key to high-quality model retraining and supporting quality improvement loops.
The separation of workflows for training and production environments emphasizes the difference between evaluating a model under controlled conditions and its behavior in the real world. Combined with HITL, this ensures not only increased accuracy but also stability, reliability, and adaptability of models in dynamic and high-risk scenarios.
FAQ
What is the role of Human-in-the-Loop (HITL) in AI systems?
HITL integrates human expertise into AI workflows to improve accuracy and reliability. It enables annotator feedback that drives iterative refinement and supports quality improvement loops.
Why is human expertise critical in the annotation process?
Human experts handle ambiguous or complex cases that models cannot interpret. Their insights enhance annotator feedback and guide model retraining for better performance.
How does iterative refinement improve model performance?
Through repeated cycles of human review and correction, models become increasingly accurate over time. Iterative refinement ensures that annotator feedback is effectively incorporated into each model retraining cycle.
What is the purpose of active learning in HITL systems?
Active learning prioritizes the most uncertain or informative data points for human annotation. This focuses resources on edge cases and enables higher-impact labeling, improving efficiency and model quality.
Why are edge cases important in annotation?
Edge cases represent rare or complex scenarios that can disproportionately affect model accuracy. Properly labeled, they drive meaningful iterative refinement and strengthen quality improvement loops.
How does annotator feedback influence model retraining?
Feedback from human annotators provides corrected data for model retraining, helping the system adapt to new or unusual cases. This ensures models evolve continuously through quality improvement loops.
What is higher-impact labeling, and why is it used?
Higher-impact labeling targets data points that significantly influence model performance, often in edge cases. It maximizes the effect of human annotation in iterative refinement and model retraining.
How do evaluation workflows differ between training and production?
Training workflows utilize pre-labeled datasets to assess generalization, whereas production workflows focus on monitoring real-world performance. Both rely on annotator feedback and quality improvement loops, but production emphasizes stability and reliability.
What are quality improvement loops in HITL?
They are cyclical processes where human corrections feed back into the system to enhance model performance. Iterative refinement, annotator feedback, and model retraining all work together to maintain these loops.
Why is HITL becoming increasingly important today?
Modern AI is deployed in high-risk, dynamic environments where mistakes are costly. HITL ensures continuous adaptation and reliability through annotator feedback, iterative refinement, model retraining, and quality improvement loops.