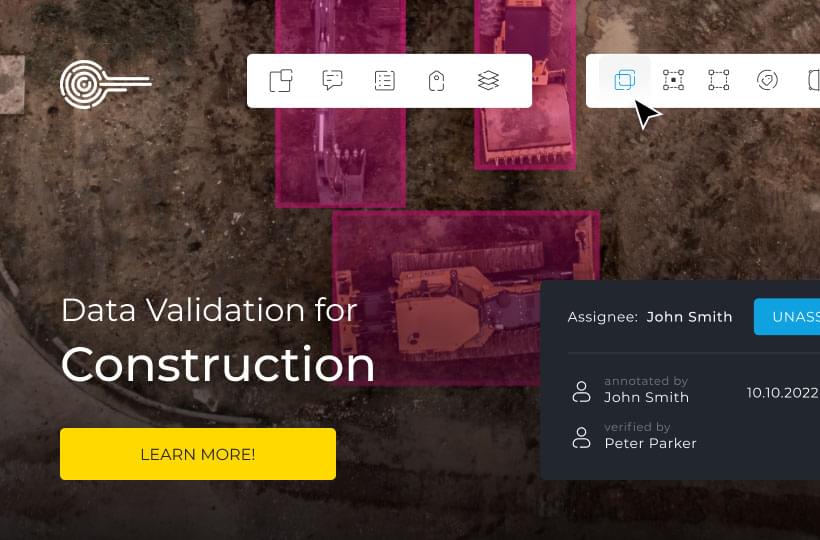
Integrating Automatic Annotation into Your Workflow
Thanks to advancements in natural language processing and machine learning, adding auto-labeling tools to your workflow is now easier and more efficient. By using pre-trained models and active learning, you can speed up text and computer vision projects. This leads to faster iterations and more precise results.
Automatic annotation is a breakthrough for businesses and researchers handling large amounts of unstructured data. It automates the task of identifying and labeling information in text, images, or videos. This saves countless hours of manual effort, allowing you to focus on more complex tasks. Whether you're into sentiment analysis, named entity recognition, or object detection, ML-assisted annotation can make your goals more achievable.
One major advantage of automatic annotation is its ability to handle vast datasets with consistency and precision. Manual annotation is time-consuming and prone to errors. Auto-labeling uses machine learning models trained on diverse datasets. This ensures your annotations are consistent, reducing the risk of errors that could affect your model's performance.
Key Takeaways
- Automatic annotation can reduce data labeling time by up to 90%, enabling faster iterations and more accurate results.
- Auto-labeling ensures consistency and accuracy across large datasets, minimizing the risk of human error and biases.
- Integrating automatic annotation allows for effortless scaling of data annotation efforts, processing large volumes of data efficiently.
- Choosing the right data annotation platform and tools is crucial for unlocking the full potential of automatic annotation.
- Automatic annotation is particularly valuable in industries such as healthcare, finance, and e-commerce, where analyzing massive datasets can provide a competitive edge.

Understanding Automatic Annotation
Automatic annotation, also known as automated labeling or annotation automation, uses AI and machine learning to make labeling and classifying data for machine learning projects easier. This method is crucial in computer vision tasks like object detection, image classification, and semantic segmentation. It helps process large amounts of visual data accurately and efficiently.
Using automated annotation companies can cut the time and resources needed for manual labeling. This often takes a quarter of the time allocated for computer vision projects. Automation lets human teams focus on quality control and edge cases, enhancing accuracy and efficiency.
What is Automatic Annotation?
Automatic annotation is the process of using machine learning algorithms to label or classify data without much human input. It's useful for various data types, including images, videos, audio, and text. This makes it essential for many machine learning tasks, such as natural language processing, conversational AI, voice recognition, and transcription.
The automated data annotation process includes several steps:
- Data preparation and preprocessing
- Feature extraction and selection
- Model training and validation
- Automatic labeling of new data
- Quality control and human review
Benefits of Automatic Annotation
Automatic annotation brings several advantages to machine learning workflows:
- Cost-effectiveness: It's more affordable than manual annotation, reducing the need for a lot of human labor.
- Faster turnaround time: Automating labeling cuts down the time needed to prepare data for machine learning models, speeding up projects.
- Consistency and objectivity: It ensures consistent and unbiased results, reducing human error and bias in labeling.
- Scalability: Automated solutions can efficiently handle large datasets, making it easier to scale machine learning projects.
| Traditional Data Labeling | Automated Data Annotation |
|---|---|
| Manual and time-consuming | Efficient and scalable |
| Prone to human error and bias | Consistent and objective |
| Costly due to extensive human labor | Cost-effective by reducing manual effort |
| Limited scalability for large datasets | Highly scalable for handling vast amounts of data |
Preparing Your Dataset for Automatic Annotation
Before starting with automatic annotation, it's vital to prepare your dataset thoroughly. This preparation includes organizing and cleaning your data to make it suitable for the annotation tool. Doing this ensures accurate and reliable annotations, which is crucial for better model performance.
Organizing and Cleaning Your Data
First, organize your dataset in a logical and consistent manner. This means:
- Removing duplicates and irrelevant data points
- Ensuring consistent formatting and naming conventions
- Splitting your data into appropriate subsets (e.g., training, validation, and test sets)
- Labeling your data according to the annotation tasks and rules you've defined
Cleaning your data is also crucial for annotation accuracy and reliability. This involves:
- Handling missing or incomplete data points
- Correcting errors and inconsistencies
- Normalizing and standardizing data formats
- Removing noise and outliers that could skew your annotations
A well-organized and clean dataset is the foundation for successful automatic annotation. It ensures that your annotation tool can process your data efficiently and accurately, yielding high-quality annotations for your machine learning models.
Choosing the Right File Formats
Selecting the right file formats for your dataset is key. The choice depends on the type of data and the annotation tool's requirements. Common file formats include:
| Data Type | Common File Formats |
|---|---|
| Images | JPEG, PNG, TIFF |
| Videos | MP4, AVI, MOV |
| Text | TXT, CSV, JSON |
| Medical Imaging | DICOM, NIfTI |
When picking file formats, consider:
- Compatibility with your annotation tool and machine learning frameworks
- File size and storage requirements
- Compression and quality settings
- Metadata and additional information to be included
Choosing the right file formats ensures smooth integration with your automatic annotation tool and enhances your machine learning models' performance.
Selecting the Right Automatic Annotation Tool
Choosing the right annotation tool is crucial for your project's success. Key factors include efficiency, functionality, formatting, application, and price. It's vital to align your tool with your project goals and budget.
Computer vision tasks like image classification and object detection require specific annotations. These can be in formats such as COCO JSONs or Pascal VOC XMLs. Ensure your tool supports these formats and annotation types.
Consider the tool's compatibility with your workflow. Some tools offer web-based and window apps for flexibility. Assess your team's preferences and project needs to choose the best option.
For small to medium-sized teams, cost is a significant factor. While some tools have a cost, others are free or open-source. Keylabs aims to offer the best of both worlds in terms of scaling, integrations, and affordability.
When comparing tools, consider these features:
- Support for hotkeys and keyboard shortcuts for improved efficiency
- Compatibility with various annotation shapes and formats
- Collaborative annotation capabilities for team-based projects
- Integration with machine learning pipelines and workflows
- Scalability and ability to handle large datasets
Explore AI-based annotation tools that use active learning and semi-automated techniques. These tools can speed up annotation by suggesting labels intelligently
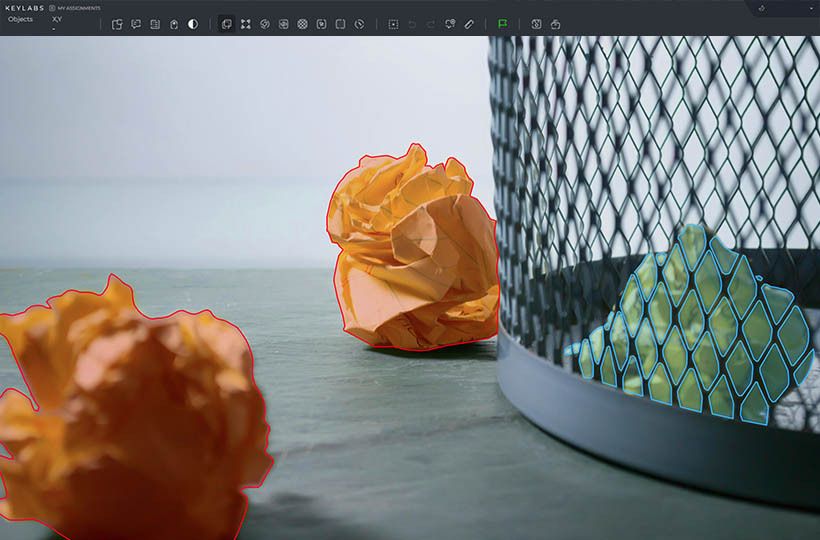
Setting Up Your Automatic Annotation Workflow
To fully utilize automatic annotation, establishing a detailed annotation workflow is crucial. This entails crafting a new workflow, outlining annotation tasks and rules, and assigning annotators and reviewers for a streamlined process.
Creating a New Workflow
Start by creating a new workflow in your annotation tool. Keylabs simplifies this by automating the labeling process. The initial workflow includes selecting a dataset, assigning annotations to collaborators, and confirming completion. Users can tailor workflows by assigning specific tasks to annotators.
Defining Annotation Tasks and Rules
Clearly define the annotation tasks and rules for your project. This entails identifying the objects to annotate, the labels required, and any unique instructions for annotators. For instance, when annotating PBMCs, you might label cell types such as naive B cells, monocytes, cytotoxic T cells, and dendritic cells.
There are six blocks available for constructing an Automation workflow:
- Dataset
- To Annotate
- To Review
- Completed
- Consensus
- Trigger
Assigning Annotators and Reviewers
Assign annotators and reviewers based on their expertise and availability. Annotation Automation reduces wasted annotation time by assigning specific tasks to annotators, preventing duplication. Annotators only see their assigned tasks, enhancing efficiency when tackling large datasets.
Include reviewers in the workflow to guarantee annotation quality and streamline approval. Reviewers can approve or reject assets during the review stage.
Bestablishing a structured automatic annotation workflow, you can ensure efficient and accurate completion of annotation tasks. This sets the stage for successful model training and deployment.
Training Your Automatic Annotation Model
Training your automatic annotation model is essential for an efficient and precise workflow. Start with high-quality initial training data and refine the model iteratively to boost its performance.
Providing Initial Training Data
To kick off, feed your model a diverse set of annotated data. This initial data is crucial for the model to learn and apply to new situations. Keep these points in mind when preparing your data:
- Ensure the data reflects the object classes, scenarios, and edge cases your model will face in real-world applications.
- Keep annotation styles and labeling consistent across the dataset.
- Use experienced annotators who know the domain and can label accurately and thoroughly.
High-quality initial training data is the foundation for a strong, dependable automatic annotation model.
Iterative Model Training and Refinement
After setting up your initial training data, it's time to train and test your model. This process requires several rounds of training, testing, and refinement to enhance accuracy and efficiency. Here are some best practices:
- Choose a suitable model architecture and hyperparameters tailored to your annotation tasks and dataset.
- Check the model's performance on a validation set to see how well it generalizes and spot areas for improvement.
- Review the model's outputs and get feedback from annotators and reviewers to pinpoint errors, edge cases, and confusion points.
- Improve the model by tweaking its parameters, adjusting the training data, or using techniques like data augmentation or transfer learning.
- Keep training and testing the model, tracking its progress and making data-driven tweaks to improve its performance.
Continuous refinement is crucial for a top-notch automatic annotation model. By learning from the model's outputs and incorporating feedback, you can steadily improve its accuracy and reliability.
| Model Training Stage | Key Considerations |
|---|---|
| Initial Training Data | Diversity, consistency, and quality of annotations |
| Model Architecture Selection | Choosing suitable architecture based on annotation tasks and dataset |
| Hyperparameter Tuning | Optimizing model parameters for best performance |
| Evaluation and Feedback | Assessing model performance and gathering insights for refinement |
| Iterative Refinement | Fine-tuning, data augmentation, transfer learning, and continuous improvement |
By adhering to these guidelines and adopting an iterative approach to model training and refinement, you can craft a robust automatic annotation system.
Integrating Automatic Annotation into Your Existing Workflow
Integrating automatic annotation into your workflow is crucial for boosting efficiency and ensuring a smooth transition. Many annotation tools provide API integration, allowing you to link the annotation process with other systems in your pipeline. This facilitates workflow integration. By using these APIs, you can streamline data transfer and automate various stages of the annotation process.
Setting up automation triggers and actions is vital for integrating automatic annotation into your workflow. For instance, you can configure triggers to automatically send data to the annotation tool when specific conditions are met, such as the arrival of new images or the completion of a previous processing step. Similarly, you can define actions to be executed once the annotation process is complete, such as triggering downstream processes or notifying relevant stakeholders.
API Integration
API integration is a powerful method to connect your automatic annotation tool with other parts of your workflow. By utilizing APIs, you can exchange data between systems, automate tasks, and enable real-time communication.
To effectively use API integration, it's crucial to understand the documentation and endpoints provided. Many tools offer comprehensive APIs that allow you to programmatically create projects, upload data, assign tasks, retrieve annotations, and more. By incorporating these API calls into your workflow, you can automate repetitive tasks and ensure a seamless flow of data between systems.
Automation Triggers and Actions
Automation triggers and actions are key to streamlining your annotation workflow. Triggers initiate certain actions based on predefined conditions or events. For example, you can set up a trigger to automatically send newly collected images to your annotation tool for processing. This eliminates the need for manual intervention and ensures that data is consistently fed into the annotation pipeline.
Actions define what happens after the annotation process is complete. You can configure actions to automatically export annotated data, update databases, or trigger subsequent steps in your workflow.
Annotation Automation
By combining API integration with automation triggers and actions, you can create a highly efficient and streamlined annotation workflow that seamlessly integrates with your existing processes. This enables you to focus on higher-level tasks while the annotation process runs smoothly in the background, ultimately saving time and resources.
Quality Control and Review Process
Ensuring the quality of annotations is crucial for your machine learning project's success. A strong quality control and review process is vital. It helps spot errors, inconsistencies, and biases in annotations. This process includes manual review by experts and automated checks and validation rules.
To keep annotation quality high, use metrics like Cohen's kappa, Fleiss' kappa, Krippendorf's alpha, and F1 score. These metrics evaluate the accuracy and consistency of annotations. Inter-annotator agreement (IAA) measures how often annotators agree. Cohen's kappa looks at agreement between two annotators, considering both actual and chance agreement. Fleiss' kappa assesses agreement among multiple annotators beyond chance. Krippendorf's alpha is for incomplete data and partial agreement among several annotators.
annotation quality
Checking data annotation quality means looking at accuracy, consistency, and completeness. Metrics like precision, recall, and F1 score help with this. The F1 score, which combines precision and recall, measures data annotation accuracy. In healthcare, for instance, having only 20% of images of malignant tumors affects model accuracy.
To keep annotation quality high, follow these best practices:
- Ensure good communication between data scientists and annotators, especially in distributed teams.
- Have a gold standard dataset for consistency and integrity, regardless of annotator skill.
- Use consensus algorithms for a single data point agreement among team members to improve accuracy.
- Apply scientific tests like Chronbach Alpha, Fleiss' Kappa, Pairwise F1, and Krippendorff's Alpha to check annotator accuracy and consistency.
- Subsample random data to find areas prone to labeling errors.
- Classify annotators by skill and divide them into sub-teams to use specific expertise for better dataset quality.
Quality control in annotation tools is vital for maintaining high annotation standards.
| Metric | Purpose |
|---|---|
| Cohen's Kappa | Assesses agreement between two annotators considering observed and chance agreement |
| Fleiss' Kappa | Assesses agreement among a fixed number of annotators beyond chance expected by random allocation |
| Krippendorff's Alpha | Suitable for incomplete data and partial agreement among multiple annotators |
| F1 Score | Combines precision and recall to evaluate data annotation accuracy |
By using a strong quality control and review process, advanced annotation tools, and quality metrics, you can ensure accurate and consistent annotations. This leads to more reliable and effective machine learning models.
Handling Edge Cases and Exceptions
Automatic annotation brings numerous benefits but acknowledges the presence of difficult or ambiguous cases. These edge cases and exceptions demand special attention to maintain data accuracy and consistency. Addressing these challenges proactively ensures your automatic annotation workflow remains effective and reliable.
Defining Exception Handling Rules
Establishing clear exception handling rules is crucial for managing edge cases and exceptions in automatic annotation. These rules should outline criteria for identifying problematic cases and steps for handling them. Consider these strategies:
- Set confidence thresholds: Determine the minimum confidence level required for an automatic annotation to be accepted. Annotations falling below this threshold should be flagged for manual review.
- Define ambiguity parameters: Identify specific scenarios or characteristics that may lead to ambiguous annotations, such as overlapping objects or unclear boundaries. Create guidelines for handling these cases consistently.
- Establish escalation protocols: Develop a clear process for escalating difficult cases to human experts for further analysis and decision-making. This ensures that complex issues receive the necessary attention and resolution.
Defining exception handling rules provides a structured approach to managing edge cases and exceptions. This approach reduces the potential for errors and inconsistencies in your annotated data.
Manual Intervention and Correction
Even with advanced automatic annotation tools, manual intervention and correction are sometimes necessary. Human expertise is crucial for refining and validating annotations. Consider these approaches to manual intervention:
- Expert review: Assign experienced annotators or subject matter experts to review and correct annotations flagged as exceptions. Their domain knowledge and critical thinking skills can help resolve ambiguities and ensure accurate annotations.
- Collaborative correction: Foster a collaborative environment where multiple annotators can discuss and reach consensus on challenging cases. This approach leverages collective knowledge and promotes consistency in handling edge cases.
- Feedback loop: Implement a feedback mechanism that allows annotators to provide input on recurring edge cases or areas for improvement. This valuable feedback can be used to refine the automatic annotation model and exception handling rules over time.
| Industry | Edge Case Handling Strategy | Impact |
|---|---|---|
| Athletic Performance Analysis | Managed workforce reviewed low-confidence annotations | Improved model performance and prevented AI drift |
| Business Intelligence | Human judgment for sensitive edge cases | Accurate categorization of social media content |
| Mobile Shopping App | Humans-in-the-loop for OCR exceptions | Faster turnaround times and higher accuracy |
The importance of human-computer collaboration in successful automation cannot be overstated. Having a diverse toolkit, including access to training and external workforces, is essential for effectively and efficiently addressing exception processing.
Incorporating manual intervention and correction into your automatic annotation workflow helps handle edge cases and exceptions effectively. This ensures the quality and reliability of your annotated data.
Monitoring and Optimizing Your Automatic Annotation Workflow
To keep your automatic annotation workflow efficient and effective, it's key to monitor and optimize its performance continuously. Tracking metrics like accuracy, precision, Mean Average Precision (mAP), and Intersection Over Union (IoU) offers insights into your workflow's strengths and weaknesses. These performance metrics are crucial for maintaining high-quality data annotation across tasks, from facial recognition to automated license plate recognition (ALPR).
Regularly analyzing your workflow helps identify bottlenecks and areas for improvement. Look for delays or inefficiencies, such as slow manual review processes or cumbersome data transfer methods. Addressing these issues can streamline your workflow and increase productivity. Also, consider using the scalability and customizability of leading annotation tools like Keylabs.
Tracking Key Performance Metrics
Effectively monitoring your automatic annotation workflow requires tracking key performance metrics. These metrics offer insights into the accuracy, precision, and performance of your annotation tools and processes. By monitoring accuracy, precision, mAP, and IoU, you can quickly spot areas needing improvement and optimize your workflow. Use the analytics and reporting from your chosen annotation platform for a comprehensive view of performance.
Identifying Bottlenecks and Improvement Opportunities
Regularly analyzing your automatic annotation workflow for bottlenecks and inefficiencies is crucial. Common issues include manual review delays, data transfer issues, and team collaboration problems. Identifying these bottlenecks allows for targeted optimizations to streamline your workflow and enhance efficiency. Consider parallel annotation workflows, dividing the workload among annotators and reviewers on different data subsets. This approach can significantly cut down annotation time while maintaining accuracy and consistency.
FAQ
What is automatic annotation?
Automatic annotation leverages AI to speed up and enhance the labeling of images and videos for computer vision models. This process significantly impacts the precision and outcomes of these models.
What are the benefits of automatic annotation?
The advantages include cost savings, quicker annotation, and consistent, unbiased results. These benefits are crucial for computer vision and other models reliant on algorithmic processing.
How do I prepare my dataset for automatic annotation?
Preparing your dataset for automatic annotation is crucial. Start by organizing and cleaning your data, ensuring it's formatted correctly for the annotation tool. Choose the right file formats, whether images, videos, or specialized medical files like DICOM and NIfTI.
What factors should I consider when choosing an automatic annotation tool?
When selecting an automatic annotation tool, consider its capabilities, ease of use, and integration with your workflow. Look at options like open-source, low-code/no-code, and active learning solutions. Also, evaluate comprehensive platforms offering a broad range of features.
How do I set up an automatic annotation workflow?
To set up automatic annotation, create a new workflow in your chosen tool. Define tasks and rules, and assign annotators and reviewers.
What is involved in training an automatic annotation model?
Training an automatic annotation model begins with initial data, manually annotated by experts. Use this data for training and evaluate the model's performance. Refine the model iteratively, fine-tuning based on annotator and reviewer feedback to enhance accuracy and efficiency.
How can I integrate automatic annotation into my existing workflow?
Many tools offer API integration for seamless connection with other systems. Automate data transfer to the annotation tool and trigger downstream processes upon completion. The Trigger block facilitates systematic automation.
How can I ensure the quality of annotations?
Ensure quality through a robust review process. Use manual review by experts and automated checks. The To Review block in the workflow assigns reviewers to check annotations. Approved annotations are marked as completed, while rejected ones are sent for re-annotation.
How should I handle edge cases and exceptions in automatic annotation?
Define rules for handling exceptions when the model encounters ambiguous cases. This may require manual correction by experts. Incorporate these processes into your workflow for consistent and accurate annotations.
How can I monitor and optimize my automatic annotation workflow?
Monitor and optimize by tracking performance metrics like speed, accuracy, and throughput. Use platform-provided tools for visibility into the process. Regularly analyze the workflow to identify and streamline bottlenecks. Parallel workflows allow annotators and reviewers to work independently on subsets of data.