Leveraging Prompt-Based Annotation with Large Language Models
In recent years, large language models (LLMs) have become powerful tools for various natural language processing tasks. Among these models' many capabilities, their ability to perform prompt-based annotation is increasingly gaining attention. Prompt-based annotation uses natural language prompts to guide LLMs in labeling or interpreting textual data.
Systems based on operational learning are flexible, allowing them to quickly adapt to a variety of domains and tasks without lengthy retraining. LLMs often produce results that reflect human intuition by formulating annotation tasks in spoken or descriptive language. This makes them particularly useful for subjective or nuanced labeling tasks where complex rules may not work. In addition, prompt-based annotation offers a scalable alternative in environments where labeled data is scarce or expensive.
Key Takeaways
- LLMs can outperform human annotators in specific data labeling tasks.
- Prompt-based annotation offers improved efficiency and accuracy.
- Few-shot and chain-of-thought prompting enhance model performance.
- LLMs streamline data analysis in social research.
- This technology has wide-ranging applications across industries.

What is Prompt-Based Annotation?
Prompt-based annotation is a method of labeling or interpreting data using natural language prompts to guide the behavior of a large language model (LLM). Instead of using fixed rules or manual annotations, this approach involves creating a prompt that describes the task, question, or purpose of the labeling in simple language. The LLM then generates a response that serves as an annotation, such as identifying sentiment, labeling named entities, summarizing key information, or categorizing text based on the instructions provided in the prompt.
This method takes advantage of LLM's ability to generalize tasks and understand context from language alone, allowing you to annotate data without needing a traditional labeled dataset or a finely tuned model. This can be particularly useful in cases where labeled data is limited, tasks are subjective or complex, or rapid annotation across multiple domains is required. Prompt-based annotation offers a flexible, scalable, and often cost-effective alternative to manual or rule-based approaches. However, careful operational design and quality control are also required to ensure reliable results.
Importance in NLP
Cue-based annotation is increasingly essential in Natural Language Processing (NLP) as it solves several long-standing problems. Traditional NLP systems are often heavily dependent on large, manually labeled datasets, which are expensive, time-consuming, and sometimes inconsistent due to human subjectivity. Prompt-based annotation allows LLM to generate labels on the fly based on task instructions, which significantly reduces the need for manual effort.
In addition, the method increases the flexibility and generalizability of NLP workflows. Since the prompts are written in natural language, they can be adapted to new tasks or domains without retraining the underlying model. This makes operational annotation well suited for rapidly evolving tasks or where definitions and requirements change over time, such as new topics in social media or dynamic regulatory environments. It also supports the development of more responsive and interactive artificial intelligence systems that can adjust their behavior by quickly tuning rather than updating the model.
Most importantly, cue-based annotation marks a shift to more human-centered language processing. This allows systems to respond to task descriptions that resemble how humans communicate goals and expectations, bringing annotations closer to human reasoning and contextual understanding.
The Role of Large Language Models
Large Language Models (LLMs) are the backbone of cue-based annotation, providing the interpretive and generative capabilities to respond accurately. These models are trained on many diverse texts, allowing them to capture nuances in language, context, and meaning. As a result, they can perform a wide range of annotation tasks with little or no training. Whether it's labeling sentiment, identifying named entities, summarizing content, or drawing conclusions, LLMs can produce high-quality annotations with only well-designed prompts.
The strength of LLMs in cue-based annotation lies in their ability to generalize. They can handle a variety of phrases, incomplete information, and even ambiguous cases more gracefully than rule-based or narrow AI systems. With the correct prompt, an LLM can interpret complex instructions, adjust response style, and provide consistent labels across a dataset.
In addition, LLMs allow for rapid scaling of annotation processes without proportionally increasing costs. Traditional pipelines often encounter bottlenecks in data labeling, especially when expert annotators are required. In contrast, LLMs can generate thousands of annotations in minutes and even support interactive workflows where reviewers improve the model results.
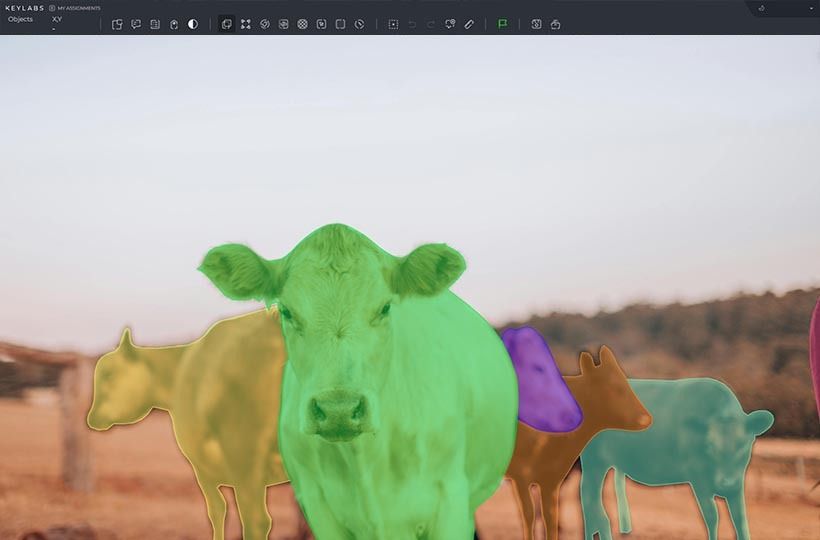
Applications in Data Annotation
Prompt-based annotation has many applications across the data annotation landscape, offering a fast and flexible way to generate labeled data for various NLP tasks. One of the most common use cases is sentiment analysis, where LLMs can be prompted to categorize text as positive, negative, or neutral based on tone and context. They are also effective in object recognition tasks, identifying names, locations, organizations, and other specific objects directly from raw text, guided by appropriate cues. Topic classification, intent detection, and summarization are other key areas where cue-based annotation is increasingly being used to supplement or replace manual labeling.
In addition to basic classification, cue-based annotation is also valuable for more complex or nuanced tasks that are usually difficult to automate. In conversational artificial intelligence, these models can comment on dialog data regarding intent, emotion, or turn-taking structure, which is essential for training more responsive and context-aware systems. The adaptability of the prompts allows you to easily switch between detailed and broad labeling schemes without changing the model configuration or relearning from scratch.
Prompt-based annotation supports semi-automated and human workflows, where the LLM provides an initial label, and the reviewer checks or corrects it. This speeds up the annotation process and can improve consistency by offering a model-generated baseline for human annotators to work from. This approach can provide better coverage and reduce bias in scenarios where little annotated data or labeling is subjective.
Benefits of Prompt-Based Annotation
- Efficiency. Prompt-based annotation significantly speeds up data labeling by automatically using large language models to automatically generate annotations based on natural language instructions. This eliminates the need for time-consuming manual annotations, especially in large-scale or time-sensitive projects, and reduces the overall cost and time to create a dataset.
- Adaptability. One of the most significant advantages is the ease of adaptation to new tasks or domains. Since the tips are written in natural language, they can be quickly changed to suit different purposes without retraining the model. For example, changing a sentiment classification task to an emotion detection task can be as simple as rephrasing the prompt.
- Scalability. Once you've created a tip that works well, the model can quickly annotate large amounts of data. This makes it possible to generate or augment datasets that would otherwise take weeks or months to annotate manually, supporting rapid development and iteration in NLP projects.
- Consistency. Prompt-based annotation can reduce the inconsistencies that often occur with human annotation, especially in subjective or complex tasks, by standardizing the instructions for completing tasks through prompts. While the model output may still require some revision, a well-formulated prompt can guide the model in applying the same criteria uniformly to the dataset.
- Human integration in the loop. The prompt-based annotation works well in hybrid workflows, where the model generates initial labels, and human annotators verify or refine them. This collaboration can increase speed and accuracy, delivering high-quality datasets while increasing automation efficiency. This setup is ideal for gradually improving model performance while maintaining manual oversight.
Challenges in Implementing Prompt-Based Annotation
- Fast sensitivity. The results of large language models can be susceptible to how a clue is worded. Small changes in wording, structure, or even punctuation can lead to significant differences in results. This makes it challenging to ensure consistent performance, especially when scaling across tasks or annotators.
- Variability and inconsistency. Unlike rule-based systems, LLMs can produce slightly different outputs for similar inputs, especially when temperature or randomness is introduced during generation. This can lead to inconsistencies in labeling, especially in outlier cases or ambiguous data.
- Lack of ground truth. Since prompt-based annotation relies on model output rather than predefined golden labels, it can be challenging to assess the accuracy of the annotations. In many cases, there are no existing benchmarks or labeled data for comparison, making it difficult to determine the quality of annotations without human review.
- Bias and misinterpretation. LLMs can inherit and reproduce biases from their training data, affecting how they respond to prompts. This is especially important when annotating sensitive content, interpreting subjective language, or processing demographic information.
- Limited transparency and control. While LLMs are powerful, they are also opaque. Understanding why a particular output was generated can be challenging, which limits interpretation and makes debugging difficult.
Comparing Traditional and Prompt-Based Annotation
Traditional annotation and prompt-based annotation are two approaches to labeling data in natural language processing, and each has its characteristics. Traditional annotation relies on human annotators manually labeling data according to set guidelines. This method is often detailed and accurate, especially when domain experts are involved, but it can be slow, expensive, and difficult to scale. It requires ongoing training and supervision to maintain quality, and changing the criteria for labeling usually involves revising documentation, retraining annotators, and re-running large portions of the dataset.
On the other hand, prompt-based annotation uses large language models to generate labels based on natural language automatically prompts that describe tasks. This allows annotations to be created much faster and with greater scalability, especially when dealing with large datasets or rapidly changing information. Since the prompts can be easily revised, the approach is more flexible when learning new tasks or adjusting definitions. However, this largely depends on how well the task is described, and the model can introduce variability or errors if the prompt is poorly designed or the data is ambiguous.
Leveraging Feedback Mechanisms
Feedback mechanisms in prompt-based annotation can significantly improve the quality and reliability of annotations produced by large language models (LLMs). These feedback loops allow continuous improvement of the prompts and the model output, ensuring that the results meet the desired standards. By incorporating human or automated feedback into the system, correcting inaccuracies, adjusting inconsistencies, and improving overall performance becomes possible.
One common approach to integrating feedback is to use human-in-the-loop systems, where reviewers evaluate the initial annotations generated by the model and provide corrections or suggestions. This process allows for real-time adjustments, improving the consistency and accuracy of annotations over time. For example, if the LLM misinterprets a prompt or generates a label that does not match human judgment, feedback can be provided to fine-tune the model's behavior in future tasks.
Automated feedback mechanisms can also play a crucial role. These systems can analyze model annotation patterns and identify improvement areas based on predefined quality metrics or benchmarking against a reference dataset.
Summary
To summarize, using prompt-based annotation with large language models represents a promising approach to improve data labeling in natural language processing. By leveraging the flexibility and scalability of LLM, this method offers significant advantages in terms of efficiency, adaptability, and cost-effectiveness, especially for large or rapidly changing datasets. While it does pose challenges, such as operational sensitivity and the potential for inconsistency, these can be mitigated through careful design and integration of feedback mechanisms. As the technology continues to evolve, prompt-based annotation will likely play an increasingly important role in automating data preparation, supporting various applications from sentiment analysis to specialized domain tasks. It is a powerful tool that can accelerate NLP workflows while maintaining high-quality annotation standards.
FAQ
What is a prompt-based annotation?
Prompt-based annotation is a groundbreaking method for labeling data. It uses large language models (LLMs) like ChatGPT to interpret and label data efficiently.
How does prompt-based annotation differ from traditional annotation methods?
Prompt-based annotation stands out for its speed, scalability, and cost-effectiveness. It can process vast amounts of data much faster than human annotators, making it perfect for large-scale AI projects.
What are the key benefits of using prompt-based annotation?
The key advantages include enhanced efficiency in data processing, improved labeling accuracy and consistency, reduced annotation bias, and the ability to handle large data volumes quickly.
What are the challenges in implementing prompt-based annotation?
Key challenges include crafting unambiguous prompts that consistently yield accurate annotations, addressing current language models' limitations and potential biases, and managing the computational resources needed for large-scale projects.
How can human feedback be incorporated into prompt-based annotation systems?
Human feedback can be integrated by setting up efficient mechanisms to collect and incorporate human judgments, focusing on instances where LLM annotations may be inaccurate or uncertain.
