Master Data Labeling: Techniques That Enhance AI Accuracy
Through the process of assigning context or meaning to data, machine learning algorithms can learn and make predictions. There are different types of data that need to be labeled, including structured and unstructured data such as images, videos, 3D data, audio, and text. The importance of data labeling varies depending on the type of machine learning, whether it is supervised, unsupervised, or reinforcement learning. In supervised learning, labeled data is used to train models, while unsupervised learning analyzes and clusters unlabeled data. Data annotation is crucial in reinforcement learning to maximize rewards. To achieve high-quality data labels, it is essential to follow clear guidelines, choose the right tools, validate the results, and maintain the data.

Key Takeaways:
- Data labeling is crucial for the accuracy and performance of AI models.
- Structured and unstructured data require different data labeling techniques.
- Data labeling is important in supervised, unsupervised, and reinforcement learning.
- Following best practices ensures effective data labeling.
- Data labeling techniques enhance the accuracy of machine learning models.
Importance of Data Labeling in AI Accuracy
Data labeling plays a crucial role in enhancing AI accuracy and improving the performance of machine learning models. The process of labeling data involves assigning context or meaning to the data, enabling machine learning algorithms to learn and make accurate predictions. This is particularly important in supervised learning, where labeled data is used to train models and predict outcomes. Without high-quality data labels, the accuracy of AI models may be compromised, leading to suboptimal performance.
In unsupervised learning, data labeling helps in analyzing and clustering unlabeled data, enabling the identification of patterns and insights that can inform decision-making. Reinforcement learning, on the other hand, maximizes rewards through algorithmic actions, and accurate data labeling is essential to ensure optimal outcomes.
The focus on data labeling has intensified as organizations recognize the significant impact it has on the performance of AI models. Data-centric AI, a new paradigm in machine learning, emphasizes the importance of high-quality data and accurate labels to improve the accuracy and reliability of AI systems.
By understanding the different types of machine learning and the role of data labeling, organizations can enhance the accuracy of their AI systems and achieve better results. With the right data labeling techniques and practices, machine learning models can be trained on accurate and reliable data, resulting in improved AI accuracy and performance.
Benefits of Accurate Data Labeling in Machine Learning
Accurate data labeling in machine learning offers several benefits:
- Increased AI accuracy: Reliable data labels enable the training of machine learning models to accurately classify and predict outcomes.
- Improved decision-making: Data labeling facilitates the analysis and clustering of unlabeled data, providing valuable insights for informed decision-making.
- Enhanced model performance: Accurate data labeling improves the performance and reliability of AI models, leading to better results and outcomes.
- Optimized resource allocation: With precise data labels, organizations can efficiently allocate resources and focus on areas that require attention.
Example: Impact of Data Labeling on Image Recognition
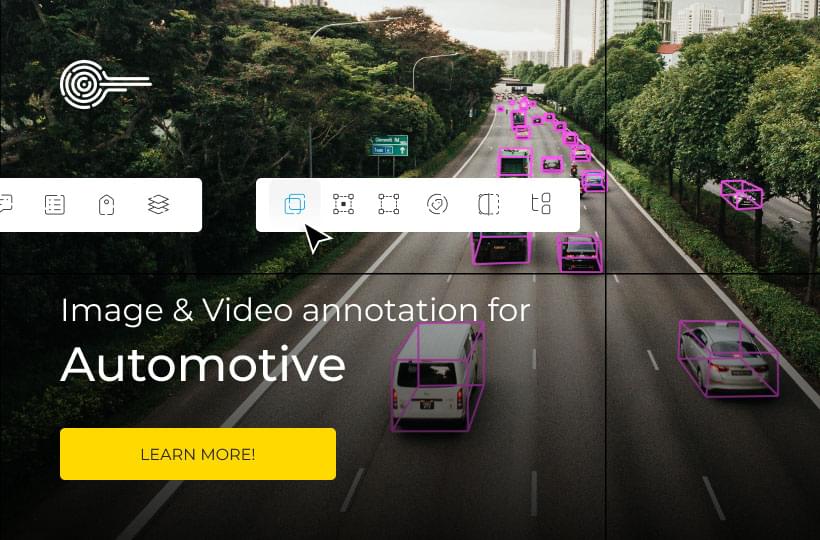
For example, in image recognition tasks, data labeling is crucial to train models to correctly identify objects, detect defects, and perform diagnostic imaging. Accurate data labels enable AI systems to make accurate predictions, resulting in improved image recognition accuracy and overall model performance.
Data Labeling Techniques for Various Data Types
When it comes to data labeling, different types of data require specific techniques to ensure accurate and high-quality labeling. From structured data found in relational databases to unstructured data such as images, videos, 3D data, audio, and text, each type requires a tailored approach. Let's explore some of the common data labeling techniques for various data types:
Structured Data Labeling
In structured data, information is highly organized within a relational database. Data labeling techniques for structured data involve classifying and assigning labels to specific fields or attributes. This labeling process helps in data analysis, pattern recognition, and prediction models.
Unstructured Data Labeling
Unstructured data encompasses a wide range of formats, including images, videos, 3D data, audio, and text. Each type of unstructured data requires specific data labeling techniques to enable machine learning algorithms to understand and process the information accurately. Let's look at some examples:
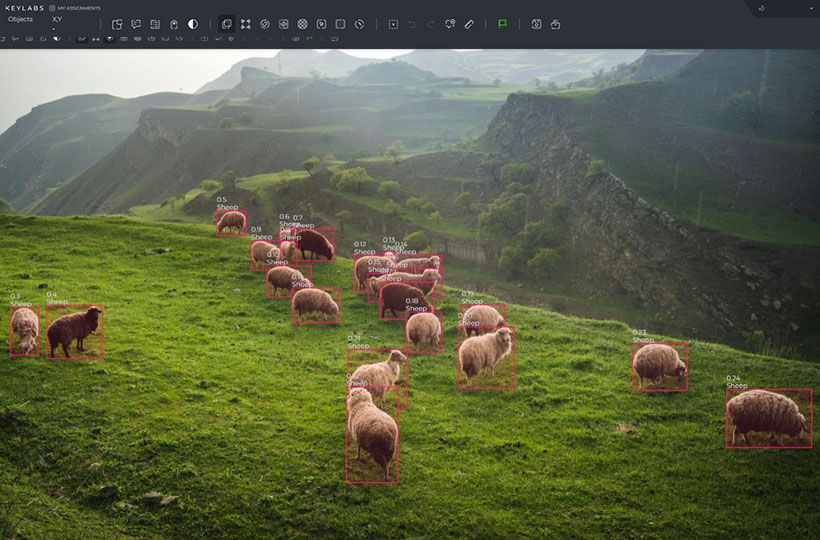
- Image Data Labeling: Image data labeling techniques involve annotating objects, regions of interest, or semantic segments within the image. This enables applications such as face recognition, defect detection, and diagnostic imaging.
- Video Data Labeling: Video data labeling involves labeling frames or sequences within a video. This is essential for applications like autonomous vehicles, action recognition, and fitness apps.
- 3D Data Labeling: Labeling 3D data, including LiDAR and Radar data, helps models understand depth, spatial relationships, and scene perception. This is crucial for applications like autonomous navigation and augmented reality.
- Audio Data Labeling: Audio data labeling techniques involve transcribing speech, identifying speaker diarization, or labeling sound events. This enables applications such as speech recognition, voice assistants, and machine translation.
- Text Data Labeling: Labeling text data is vital for Natural Language Processing (NLP) applications. Techniques include sentiment analysis, named entity recognition, part-of-speech tagging, and topic classification.
As the variety of data types expands, so does the need for specialized data labeling techniques. Properly labeling different data types is crucial to achieve optimal AI accuracy and generate reliable training datasets.
Best Practices for Effective Data Labeling
For organizations looking to ensure accurate and reliable data labels, following best practices in data labeling is crucial. These practices help establish clear guidelines, choose the right tools, validate data labels, and maintain data integrity. By implementing these best practices, organizations can optimize their data labeling processes and enhance the accuracy of their AI models.
Establishing Clear Guidelines
Clear guidelines are essential for ensuring consistency and accuracy in data labeling. Organizations should define the rules, standards, and criteria for labeling data. This includes providing examples, instructions, and quality expectations. Clear guidelines help labelers understand the labeling requirements and ensure uniformity across the labeled dataset. With clear guidelines, the chances of errors and inconsistencies are minimized, leading to higher-quality data labels.
Choosing the Right Tools
The choice of tools for data labeling is critical to the success of the labeling process. Organizations should consider various factors such as the data type, label type, customization options, cost, and scalability when selecting the right tools. There are different data labeling tools available in the market, ranging from manual labeling to semi-automated and fully automated solutions. The right tools enable efficient data labeling and streamline the process, saving time and effort.
Validation of Data Labels
Validation is a crucial step in data labeling that helps ensure the quality and consistency of the labeled data. By validating the labeled dataset, organizations can identify errors, anomalies, or inconsistencies and take corrective measures. This validation process may involve multiple rounds of review and feedback to improve the accuracy of the data labels. Validation ensures that the labeled data meets the desired quality standards, improving the effectiveness of AI models trained on this data.
Data Maintenance and Updates
Data labeling is an ongoing process, especially as AI models evolve and new data becomes available. Data maintenance involves adding new data, modifying existing data, or removing outdated data. Regular updates to the labeled dataset are necessary to keep the AI models up to date and ensure optimal accuracy. Organizations should have a system in place for managing data maintenance effectively.
Implementing these best practices for data labeling enables organizations to optimize the accuracy of their AI models. By establishing clear guidelines, choosing the right tools, validating data labels, and maintaining data integrity, organizations can ensure that their data labeling processes adhere to industry best practices.
Conclusion
Effective data labeling techniques play a crucial role in enhancing AI accuracy and improving machine learning models. By understanding the importance of data labeling in different types of machine learning, organizations can implement best practices to achieve accurate and reliable data labels.
Clear guidelines are essential to provide rules and standards for labeling data. This ensures consistency and accuracy in the labeling process. Additionally, choosing the right tools for data labeling is crucial, considering factors such as data type, label type, customization, cost, and scalability.
Validation is a critical step to check the quality and consistency of data labels. This helps identify any errors or inconsistencies and provides an opportunity for improvement. Data maintenance is an ongoing process that involves adding new data, modifying existing data, or removing outdated data, as AI models evolve and require updates.
As the field of AI continues to advance, the role of data labeling will become even more critical in driving optimal AI accuracy. By following the best practices outlined in this article, organizations can ensure that their data labeling techniques enhance the accuracy and performance of their AI systems.
FAQ
What is data labeling?
Data labeling is the process of assigning context or meaning to data in machine learning. It involves labeling different types of data, such as structured and unstructured data, to train and improve AI models.
Why is data labeling important for AI accuracy?
Data labeling is crucial for AI accuracy because it provides labeled data for training machine learning models. Without high-quality data labels, AI models may not perform as desired.
What are the different types of machine learning?
The different types of machine learning include supervised learning, unsupervised learning, and reinforcement learning. Each type has its own requirements for data labeling.
How does data labeling enhance AI accuracy in supervised learning?
In supervised learning, labeled data is used to train AI models. Accurate data labels enable models to classify or predict outcomes with higher accuracy.
What is the role of data labeling in unsupervised learning?
Data labeling in unsupervised learning involves analyzing and clustering unlabeled data. Accurate labeling helps uncover patterns and structures in the data.
Why is data labeling important for reinforcement learning?
In reinforcement learning, data labeling maximizes rewards through algorithmic actions. Accurate labels help models learn and make decisions to achieve desired outcomes.
What are the different types of data that require labeling?
Different types of data that require labeling include structured data, images, videos, 3D data, audio, and text. Each data type has specific labeling techniques and applications.
How does data labeling techniques vary for different data types?
Data labeling techniques vary for different data types. For example, images may require labeling for face recognition or defect detection, while text data may need labeling for Natural Language Processing (NLP) applications.
What are the best practices for effective data labeling?
The best practices for effective data labeling include establishing clear guidelines, choosing the right tools, validating the results, and maintaining the data over time.
Why is validation important in data labeling?
Validation is important in data labeling to check the quality and consistency of data labels. It helps identify errors and improve the accuracy of AI models.
How can organizations optimize data labeling?
Organizations can optimize data labeling by following best practices such as establishing clear guidelines, choosing the right tools, conducting validation, and maintaining the data as AI models evolve.