Mastering Object Detection with YOLOv8
Object detection is a critical task in computer vision, enabling machines to identify and locate objects within images or videos. YOLOv8, short for You Only Look Once Version 8, is a cutting-edge object detection model that combines the power of deep learning and real-time analysis. Built upon the success of its predecessors, YOLOv8 offers improved accuracy, faster speeds, and advanced customization options, making it an indispensable tool in various domains.
Key Takeaways:
- YOLOv8 is a state-of-the-art object detection model in computer vision.
- It combines deep learning and real-time analysis for accurate and fast object detection.
- YOLOv8 offers advanced customization options for specific requirements.
- It has applications in autonomous vehicles, surveillance systems, and medical imaging.
- With its intuitive CLI and Python implementations, YOLOv8 simplifies object detection in images, videos, and live webcam feeds.

What is YOLOv8?
YOLOv8, short for You Only Look Once Version 8, is the latest iteration of the YOLO family of object detection models. It combines the best features of its predecessors and offers improvements in speed, accuracy, and the ability to detect objects accurately in complex scenarios.
YOLOv8 is a deep learning model specifically designed for object detection. Unlike traditional object detection models that involve multiple stages and complex computations, YOLOv8 follows a single-stage approach, making it faster and more efficient. This deep learning model utilizes a neural network architecture that predicts object bounding boxes and class labels simultaneously. It can detect multiple objects in an image or video frame, making it ideal for real-time applications.
One of the main advantages of YOLOv8 is its incredible speed. It can process images and videos in real-time, even on resource-constrained devices. This is achieved by performing multi-scale predictions, allowing YOLOv8 to identify objects at different resolutions. Additionally, YOLOv8 achieves high accuracy, ensuring reliable object detection results.
YOLOv8 is trained on large datasets, making it capable of detecting a wide range of objects across various domains. It can distinguish between different object classes, such as people, vehicles, animals, and more, with high precision. This makes YOLOv8 a versatile tool for applications in fields like autonomous driving, surveillance, robotics, and retail analytics.
Furthermore, YOLOv8 implements advanced techniques, such as anchor boxes and non-maximum suppression, which enhance the model's performance and reduce false detections. These techniques improve the accuracy of object localization and help eliminate duplicate bounding boxes.
With its speed and accuracy, YOLOv8 has become one of the most popular object detection models in the deep learning community. Its versatility and real-time capabilities open up new possibilities for computer vision applications. Whether it's identifying objects in images, videos, or live webcam feeds, YOLOv8 provides a reliable and efficient solution for object detection tasks.
Getting Started with YOLOv8 Object Detection
Custom object detection using YOLOv8 involves several essential steps to set up and train the model. To ensure accurate object detection, it is crucial to collect high-quality data and annotate it with bounding boxes. Additionally, creating the necessary folders for training data and configuring the config.yaml file are essential. The training process utilizes the powerful Ultralytics library, where you can load the model, train it on the dataset, and evaluate its performance.
Step 1: Data Collection
In custom object detection, the foundation lies in having a diverse and comprehensive dataset. Gather a wide range of images that represent the objects you want the model to detect. These images should encapsulate various angles, lighting conditions, and object variations to create a robust training dataset.
Step 2: Data Annotation
Once you have the dataset, the next step is to annotate the images with bounding boxes around the objects of interest. Data annotation tools like LabelImg or RectLabel can help streamline the annotation process by allowing you to draw precise bounding boxes around the objects.
Step 3: Folder Setup
Organize your data by creating the necessary folders for the training process. Set up separate folders for images, annotations, and configuration files to ensure a clear and organized workflow.
Step 4: Configuring YAML File
The config.yaml file serves as the heart of the YOLOv8 training process. It contains crucial information such as the paths to your dataset, model hyperparameters, and training parameters. Make sure to configure this file correctly to optimize your object detection results.
Step 5: YOLOv8 Training
Using the Ultralytics library, you can easily load the YOLOv8 model and train it on your annotated dataset. By running the training code, the model learns to detect the specific objects you annotated. As the training progresses, the model continuously improves its accuracy and understanding of the objects' features.
Step 6: Performance Evaluation
After training the YOLOv8 model, it is crucial to evaluate its performance. This includes measuring metrics such as mean average precision (mAP) and analyzing the model's ability to correctly detect objects in test images. Fine-tuning and tweaking the model may be necessary based on the evaluation results to achieve optimal performance.
By following these steps, you can kickstart your journey into custom object detection using YOLOv8. The next sections will dive deeper into the capabilities of YOLOv8, exploring its object detection capabilities in images, videos, and live webcam feeds.
YOLOv8 Object Detection in Images
YOLOv8, short for You Only Look Once Version 8, is a powerful object detection model that excels in performing object detection in static images. By leveraging deep learning techniques, YOLOv8 can accurately classify objects, localize their positions with bounding boxes, and recognize the objects based on their predicted class labels and probabilities.
This capability of YOLOv8 is particularly valuable in a wide range of domains such as surveillance, medical imaging, and retail analytics. Whether it's identifying potential threats in a security camera footage, detecting abnormalities in medical scans, or analyzing customer behavior in a retail store, YOLOv8 enables efficient and precise object detection in various image-based applications.
Image Classification with YOLOv8
One of the key functionalities of YOLOv8 in image detection is image classification. By analyzing the content of an image, YOLOv8 can effectively assign a specific label or class to each detected object. This process allows for comprehensive categorization of objects present in the image, enabling further analysis and decision-making based on the identified classes. For example, in a surveillance system, YOLOv8 can classify objects as 'person,' 'vehicle,' or 'animal,' providing valuable information for security monitoring purposes.
Object Localization and Recognition
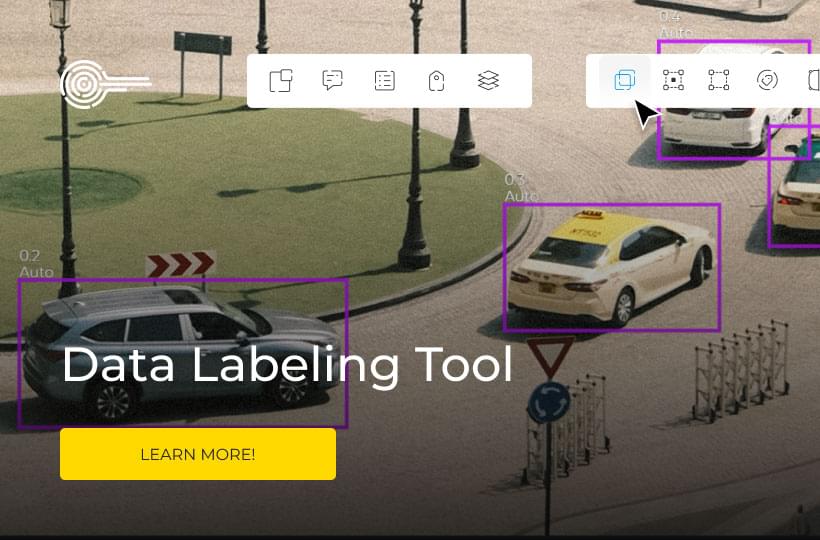
In addition to image classification, YOLOv8 performs object localization by accurately identifying the positions of objects within an image. This is achieved by drawing bounding boxes around the detected objects, indicating their precise locations. These bounding boxes encompass the objects, providing valuable visual representation and decisive information for subsequent analysis and action.
The ability of YOLOv8 to recognize objects is a crucial aspect of its object detection capabilities. By predicting the class labels and probabilities of each detected object, YOLOv8 allows for precise recognition and identification of specific objects within an image. For example, in a retail analytics scenario, YOLOv8 can recognize individual products on store shelves, enabling inventory management, customer behavior analysis, and targeted marketing strategies.
"YOLOv8's image detection capabilities, combining image classification, object localization, and object recognition, make it an invaluable tool in various domains, empowering applications such as surveillance, medical imaging, and retail analytics."
Example Use Case: Medical Imaging
An example use case that highlights the power of YOLOv8 in image detection is medical imaging. By applying YOLOv8 to analyze medical scans, healthcare professionals can benefit from its accurate object detection capabilities. YOLOv8 can detect and label medical instruments, anomalies, and specific anatomical structures, assisting in diagnosis, treatment planning, and surgical interventions.
The following table provides a comparison between YOLOv8 and traditional object detection methods in terms of image classification, object localization, and object recognition:
| Image Classification | Object Localization | Object Recognition | |
|---|---|---|---|
| Traditional Methods | Requires manual annotation and feature extraction | Relies on separate algorithms for detection | May involve complex post-processing techniques |
| YOLOv8 | Automatically classifies objects based on learned features | Accurately localizes objects with bounding boxes | Provides precise recognition and labeling of objects |
The table clearly highlights the advantages of YOLOv8 over traditional methods, showcasing its efficiency and effectiveness in image classification, object localization, and object recognition.
YOLOv8 Object Detection in Videos
YOLOv8, an advanced object detection model, is not limited to detecting objects in static images. It can also be applied to videos, enabling real-time object detection capabilities. While the process is similar to image detection, YOLOv8 processes each frame of the video individually, detecting objects and providing accurate results.
One of the key advantages of YOLOv8 is its flexibility in handling various video formats. Whether it's an MP4, AVI, or any other common video format, YOLOv8 can seamlessly analyze and detect objects in each frame, allowing for comprehensive video analysis in diverse use cases.
By leveraging YOLOv8's video detection capabilities, users can gain valuable insights and perform detailed analysis on video footage in fields like surveillance, autonomous vehicles, and retail analytics. The model accurately identifies and localizes objects in real-time while maintaining the high detection accuracy and speed YOLOv8 is known for.
Here's how the YOLOv8 object detection process works in videos:
- Input: A video file in any supported format.
- Processing: YOLOv8 breaks down the video into individual frames and processes each frame sequentially using its deep neural network architecture.
- Object Detection: In each frame, YOLOv8 detects objects based on their classes and provides bounding box coordinates for localization.
- Output: The video is annotated with bounding boxes around detected objects, allowing users to visualize and analyze the objects present in each frame.
With YOLOv8's object detection in videos, users can unlock endless possibilities for video analysis and real-time decision-making. Whether it's monitoring traffic flow, identifying objects in security footage, or understanding customer behavior in retail settings, YOLOv8 provides a powerful solution for accurately detecting and localizing objects in videos.
Evaluating Object Detection Performance in Videos
Evaluating the performance of object detection models in videos involves assessing critical metrics such as accuracy, precision, recall, and the mean average precision (mAP). These metrics help quantify the model's ability to correctly detect objects and differentiate them from the background in various frames of the video.
By employing the appropriate evaluation techniques, developers and researchers can fine-tune their YOLOv8 models, improve their accuracy, and achieve optimal results for specific video analysis tasks.
| Metrics | Definition |
|---|---|
| Accuracy | The percentage of correctly detected objects compared to the total number of objects in the video. |
| Precision | The proportion of true positive detections out of all positive detections, indicating the model's ability to identify objects accurately. |
| Recall | The proportion of true positive detections out of the actual number of objects present in the video, representing the model's ability to detect all objects. |
| Mean Average Precision (mAP) | An overall performance measure that combines accuracy, precision, and recall to evaluate the model's object detection capabilities across multiple frames. |
YOLOv8 Object Detection in Live Webcam Feed
YOLOv8 offers the capability to perform live object detection in a webcam feed, providing real-time analysis of the captured video. This powerful feature allows for continuous monitoring and detection of objects as they appear in the webcam feed. Whether it's in a video conference, a surveillance system, or any application that requires live object detection, YOLOv8 can deliver accurate results.
By leveraging YOLOv8's advanced deep learning algorithms, the model analyzes each frame of the webcam video, instantly identifying and classifying objects of interest. The real-time nature of YOLOv8 enables prompt action or intervention whenever necessary, ensuring timely responses to detected objects.
What sets YOLOv8 apart is its ability to capture objects accurately even under challenging conditions, such as low video quality or poor lighting. This reliability makes YOLOv8 a valuable tool for applications where real-time analytics and object recognition are crucial factors.
For instance, in video surveillance, YOLOv8 can seamlessly detect and track people, vehicles, or other objects of interest within the webcam feed. By promptly identifying and capturing these objects, security personnel can effectively monitor the environment, ensuring safety and mitigating potential risks.
The applications of YOLOv8 in live webcam feeds go beyond surveillance systems. It can also be used for real-time analytics, such as people counting in a retail store or monitoring the flow of vehicles on a busy street. The real-time detection and classification capabilities of YOLOv8 empower businesses to gain insights from live video streams, enabling them to make data-driven decisions and optimize their operations.
With YOLOv8's object detection in live webcam feeds, the possibilities are vast. Its speed, accuracy, and ability to handle challenging visual conditions make it a valuable resource in various domains, from security to analytics. By integrating YOLOv8 into live video applications, users can enhance their capabilities, improve decision-making, and unlock the full potential of real-time object detection.
YOLOv8 and Custom Configurations
While utilizing YOLOv8 for object detection, its intuitive command-line interface (CLI) and low-code Python solutions provide a straightforward approach. However, certain scenarios may require custom configurations to meet specific requirements. This includes fine-tuning bounding box aesthetics or incorporating additional tasks such as object counting, which may require coding utilizing computer vision packages such as cv2 or supervision.
Installation and Setup of YOLOv8
To get started with YOLOv8, you need to install the Ultralytics package. This can be done by running a simple pip command in your terminal. The package includes the necessary libraries and dependencies for using YOLOv8 in Python. Once installed, you can easily import the YOLO model and begin using it for object detection tasks.
Installation Steps:
- Open your terminal
- Run the following pip command to install the Ultralytics package:pip install ultralytics
Once the Ultralytics package is successfully installed, you can start leveraging the power of YOLOv8 for object detection. The package provides a user-friendly interface and Python API, making it easy to integrate YOLOv8 into your computer vision projects.
Advantages of YOLOv8 over Previous Versions
YOLOv8 offers several advantages compared to previous versions of the YOLO model. It combines improved accuracy, faster speeds, and fewer parameters, making it a highly efficient and advanced object detection model.
Improved Accuracy
YOLOv8 boasts improved accuracy in object detection, delivering better Mean Average Precision (mAP) compared to its predecessors. This enhanced accuracy ensures more reliable and precise identification of objects in various scenarios, contributing to enhanced performance and overall effectiveness.
Faster Speeds
One of the key advantages of YOLOv8 is its ability to achieve fast inference speeds without compromising accuracy. By implementing advanced optimization techniques, the model can rapidly process input data, allowing for real-time object detection in dynamic environments. This accelerated performance opens up possibilities for applications that require quick response times, such as autonomous vehicles and live video analysis.
Fewer Parameters
YOLOv8 is designed to be more efficient and streamlined, requiring fewer parameters compared to previous versions. This reduction in parameters results in a more lightweight model, reducing computational complexity and memory requirements. The fewer parameters also contribute to faster training times, enabling users to develop object detection models more efficiently.
| Advantages | Description |
|---|---|
| Improved Accuracy | YOLOv8 offers better Mean Average Precision (mAP) compared to earlier versions, ensuring more accurate object detection. |
| Faster Speeds | The model achieves fast inference speeds, enabling real-time object detection in dynamic environments. |
| Fewer Parameters | YOLOv8 requires fewer parameters, resulting in a more efficient and lightweight model with faster training times. |
Limitations and Future Developments
While YOLOv8 is a powerful and efficient object detection model, it does have certain limitations. These limitations are important to consider when using the model for specific tasks. However, it is worth noting that the YOLOv8 project is continuously evolving, and future developments may address these limitations, providing even more flexibility and customization options for users.
YOLOv8 Limitations
1. Training on Custom Datasets: Customizing YOLOv8 for specific object detection tasks requires expertise in data collection, annotation, and model training. Users need to carefully curate high-quality training data and meticulously annotate objects to ensure accurate detection.
2. Advanced Customization: While YOLOv8 offers various pre-defined configurations and customization options, advanced customization and fine-tuning may require additional coding skills and computer vision expertise. This can pose challenges for users who are not proficient in these areas.
3. Resource Intensive: YOLOv8 requires substantial computational resources, including GPUs, to achieve real-time object detection performance. Users with limited hardware capabilities may face difficulties in using YOLOv8 efficiently.
Future Developments in Object Detection
The field of object detection continues to evolve rapidly, and future developments are likely to address the limitations of YOLOv8. Here are some potential areas of improvement:
- Automatic Hyperparameter Tuning: Simplifying the process of model configuration and hyperparameter tuning could make YOLOv8 more accessible to users with limited technical expertise.
- Transfer Learning and Pre-trained Models: Incorporating transfer learning techniques and providing pre-trained models for specific domains could assist users in customizing YOLOv8 for their applications with minimal efforts.
- Enhanced Customization Tools: Intuitive graphical user interfaces (GUIs) and automation tools can streamline the customization process, allowing users to fine-tune the model parameters easily and efficiently.
These future developments would empower users to leverage the full potential of YOLOv8 for their object detection tasks, while minimizing the need for extensive coding and technical knowledge.
Conclusion
YOLOv8 is a state-of-the-art object detection model that combines speed, accuracy, and customization options to deliver highly efficient results. Its applications span across various industries, including autonomous vehicles, surveillance systems, and medical imaging. With its user-friendly command line interface (CLI) and Python implementation, YOLOv8 streamlines the process of object detection in images, videos, and live webcam feeds.
As computer vision technology continues to advance, YOLOv8 paves the way for new possibilities in real-time object recognition and analysis. Its ability to rapidly detect and classify objects makes it invaluable in scenarios where quick decision-making is vital, such as self-driving cars navigating complex environments or security systems monitoring crowded areas.
The future of YOLOv8 holds exciting prospects. As researchers and developers continue to refine the model, we can anticipate further improvements such as enhanced accuracy and even faster processing speeds. This will enable YOLOv8 to tackle even more complex object detection tasks and open doors to innovative applications in computer vision.
In summary, YOLOv8 revolutionizes the field of object detection with its cutting-edge advancements. Its speed, accuracy, and flexibility make it a go-to choice for professionals in the computer vision industry. With ongoing advancements and emerging applications, YOLOv8 is set to shape the future of object detection and drive the evolution of computer vision technology.
FAQ
What is YOLOv8?
YOLOv8, short for You Only Look Once Version 8, is the latest iteration in the YOLO family of object detection models. It is a deep learning model known for its speed and accuracy in detecting objects in images, videos, and live webcam feeds. YOLOv8 offers significant advancements in object detection, making it an essential tool in computer vision applications.
How do I get started with YOLOv8 Object Detection?
To get started with YOLOv8 object detection, you need to collect high-quality data, annotate the data with bounding boxes, create the necessary folders for training data, and set up the config.yaml file. The training process involves using the Ultralytics library and running code to load the model, train it on the dataset, and evaluate its performance.
How does YOLOv8 detect objects in images?
YOLOv8 performs object detection in static images by classifying objects, localizing their positions using bounding boxes, and recognizing the objects based on their predicted class labels and probabilities. It is a powerful tool for tasks such as surveillance, medical imaging, and retail analytics, providing accurate object detection and classification.
Can YOLOv8 detect objects in videos?
Yes, YOLOv8 can detect objects in videos. The process is similar to image detection, but the input source is a video file instead of a static image. YOLOv8 can handle various video formats, making it flexible for different use cases. It can detect objects in each frame of the video, providing real-time object detection capabilities.
How can I use YOLOv8 for live object detection in a webcam feed?
YOLOv8 can be used for live object detection in a webcam feed by continuously analyzing each frame of the video in real-time. It accurately captures objects, even in low-quality video and poor lighting conditions, making it valuable for applications such as video surveillance and real-time analytics.
Can I customize YOLOv8 for specific requirements?
Yes, YOLOv8 offers an intuitive CLI and low-code Python solutions for easy object detection. However, advanced customization and fine-tuning may require additional coding using computer vision packages like cv2 or supervision. These packages allow you to adjust the aesthetics of bounding boxes or perform additional tasks, such as object counting, to meet your specific needs.
How do I install and set up YOLOv8?
To install YOLOv8, you need to install the Ultralytics package using a simple pip command in your terminal. The package includes the necessary libraries and dependencies for using YOLOv8 in Python. Once installed, you can easily import the YOLO model and begin using it for object detection tasks.
What are the advantages of YOLOv8 over previous versions?
YOLOv8 offers several advantages over previous versions of the YOLO model. It provides improved accuracy in object detection, achieving better mean average precisions (mAP) and faster speeds. Additionally, YOLOv8 requires fewer parameters to achieve its performance, making it a more efficient and streamlined model.
What are the limitations of YOLOv8 and future developments?
While YOLOv8 is a powerful and efficient object detection model, it does have certain limitations. Advanced customization and fine-tuning may require additional coding and expertise. However, the YOLOv8 project continues to evolve, and future developments may address these limitations, providing even more flexibility and customization options for users.
Source Links
- https://medium.com/@tejasdalvi927/mastering-custom-object-detection-with-yolov8-a-step-by-step-guide-to-precision-in-computer-bec719186aa7
- https://towardsdatascience.com/enhanced-object-detection-how-to-effectively-implement-yolov8-afd1bf6132ae
- https://kean-chan.medium.com/performing-inference-with-yolov8-and-retraining-with-custom-dataset-84d75c304531