Merging Multiple Labeled Datasets: Ensuring Consistency and Quality
Companies work with multiple data sets from different sources in a data-rich environment. The challenge is to combine the disparate pieces of information into a single whole. This process is called data set fusion. Data integration involves a detailed review of the data formats to achieve the accuracy and usefulness of the result.
Below, we will examine strategies for overcoming common problems, tools, and techniques for maintaining data quality during the fusion process.
Quick Take
- Fusing datasets helps create quality datasets.
- Inconsistent data formats lead to misinterpretation and poor decision-making.
- Data quality needs to be maintained throughout the data fusion process.
- The correct data fusion strategies increase data reliability.

Understanding Dataset Fusion Strategies
Fusing data sets is essential for thorough analysis and deeper insights. It allows you to:
- Create robust training sets for machine learning models.
- Find hidden patterns in different data sources.
- Improve data quality through cross-validation.
Types of data sets that are merged
- Time series data from different sources.
- Customer information from multiple touchpoints.
- Financial data from different departments or systems.
- Demographic data with behavioral analytics.
Dataset fusion strategies in different industries
- Healthcare merges patient records with clinical trial data.
- Finance merges transaction data with market trends.
- Retail combines online and in-store customer behavior.
- Manufacturing combines production data with product delivery information.
Problems of merging labeled data and their solutions
Maintaining consistency of labels in datasets.
- Handling ambiguous annotations.
- Maintaining the integrity of training sets.
- Working with complex and scalable data.
- Typically, different data sources are used to obtain customer information. This diversity makes it difficult to combine labeled data.
Different joining methods are used to overcome these problems. Methods such as inner, left, and outer joins are selected based on the data structure and objectives.
- Inner join returns only records with typical values in both data sets. Used when related information is needed.
- Left join keeps all records from the left data set and adds corresponding records from the right. Used when you need to keep all data from the main set.
- Outer join returns all records from both sets where there is no match. It is used for a complete analysis of all available data.
Preparing Datasets for Merging
Preprocessing is important for preparing datasets for merging. It properly combines data from different sources and allows for accurate and reliable analyses. Let’s look at the main techniques:
Fusion Techniques and Methodologies
The fusion of data sets is an important data analysis process that uses various methods to combine information. These methods ensure data integration and increase the reliability of the data sets.
Consistency in federated datasets
Duplicate records are a significant data quality issue. Methods for comparing unique identifiers and using fuzzy matching algorithms help to avoid these issues.
Data normalization is essential for maintaining consistency in federated datasets. This includes:
- Converting units to a common standard.
- Standardizing date and time formats.
- Normalizing text fields for consistent representation.
- Data consistency measures increase operational efficiency.
This ensures that reliable datasets are created that help you obtain accurate information and make informed decisions.
Quality Assurance Measures
After the merge, various validation techniques are used to maintain data quality. These include:
- Automated software to detect anomalies.
- Regular updates and improvements to data quality practices.
- Quarterly validations to ensure data reliability.
Data integrity testing
Data integrity testing helps to prevent unauthorized changes to data during storage or transmission. This method is implemented using:
- Format and range validation.
- Automated deduplication tools to eliminate redundancy.
- End-user feedback loops for proactive corrections.
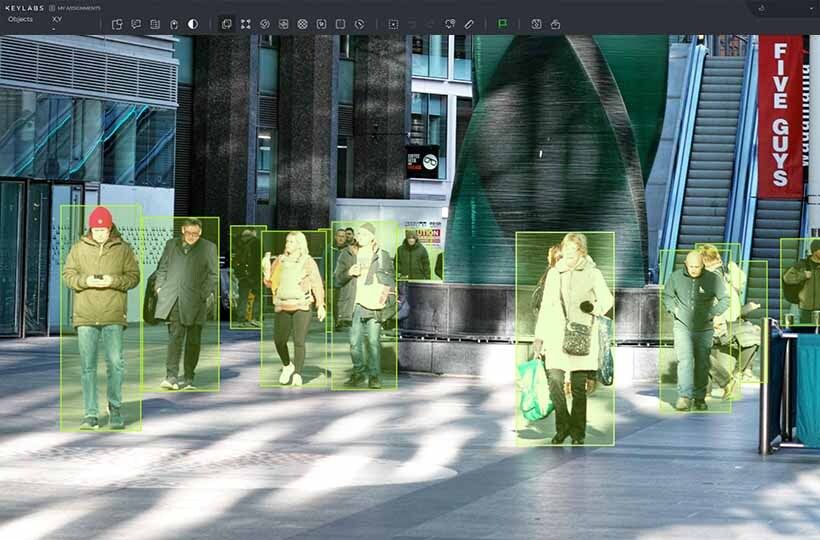
Evaluate data set consistency
- Uniqueness testing to detect duplicate records.
- Checking the integrity of relationships to ensure that foreign keys in related tables are consistent.
- Checking the consistency of values.
- Identifying missing or incorrect data and verifying that it conforms to formats.
Dataset Integration Tools and Software
Dataset integration tools and software help you combine disparate information, ensuring consistency and relevance to your analytical tasks. Automated features help you identify duplicates, handle missing values, and resolve conflicts between records. GUIs and software libraries provide flexibility in configuring integration parameters. Support for multiple file formats simplifies the integration of information from databases, spreadsheets, and cloud storage. Features such as previewing results, data quality validation, and report generation improve the accuracy of your analytics and speed up your data preparation process.
Open-Source vs. Proprietary Solutions
Dataset Merging Techniques
Documentation is important in data set merging. Detailed records of data sources, formats, and transformation steps help to troubleshoot problems.
Regular monitoring of merged data sets reduces duplicate entries. Automated tools reduce manual processing time.
Collaborative teams of annotators increase data accuracy and reduce the frequency of errors or inconsistencies in data sets, saving time spent processing poor-quality data.
These practices increase the completeness of data sets by effectively merging different data sources.
Future Trends in Dataset Fusion
Machine learning is changing the dataset fusion process. It increases the accuracy of AI models merging with complete data sets.
Development of new techniques such as basis set selection and data set condensation. These aim to reduce computational costs without compromising the accuracy of the merged AI models.
The expansion and complexity of data sets create ethical dilemmas. Privacy, data ownership, and the risk of market manipulation are major obstacles. There is a growing need for regulatory frameworks similar to antitrust laws to prevent the dominance of valuable data assets. The benefits of data consolidation mustn't overshadow personal privacy and competition in the market.
Big data is changing fusion strategies. Integrating additional data sets through horizontal integration improves data quality and AI performance. This trend toward data-driven convergence will continue, and harnessing it will provide significant benefits in predicting market trends and customer preferences.
FAQ
What is Dataset Fusion, and why is it important?
Dataset fusion is the process of combining information from different sources to create a single, consistent set.
How is data integration different from data fusion?
Data integration is the process of combining and harmonizing information from different sources to obtain a single view.
What are the main challenges in merging labeled datasets?
It is important to maintain label consistency, handle conflicting annotations, work with different data formats, and standardize different data structures.
What preprocessing techniques are required before merging datasets?
The main techniques are data cleaning and normalization, scaling functions, handling overlapping data, reconciling date formats, and using different units of measurement.
What are the main types of join operations when merging a dataset?
The main types include inner join, outer join, left join, and right join.
What quality assurance measures should be taken after merging datasets?
After merging, verify accuracy, data validity, and data integrity. Then, evaluate the consistency of the dataset using metrics and tools.
What are the benefits of using automated tools to merge datasets?
Automated tools simplify the merging process, reduce errors, and quickly process large amounts of data.
What are the ethical considerations when merging datasets?
Ensuring data privacy and security. Be aware of biases and use merged datasets with sensitive information responsibly.
