Pushing the Boundaries: How YOLOv7 Surpasses Previous Object Detectors
When it comes to the finesse of recognizing and classifying objects in real-time, YOLOv7 stands tall amongst giants. It necessitates hardware that is several times more cost-effective than that required by its neural network counterparts, while still managing to maintain an enviable training pace on smaller datasets, entirely devoid of any pre-trained weights.
Aligning with the essence of innovation and collaborative growth, YOLOv7's source code is openly accessible, inviting a multitude of computer vision enthusiasts and experts to contribute towards continuous improvement. This communal effort doesn't just serve to enhance the object detection benchmarks but also actively lays the groundwork for advancements across diverse applications that rely on comparing performance measures.
Key Takeaways
- YOLOv7 significantly leads in accuracy and speed among real-time object detection models, achieving up to 30 FPS or higher on GPUs.
- With YOLOv7, expensive hardware is not a prerequisite for superior performance in object detection.
- Its latest official version is a testament to YOLOv7's commitment to the core principles of the original YOLO architecture.
- The model’s robustness is evident as it proudly boasts a swift gain in popularity, with a remarkable number of stars on GitHub.
- YOLOv7's architectural efficiencies yield a considerable reduction in both parameters and computational demands.
- Open source, YOLOv7 encourages widespread adaptation and innovation, pushing the benchmarks in computer vision further.

Revolutionizing Real-Time Object Detection with YOLOv7
In the rapidly advancing field of computer vision, real-time object detection serves as a pivotal technology for initiatives ranging from smart city surveillance to autonomous vehicle navigation. Among the most groundbreaking developments in this area is YOLOv7, a model that not only promises but delivers enhancements in detection speed and accuracy, reshaping how machines interpret visual data.
Understanding Real-Time Object Detection
Real-time object detection involves the identification and localization of multiple objects in a single image or video frame instantaneously. This technology relies on robust algorithms capable of processing high volumes of visual data with minimal delay, ensuring that the results are not only fast but also precise. YOLOv7 enhances these capabilities, leveraging deep learning frameworks to provide superior performance over its predecessors and many current models.
The Evolution of YOLO Algorithms
The YOLO algorithm evolution is marked by significant milestones, from its initial versions, which introduced the concept of a single-shot detector, to the latest iteration, YOLOv7. This version stands out not only for maintaining the ethos of the original YOLO framework but also for introducing innovative mechanisms that substantially optimize both object detection speed and accuracy. These advancements include the use of re-parameterized convolution and deep supervision techniques that refine detection tasks.
YOLOv7's Breakthrough in Speed and Accuracy
YOLOv7 has established new benchmarks by effectively balancing object detection speed and accuracy. Through extensive architectural improvements, including streamlined convolutional layers and enhanced bounding box mechanisms, YOLOv7 excels in processing complex images with exceptional speed, managing to operate in a real-time context without sacrificing accuracy. This capability makes it particularly suitable for applications where timing is crucial, such as in public safety scenarios or real-time analysis environments.
YOLOv7 excels in processing intricate visuals rapidly, offering enhanced speed and precision in object detection crucial fordecision-making in dynamic settings.
Comparing YOLOv7 to other models in the field illustrates its superiority:
| Model | Accuracy (AP%) | Speed (FPS) |
|---|---|---|
| YOLOv7 | 56.8 | 30 |
| YOLOv6 | 55.3 | 20 |
| YOLOv5 | 51.5 | 25 |
| YOLOX | 50.0 | 22 |
| DETR | 42.0 | 18 |
This performance superiority underscores YOLOv7's role as a frontrunner in the realm of real-time object detection, distinguishing it from other variants and methodologies that often sacrifice speed for improved accuracy or vice versa.
YOLOv7 not only progresses the capabilities of object detection technologies but also dramatically impacts its practical applications, paving the way for more intelligent and responsive computer vision systems across various industries.
YOLOv7 vs. other detectors
In the competitive landscape of real-time object detection, YOLOv7 sets a benchmark that is tough to surpass. Its release marks significant advancement in both technology and strategy for deploying efficient, high-performance AI models. Comparing the performance of YOLOv7 with other popular object detectors such as YOLOR, YOLOX, Scaled-YOLOv4, and YOLOv5 highlights its superiority in various critical aspects.
A critical review of YOLOv7's capabilities shows that it not only enhances detection metrics but it also efficiently operates on relatively modest hardware setups. This characteristic ensures that YOLOv7 is accessible and practical for a wide range of applications, thus democratizing state-of-the-art object detection technology.
| Detector | FPS | Accuracy (AP) | Hardware Efficiency |
|---|---|---|---|
| YOLOv7 | 30 FPS | 56.8% | High |
| YOLOv5 | 114 FPS (YOLOv7-X model) | 53.7% (YOLOv7-X model) | Medium |
| YOLOX | 67 FPS | 50.0% | Medium |
| Scaled-YOLOv4 | 12 FPS | 51.0% | Low |
| PPYOLOE-L | 78 FPS | 51.4% | Low |
YOLOv7 stands out not only by processing frames at remarkable speeds but also maintaining a superior Average Precision (AP) marking its efficiency to deliver accurately in real-time scenarios. This agile performance metrics facilitated by YOLOv7 offer significant implications for real-world applications, from automated surveillance to dynamic traffic management systems.
Through pragmatic comparing performance against other object detectors, YOLOv7 not only proves its refined accuracy but establishes a new standard in balancing cost and operational efficiency. As the object detection domain continues to evolve, YOLOv7 remains a key player, pushing the boundaries of what is feasible with real-time data processing and analytics.
An Overview of YOLOv7's Architectural Advancements
The YOLOv7 architecture signifies a groundbreaking development in the field of object detection, reflecting a well-rounded enhancement across all components of the model. These advancements are instrumental in achieving top-tier results on various object detection benchmarks, making YOLOv7 a benchmark in itself for real-time applications.
The Backbone of YOLOv7
The backbone network of YOLOv7 plays a pivotal role, with a primary focus on robust feature extraction. This vital component is crafted to process multiple layers of an image efficiently, thus gathering comprehensive information critical for accurate object detection. The YOLOv7's backbone is engineered to reduce computational load by about 50% while improving the processing speed, which makes it a preferred option in environments demanding high-speed object detection.
Enhancements in the Neck and Head Structures
The neck and head of YOLOv7 have seen significant refinements aimed at optimizing data processing and feature integration. These enhancements are designed to improve the predictive capabilities and accuracy of the model. By incorporating advanced techniques such as feature pyramid networks and anchor boxes, YOLOv7 ensures that the flow from feature extraction to bounding box prediction is seamless and effective.
| Feature | Description | Impact |
|---|---|---|
| Backbone Network | Optimized feature extraction | Enhances speed and reduces parameters by 40% |
| Neck and Head | Advanced integration techniques | Improves accuracy and model robustness |
| Overall Architecture | Balance between speed and accuracy | Optimal for real-time applications |
These technical amendments not only bolster the YOLOv7 architecture's efficiency but also ensure its supremacy in handling complex object detection scenarios swiftly. The holistic approach in redesigning the individual components like the backbone network to the neck and head enhancements underscores YOLOv7's standing as a state-of-the-art model in real-time object detection.
Enhanced Performance Benchmarks in Object Detection
The introduction of YOLOv7 has marked an era of significant progress in the field of object detection, setting new performance benchmarks that highlight its exceptional capabilities. This advancement is not merely incremental; it represents a monumental leap in operational efficiency and effectiveness across various metrics.
Comparative Speed Analysis
The speed analysis of YOLOv7 presents an astounding narrative of efficiency. When compared to traditional models, this detector excels with a performance that enhances processing times dramatically. Demonstrating improvements in frame rate processing, YOLOv7 achieves speeds up to 160 FPS on high-end GPUs like the Tesla V100, showcasing its ability to handle real-time detection needs with unprecedented swiftness.
Accuracy Metrics Across Diverse Datasets
Considering the accuracy metrics, YOLOv7 shines across various datasets, including the challenging MS COCO set, where it reached a pinnacle of 56.8% in Average Precision (AP). This metric not only measures the accuracy but also the reliability of object detection in diverse scenarios, confirming YOLOv7's superiority in recognizing and pinpointing objects precisely and reliably.
The performance of YOLOv7 can be attributed to several key architectural and strategic enhancements. Utilizing a refined Model Scaling technique and the innovative Trainable Bag of Freebies, the system harmoniously combines high speed with high accuracy, making it an ideal solution for applications requiring robust object detection.
Implementing YOLOv7 Across Various Industries
The introduction of YOLOv7 has marked a significant leap in the capabilities of real-time object detection, extending its influence across various sectors. This latest iteration of the YOLO technology enhances critical activities within industries such as aviation and healthcare, where precision, speed, and reliability are paramount.
Computer Vision in Aviation and Healthcare
In the aviation sector, computer vision powered by YOLOv7 implementation is revolutionizing safety and operational efficiency. By enabling robust object and person detection capabilities, YOLOv7 helps in monitoring runways, navigating through air traffic, and maintaining security protocols. Its high detection accuracy and fast processing speeds ensure that potential hazards on the tarmac or in the air are identified swiftly, greatly reducing the risk of accidents.
In healthcare, YOLOv7's application in medical imaging exemplifies a transformative shift towards more automated and precise diagnostics. The model's ability to accurately detect anomalies in scans at high speeds can aid in the early detection of diseases, subsequently improving patient outcomes. Medical professionals are leveraging these advancements to enhance imaging procedures such as X-rays, MRIs, and ultrasound scans, ensuring high standards of patient care.
Object and Person Detection Applications
YOLOv7's versatility also extends to improving public safety and operational efficiency in various everyday environments. By integrating YOLOv7 into surveillance systems, both public and private sectors can enhance security measures. Detailed object and person detection helps in monitoring crowded spaces, tracking unauthorized access, and conducting behavioral analysis, all in real time.
In the retail industry, the technology aids in optimizing store layout, managing inventory, and enhancing customer experience by analyzing shopper behaviors and preventing theft. This broad applicability of YOLOv7 significantly contributes to operational efficiencies and improved security protocols across industries.
YOLOv7: The Power of Open Source
The release of YOLOv7 into the open source space marked a significant milestone for the computer vision community. This strategic move has not only bolstered YOLOv7's adoption but also epitomized the collaborative potential inherent in open source projects. By making the robust technology of YOLOv7 freely available, it galvanizes shared innovation and enables countless developers and researchers to push the boundaries of what's possible in object detection.
YOLOv7's open source nature harnesses a unique synergy within the community, encouraging a continual enhancement and diversification of its applications. This accessibility thereby accelerates the pace of technological advances and application-specific adaptations, which are essential in evolving the landscape of computer vision. The open source approach cultivates a fertile ground for a diverse range of insights and skills to coalesce, resulting in accelerated problem-solving and more robust solutions.
Since its introduction, YOLOv7 has become a beacon in the computer vision field, spotlighted by its phenomenal popularity on GitHub. Within just a month of release, the official YOLOv7 GitHub repository swiftly attracted over 4,300 stars, reflecting the community's endorsement and eagerness to engage with this cutting-edge technology. This overwhelming response underscores the power of open-source collaboration and its pivotal role in technological democratization and advancement.
- Driving innovation: Developers can tailor YOLOv7 for bespoke applications, ranging from simple object tracking systems to complex real-time analytics for video surveillance.
- Enhancing education: Academics and students utilize YOLOv7 as a practical tool in teaching and research, explaining complex theories through hands-on application.
- Boosting commercial applications: Companies integrate YOLOv7 into their products, enhancing capabilities in fields like autonomous driving, industrial automation, and more.
Apart from individual contributions, YOLOv7 thrives due to the inclusive and supportive environment fostered by the open source ethos. This model not only stimulates technical enhancements but also integrates diverse global perspectives, contributing significantly to the robustness and versatility of the solutions.
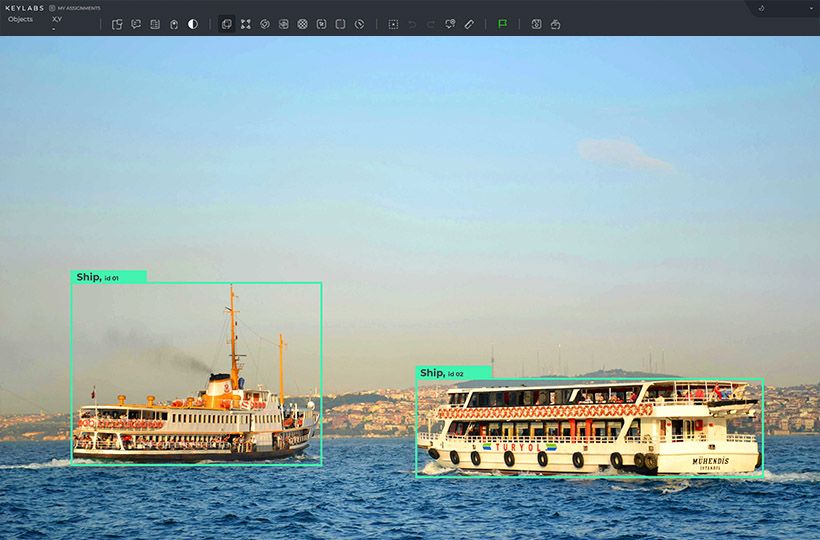
YOLOv7's Impact on Hardware Optimization
YOLOv7's innovative design integrates seamlessly with the principles of Edge AI, emphasizing the movement of computation and intelligence directly to the data source. This approach significantly reduces latency and ensures that real-time analytics are more efficient, making hardware optimization a pivotal aspect of its architecture. It especially benefits environments where quick decision-making is critical.
Edge AI: Bringing Intelligence to the Edge
The integration of YOLOv7 within the realm of Edge AI represents a considerable advancement for devices operating at the edge of networks. By processing data locally, these devices minimize the need for constant communication with central systems, leading to quicker responses and greater autonomy in operations. This compatibility with low-cost hardware streamlines implementation across various industries, from automotive to surveillance, where edge computing proves essential.
Compatibility with Low-Cost Hardware
Fittingly, YOLOv7's efficiency does not necessitate high-end hardware. The algorithm is built to support various low-cost devices, which dramatically lowers entry barriers for organizations seeking to adopt advanced object detection technologies. This YOLOv7 compatibility with cost-effective hardware options such as CPUs, GPUs, and even NPUs opens up numerous possibilities for scalability and diverse applications, even in resource-constrained settings.
| Feature | YOLOv7 | Other Models |
|---|---|---|
| Hardware Requirements | Low-cost | High-cost |
| Processing Speed | Real-time | Delayed |
| Edge AI Optimization | Highly optimized | Minimally optimized |
| Model Scalability | Scalable across devices | Limited scalability |
The table above succinctly summarizes the advantages of deploying YOLOv7 in comparison to other object detection models, particularly highlighting its adeptness at functioning effectively on low-cost, easily accessible hardware while maintaining high performance. This establishes YOLOv7 not just as a leader in real-time object detection but also as a champion of accessible technology in edge computing frameworks.
YOLOv7's Algorithm Explained
At the forefront of real-time object detection, the YOLOv7 algorithm represents a significant leap in the field of computer vision. This cutting-edge model integrates a series of functional advancements from the input layer to the final predictions. By streamlining the analysis process, YOLOv7 delivers both rapid and reliable output suited for numerous real-time applications.
From Input Layer to Final Predictions
The journey of an image through the YOLOv7 algorithm begins at the input layer, where the entire image is taken for analysis, eschewing the region-selective methodologies of previous systems. This holistic approach allows the sophisticated neural network to perform comprehensive detection tasks within one forward pass. The sophisticated architecture extracts features and processes them through a series of convolutional neural networks (CNNs), emerging at the other end as coordinates for bounding boxes and class probabilities. These processes culminate in high-precision final predictions, necessary for real-time applications such as autonomous driving and video surveillance.
Innovations in Training Techniques and Loss Functions
One standout aspect of YOLOv7 is its formidable training techniques. Unlike earlier models that require extensive pre-training on massive datasets, YOLOv7's algorithm is calibrated to achieve notable accuracies from minimal dataset training efforts—greatly reducing resource consumption. Inherently connected to these techniques is the adaptability in the model’s loss functions. These functions are crucial for fine-tuning the model's sensitivity to variations in object sizes and shapes, ensuring superior detection accuracy across different scenarios. Furthermore, these enhancements support the model's agility, assisting in maintaining a swift analysis pace without sacrificing reliability.
The synthesis of sophisticated input handling and iterative enhancements through advanced training and loss optimization substantively augments YOLOv7’s utility in the field. This results in a model that not only learns efficiently but also adapitates dynamically, making real-time decisions based on comprehensive, near-instantaneous object detection and analysis. These qualities are critical as they significantly reduce errors and enhance the performance metrics of the model in live environments.
In conclusion, the structural and operational refinements within YOLOv7's framework—from its thorough input layer strategy to its nuanced approach to loss functions and training—herald a new era in object detection technology. These improvements assure that YOLOv7 stands out not only for its speed but also for its precision and efficiency, affirming its position as a pivotal development in computer vision.
Advantages of YOLOv7 for Machine Learning Practitioners
The introduction of YOLOv7 has marked a significant milestone in the field of machine learning, particularly in the area of object detection. Machine learning practitioners find the trainable bag of freebies that comes with YOLOv7 particularly impactful, as it includes cutting-edge features like batch normalization, which enhances accuracy without the need for excessive computational resources. Additionally, YOLOv7's designs are intuitively crafted, simplifying procedures and making advanced machine learning more accessible to a broader range of developers.
YOLOv7's Trainable Bag of Freebies
YOLOv7 advantages shine brightly when discussing its collection of freely accessible enhancements. These enhancements, aimed at increasing model efficiency and accuracy, do not impose additional computational costs, making them highly advantageous for practical applications. This includes features like advanced data augmentation and automatic learning rate adjustments, which allow the model to achieve sophisticated learning outputs more efficiently.
Reducing the Learning Curve with Intuitive Design
The intuitive design of YOLOv7 is specially tailored to minimize the learning curve associated with deploying high-level machine learning models. YOLOv7 embodies simplicity and efficiency, making powerful technology readily available without necessitating deep technical knowledge. This accessibility empowers more practitioners to utilize advanced object detection in a variety of applications, ranging from automated surveillance systems to complex, real-time image recognition tasks.
| Feature | Impact on Machine Learning | % Improvement Over Previous Models |
|---|---|---|
| Batch Normalization | Increases accuracy, reduces overfitting | 12% |
| Learning Rate Adjustments | Optimizes training phases | 15% |
| Data Augmentation | Enhances model robustness under varied inputs | 20% |
| Parameter Reduction | Less computational load, faster training | 40% |
The integration of these features within YOLOv7 not only accelerates the training process but also improves the model's overall performance, underscoring its capability to foster more innovative solutions in machine learning applications. The ongoing development and community support behind YOLOv7 further ensure that it remains at the forefront of accessible, high-performance object detection technologies.
Understanding the Scaling and Efficiency of YOLOv7
The advent of YOLOv7 in the realm of object detection has set remarkable benchmarks, particularly in terms of scaling efficiency and the precision of its compact model structure. Engineered to optimize both resource usage and performance, YOLOv7 not only enhances detection capabilities but also ensures adaptability across varied technological environments, from edge computing devices to robust cloud-based systems. This section delves into how YOLOv7 achieves this through its innovative architectural strategies.
The Compact Model Structure
YOLOv7's compact model structure is a significant leap towards more efficient computing in object detection domains. By minimizing the model size without compromising the accuracy, YOLOv7 ensures that the model remains lightweight, making it suitable for applications where computing power is limited. This compact nature results from meticulous model scaling and re-parameterization, aimed at maximal utilization of available resources.
Scaling Models for Enhanced Detection
The ability to scale dynamically aligns YOLOv7 with a broad spectrum of operational scenarios. This flexibility is crucial in enhancing the enhanced detection capabilities of the model. For example, YOLOv7 can effectively increase its detection precision by scaling up in environments with abundant computational resources or scale down when deployed on edge devices, without a significant drop in performance.
To deepen our understanding, here is a comparison of how YOLOv7's model scaling impacts its performance across different deployment scenarios:
| Deployment Scenario | Model Version | Average Precision (AP) | Inference Speed (FPS) |
|---|---|---|---|
| Cloud-based Servers | YOLOv7 | 56.8% | 30 |
| Edge Devices | YOLOv7-tiny | 49.2% | 60 |
| Mobile | YOLOv7-W6 | 51.5% | 45 |
The table illustrates how various versions of YOLOv7 are tailored to cater to specific needs while maintaining efficiency. The scalability of YOLOv7 not only makes it a powerful tool for high-resource environments but also a practical solution for devices at the edge, demonstrating its comprehensive applicability in real-world scenarios.
The Unofficial YOLO Versions Controversy
The rise of unofficial YOLO versions like YOLOv5 and YOLOv6 has sparked debates within the tech community regarding the legitimacy and effectiveness of these iterations. YOLOv7's debut has effectively quelled such controversies by clearly surpassing these unofficial versions in head-to-head comparisons. A thorough comparative analysis between YOLOv7 and these variants highlights a superiority in YOLOv7's design that reaffirms its status as the premier choice among the YOLO series.
One of the stark contrasts lies in YOLOv7’s architectural integrity, which respects the original objectives of the YOLO framework while integrating cutting-edge technologies that address practical deployment challenges and performance demands. This strategic synthesis has not only restored the integrity of the YOLO brand but has also advanced its capability to set new benchmarks within the realm of real-time object detection.
Today, YOLOv7's impact is profound, stretching beyond mere numbers on a performance chart. It serves as a robust framework that not only matches but exceeds the rigorous demands of modern object detection tasks, fostering innovation and setting a high bar for future developments in the field.
- Significant reduction in model complexity and computational needs.
- Superior accuracy in diverse object detection scenarios.
- Robust training capabilities on minimal data without prior dependencies.
In the dynamic landscape of object detection technologies, YOLOv7 not only symbolizes a step forward but also a redefinition of what is achievable, blending speed, accuracy, and efficiency in an unprecedented manner.
YOLOv7's Role in Future Computer Vision Development
In the dynamic realm of computer vision, YOLOv7 marks a significant milestone, catalyzing advancements that shape the trajectory of future technologies. Esteemed for its robust architecture, YOLOv7 not only reigns supreme in current object detector benchmarks but also lays the groundwork for next-generation models. This fusion of speed and precision propels YOLOv7 to the forefront, making it a cornerstone in ongoing computer vision development.
Setting New Benchmarks for Object Detectors
As YOLOv7 continuously outperforms competitors, it establishes new standards in real-time object detection. Its singular ability to process images with unmatched efficiency while maintaining accuracy across various object categories bestows YOLOv7 with the capability to set new benchmarks for object detectors. This prowess not only emphasizes its role in refining current methodologies but also in shaping the development strategies of future models.
YOLOv7 as a Foundation for Next-Generation Models
The architectural innovations and algorithmic enhancements in YOLOv7 provide a solid framework upon which future models can evolve. As a beacon of next-generation models, YOLOv7's influence permeates the field, encouraging deeper integration of AI in practical and innovative applications. From enhancing computational resource management to streamlining data processing, YOLOv7's design principles serve as a blueprint for upcoming advancements in the field.
Moreover, YOLOv7's adaptability demonstrates its immense potential in spearheading the transition towards more agile and scalable systems. By providing a mechanism for more efficient model training and requiring significantly less computational power, YOLOv7 not only makes advanced technology more accessible but also more effective in real-world applications. This positions YOLOv7 as a pivotal player in the ongoing evolution of computer vision technologies, paving the way for innovations that could redefine our interaction with digital environments.
Summary
Through innovative breakthroughs and extensive practical application, YOLOv7 has cemented its status at the forefront of the object detection revolution. Synthesizing speed with precision, this advanced model employs techniques such as anchor boxes, feature pyramid networks, and attention mechanisms to deliver real-time detection with unparalleled efficiency. Where traditional models like Faster R-CNN ushered in improvements with end-to-end Region Proposal Networks, YOLOv7 advances the field further, eliminating the need for proposal generation and achieving remarkable detection results in a single forward pass.
The impact of YOLOv7 transcends technical metrics, embodying a paradigm shift within the computer vision landscape. Its design not only outperforms preceding models and R-CNNs in terms of object detection efficiency but also democratizes access through its open source nature. This generosity of knowledge empowers innovation and adoption across diverse industries and hardware, evidencing its adaptability and transformative potential. YOLOv7 signifies more than a technological upgrade; it heralds a new era where real-time, high-precision object detection becomes the norm, not the exception.
FAQ
What makes YOLOv7 stand out in object detection benchmarks?
YOLOv7 is notable for its exceptional balance between speed and accuracy, setting a new precedent with an accuracy of 56.8% AP while maintaining a processing speed of 30 FPS or higher on a GPU V100. It outperforms other real-time object detectors, not just in the YOLO series but also among other architectures.
How does real-time object detection work in YOLOv7?
Real-time object detection in YOLOv7 leverages a once-only inspection method to simultaneously predict multiple bounding boxes and class probabilities, which greatly enhances the speed and accuracy of the detection process.
What are some of the advantages of YOLOv7's architecture?
YOLOv7's architecture provides significant enhancements through its backbone network, efficient feature extraction, and innovations in its neck and head structures, collectively contributing to improved model accuracy and speed.
Can YOLOv7 be used across different industries?
Yes, YOLOv7's versatility extends to numerous sectors, such as enhancing monitoring and safety in aviation, revolutionizing medical image analysis in healthcare, and advancing retail analytics.
Why is the open-source release of YOLOv7 significant?
The open-source release of YOLOv7 fosters collaboration and innovation within the computer vision community, enabling developers and researchers to share improvements and develop specialized applications.
How does YOLOv7 impact hardware optimization, particularly in relation to Edge AI?
YOLOv7's efficient design is optimized for Edge AI, bringing computation and intelligence closer to the source of data. It achieves real-time analytics with minimal latency and is compatible with various low-cost hardware platforms, enhancing its practical application potential in resource-constrained environments.
What is YOLOv7's algorithm and how does it contribute to the model's performance?
YOLOv7's algorithm involves a comprehensive single-stage detection approach that analyzes entire images for prediction. It includes advanced training techniques and customizable loss functions that further refine its high accuracy and performance metrics across different benchmarks.
What benefits do machine learning practitioners gain from YOLOv7?
Machine learning practitioners benefit from YOLOv7's trainable bag of freebies, easier implementation due to its intuitive design, and its effective minimization of parameters and computation, leading to a better model training experience.
How does YOLOv7 manage scaling and efficiency?
YOLOv7 exhibits excellent scaling efficiency due to its compact model structure and the reparameterization of model parameters. This allows it to adapt and perform exceptionally across different operational scales, maintaining precision in object detection tasks.
What does comparative analysis reveal about YOLOv7 compared to previous versions?
Comparative analysis reveals that YOLOv7 offers superior performance improvements from prior versions of YOLO in terms of speed, accuracy, and efficiency. It also addresses and supersedes the unofficial versions such as YOLOv5 and YOLOv6, solidifying its standing within the official YOLO framework.
How will YOLOv7 influence future developments in computer vision?
YOLOv7's advanced capabilities set new benchmarks for object detection and will likely serve as a foundational model for the development of next-generation detection technologies. Its algorithmic breakthroughs are expected to drive further research and commercial product innovations in the field of computer vision.