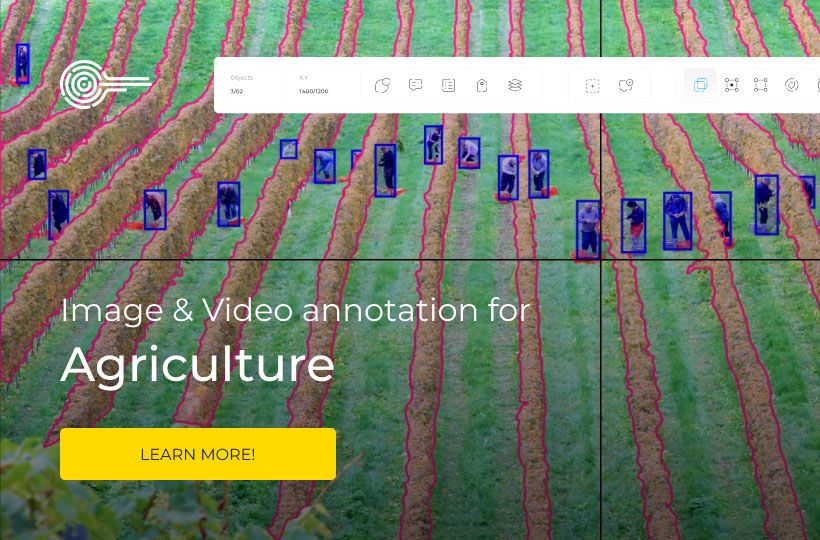
Scaling annotation operations for large datasets
In modern AI model development, there is a simple but fundamental rule: the more examples, the better the model performs. The quality of training directly depends on the amount of data, and for it to be usable, accurate, and scalable, annotation is required. Therefore, companies working with large datasets face the problem of efficient data preparation. Traditional approaches, over time, often prove to be too slow or expensive, and therefore, they are replaced by scaling operations and the use of annotation automation.
This includes workflow optimization, resource scaling, and developing a strategy that allows you to ensure stable quality even in cases of mass annotation. The new enterprise annotation standard focuses on flexibility, controllability, and guaranteed results at scales where manual work is no longer feasible.

Impact on AI innovation and training data quality
The growing demand for high-volume data labeling
The development of modern models, primarily transformers and multimodal systems, directly depends on the volumes of data they consume. With increasing demands for accuracy and versatility, there is a need for high-volume data labeling. What factors exist:
- Model complexity. As architectures become increasingly complex, the number of examples required also increases. Without scalable approaches to labeling, even large companies risk falling behind.
- Scaling operations. The need to process millions of examples forces the implementation of new annotation automation tools and workflow optimization systems to ensure process consistency.
- Enterprise annotation. Enterprise-level organizations are building resource scaling strategies that allow them to simultaneously support large teams, automated pipelines, and quality checks.
- Mass annotation. The key difference between the modern approach is the ability to ensure not only quantity but also consistent quality during mass labeling, thereby preserving the value of the data for training models.
Key challenges in large-scale data annotation
For many companies, the primary challenge is striking a balance between speed and quality of work. Mass annotation often sacrifices accuracy for volume; however, low-quality data directly affects model performance. Therefore, it is essential to implement workflow optimization strategies that enable scaling processes without compromising accuracy.
Another challenge is related to team management. When scaling annotation, dozens or hundreds of annotation teams must work in harmony. This requires standardized instructions, clear performance evaluation systems, and effective quality control.
A separate problem remains the barriers in workflows. The use of annotation automation solutions and a well-designed pipeline architecture helps eliminate these limitations, ensuring the stability of the process even with large volumes of data.
Optimizing annotation workflows for efficiency
The efficiency of data annotation directly affects the speed of model development and the quality of results. When working with large datasets, it is essential to optimize the entire process from start to finish. This workflow optimization helps reduce the time spent on repetitive tasks, minimize the likelihood of errors, and make the process more predictable.
One key approach is the implementation of annotation automation tools. Automating routine tasks, such as pre-labeling or checking simple categories, enables annotators to focus on complex cases, thereby improving both the quality and speed of their work.
Structured team management is also essential. Clear instructions, standardized templates, and regular checkpoints help coordinate large groups of people and ensure the stability of results when scaling. Systems for monitoring performance and quality assurance enable efficient resource allocation and facilitate real-time scaling of resources.
Workflow optimization also involves integrating different tools and platforms into a single pipeline. This reduces the time required for data transfer between stages, simplifies quality control, and enables enterprise annotation at the level of large data volumes.
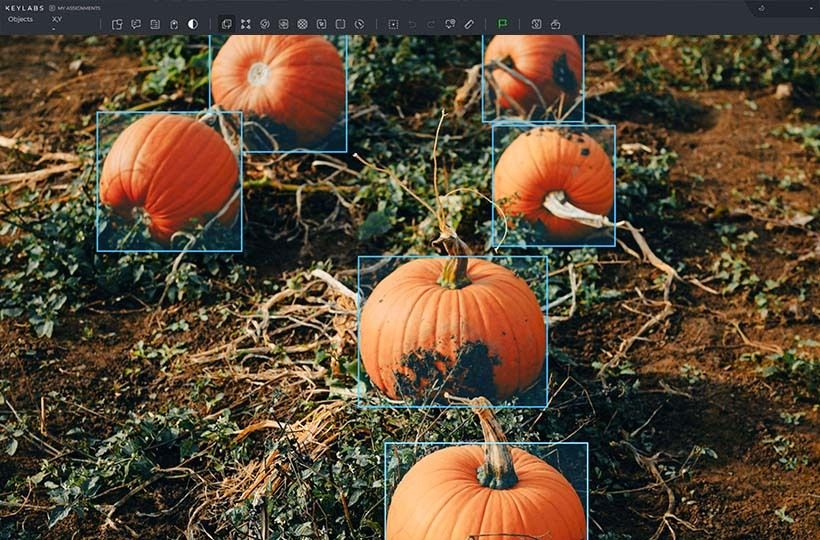
Streamlining repetitive tasks through automation
In the process of large-scale data annotation, many tasks are repeated multiple times, and performing such routine operations manually is not only time-consuming but also increases the risk of errors, especially when working with large datasets.
Automation allows you to pre-process simple or predictable categories, pre-label data, and perform basic quality checks. This significantly reduces the workload on annotators, allowing them to focus on more complex tasks that require expertise and contextual understanding.
Automation integrates with workflow optimization, ensuring a continuous annotation pipeline. Repeatable processes occur quickly and consistently, allowing for efficient resource scaling and enterprise annotation, even with millions of examples. This approach also simplifies quality control, as automated checks immediately detect anomalies or missing data, and humans can quickly intervene where additional attention is required.
Effective annotation team management and training
Even with modern annotation automation tools, the role of annotators in the annotation process remains central. Scaling data annotation requires well-organized teams, clear guidelines, and systematic training to ensure consistent quality at the enterprise annotation level.
Firstly, standardization of processes is essential. All team members should have a single guideline with examples to maintain consistency in annotation. Clear standards help avoid errors and reduce the time for additional checks.
Training and regular professional development of annotators also play a key role. Due to constant changes in models and datasets, new categories and scenarios arise that require an expert approach. Systematic training and knowledge checks allow teams to quickly adapt to new requirements and maintain a high level of accuracy.
To effectively manage large teams, a transparent performance evaluation and feedback system is required. This helps to identify bottlenecks promptly, adjust the workload, and implement resource scaling without compromising quality.
Summary
Successful scaling operations enable companies to work faster, more accurately, and more consistently. A modern approach to enterprise annotation combines the automation of routine tasks with thoughtful team management and workflow optimization. This creates a flexible system that can adapt while maintaining consistent data quality.
With automation, quality control, and team training integrated into a single pipeline, companies can scale mass annotation without losing accuracy and quickly respond to the needs of modern models.
FAQ
Why is scaling annotation operations critical for AI development?
Scaling annotation operations enables organizations to handle large datasets efficiently, directly improving model performance. Without scalable processes, collecting and preparing enough high-quality training data becomes slow and costly.
What role does workflow optimization play in data annotation?
Workflow optimization streamlines repetitive tasks, reduces errors, and ensures consistent quality across teams. It allows organizations to scale annotation without sacrificing accuracy.
How does automation improve annotation efficiency?
Automation handles repetitive or predictable tasks, such as pre-labeling or basic quality checks. This frees up human annotators to focus on complex cases, increasing both speed and precision.
What challenges arise when balancing quality and quantity in large-scale annotation?
High-volume annotation can pressure teams to prioritize quantity over quality. Without careful monitoring and structured processes, low-quality data can harm model training and reduce overall effectiveness.
Why is team management critical in enterprise annotation?
Large annotation projects require coordination across multiple teams. Clear instructions, standardized templates, and continuous training ensure consistency and maintain high-quality results.
What are common workflow barriers in large-scale annotation?
Manual processes and fragmented tools often create bottlenecks, slow down progress, and increase the likelihood of errors. Integrated pipelines and automation are crucial for overcoming these obstacles.
How does mass annotation differ from small-scale labeling?
Mass annotation focuses on processing millions of examples quickly while maintaining consistent quality. It requires scalable infrastructure, automated tools, and effective resource management.
What is the impact of high-volume annotation on AI innovation?
Access to large, high-quality datasets accelerates experimentation and model development. It enables researchers to test more hypotheses and implement new architectures more rapidly.
How does enterprise annotation create competitive advantages for organizations?
By combining automation, structured workflows, and skilled teams, enterprise annotation allows organizations to scale efficiently. This leads to the faster deployment of AI solutions and the development of higher-quality models, providing a strategic edge in innovation.
Why is training and continuous education necessary for annotation teams?
Data categories and models evolve constantly, requiring annotators to adapt. Regular training ensures that teams maintain accuracy and can effectively handle new, complex scenarios.