Semantic Segmentation vs Object Detection: A Comparison
Semantic segmentation and object detection are two important techniques in the field of computer vision and machine learning, both playing a crucial role in advanced image analysis. In this article, we will compare and contrast these techniques to understand their definitions, techniques used, and real-world applications.

Semantic segmentation involves dividing an image or video into meaningful regions to identify and differentiate objects or regions of interest. It provides fine-grained information about object boundaries and assigns class labels to each pixel. On the other hand, object detection aims to localize and classify objects within an image or video. It identifies specific objects and provides their bounding boxes.
Both techniques have different applications and strengths. Semantic segmentation is ideal for tasks that require understanding object boundaries and extracting detailed information. It finds applications in medical image analysis and manufacturing defect detection. Object detection, on the other hand, is best suited for tasks that involve identifying specific objects and their locations. It is commonly used in video surveillance and agriculture for crop monitoring.
Both semantic segmentation and object detection rely on machine learning algorithms, particularly deep learning approaches like Convolutional Neural Networks (CNNs), to achieve accurate results. These techniques have revolutionized the field of computer vision and image analysis.
Key Takeaways:
- Semantic segmentation and object detection are two important techniques in computer vision and machine learning.
- Semantic segmentation divides an image or video into meaningful regions, while object detection localizes and classifies objects.
- Semantic segmentation excels in understanding object boundaries, while object detection is ideal for identifying specific objects and their locations.
- Both techniques use machine learning algorithms, particularly deep learning approaches like CNNs.
- Applications of semantic segmentation include medical image analysis and manufacturing defect detection, while object detection is commonly used in video surveillance and agriculture.
Understanding Segmentation
Segmentation is a fundamental process in computer vision that involves dividing an image or video into meaningful regions. By doing so, segmentation allows us to identify and differentiate objects or regions of interest within an image or video. This technique is crucial for extracting fine-grained information and understanding object boundaries.
There are different types of segmentation techniques that can be utilized based on specific needs. One popular approach is semantic segmentation, which assigns class labels to each pixel, allowing for a detailed understanding of the image. Another technique is instance segmentation, which goes beyond semantic segmentation by identifying individual instances of objects.
Segmentation has a wide range of applications across various fields. In medical image analysis, segmentation is essential for identifying organs, tumors, or anomalies. In manufacturing, segmentation plays a pivotal role in detecting defects or irregularities. Additionally, segmentation is widely used in robotics for object recognition and manipulation.
By accurately segmenting an image or video, we can gain valuable insights into the composition and structure of the scene. This segmentation process enables us to extract fine-grained information, identify object boundaries, and ultimately facilitate further analysis and decision-making.
Exploring Object Detection
Object detection plays a crucial role in computer vision by localizing and classifying objects within images or videos. It focuses on identifying specific objects of interest and providing their bounding boxes.
Object detection is used in various applications, including:
- Video surveillance: By detecting and tracking objects, object detection enhances security and enables real-time monitoring.
- Agriculture: Object detection helps in crop monitoring by identifying and tracking plants, pests, or diseases.
- Retail analytics: Object detection enables the analysis of customer behavior and patterns in stores, improving marketing strategies and product placement.
There are different algorithms and techniques for object detection, each with its own trade-offs in terms of speed and accuracy. Some popular approaches include:
- Haar cascade classifiers: These classifiers utilize features like edges and texture to detect objects.
- YOLO (You Only Look Once): YOLO is known for its real-time object detection capabilities.
- Faster R-CNN (Region-based Convolutional Neural Networks): This approach combines deep learning and region proposal mechanisms for accurate object detection.
By leveraging object detection, industries can benefit from improved security, optimized agricultural practices, and enhanced retail analytics. The ability to localize objects and understand their context opens doors to a wide range of possibilities.
| Object Detection Algorithm | Speed | Accuracy |
|---|---|---|
| Haar cascade classifiers | Fast | Lower |
| YOLO | Real-time | Moderate |
| Faster R-CNN | Slower | Higher |
Deep Dive into Classification
Classification is a fundamental process in image analysis and computer vision. It involves assigning labels or categories to images or specific regions of interest. By classifying images, we can gain a holistic understanding of their content.
In recent years, deep learning techniques, specifically Convolutional Neural Networks (CNNs), have revolutionized image classification. CNNs automatically learn hierarchical features from images, allowing for more accurate and robust classification results. This has significantly enhanced the performance of image analysis tasks.
Classification has a wide range of applications, including image tagging, face recognition, and disease diagnosis in medical imaging. For example, image tagging algorithms classify images based on their content, enabling efficient organization and searchability of large image collections. Face recognition systems use classification algorithms to identify individuals from facial images, enhancing security and personalized user experiences.
The Power of Deep Learning
Deep learning-based approaches have proven to be highly effective in image classification tasks. CNNs excel at learning complex and nuanced features from images, enabling them to accurately classify a wide variety of objects and scenes. The hierarchical nature of CNNs allows them to capture both low-level visual features, such as edges and textures, and high-level semantic concepts, such as object shapes and structures.
Convolutional layers in CNNs apply filters to the input image, detecting local patterns and features. Pooling layers help reduce the spatial dimensions of the features, making the network more efficient. Fully connected layers at the end of the network make the final class predictions based on the learned features.
With deep learning and CNNs, image classification has become more automated and less reliant on handcrafted features. The models learn directly from the data, making them adaptable to various image domains and reducing the need for manual feature engineering.
"Deep learning techniques, particularly Convolutional Neural Networks (CNNs), have revolutionized image classification by automatically learning hierarchical features."
Image classification plays a crucial role in a wide range of industries and domains. In the medical field, classification algorithms can aid in the diagnosis of diseases by analyzing medical images and identifying patterns associated with specific conditions. In retail and e-commerce, classification algorithms can automatically tag and categorize products, improving search functionality and personalizing customer experiences.
As machine learning and deep learning continue to advance, image classification algorithms are becoming more accurate and capable of handling complex tasks. The future of image classification holds immense potential for various industries, from healthcare to autonomous vehicles, enabling us to extract valuable insights and make more informed decisions based on image content.
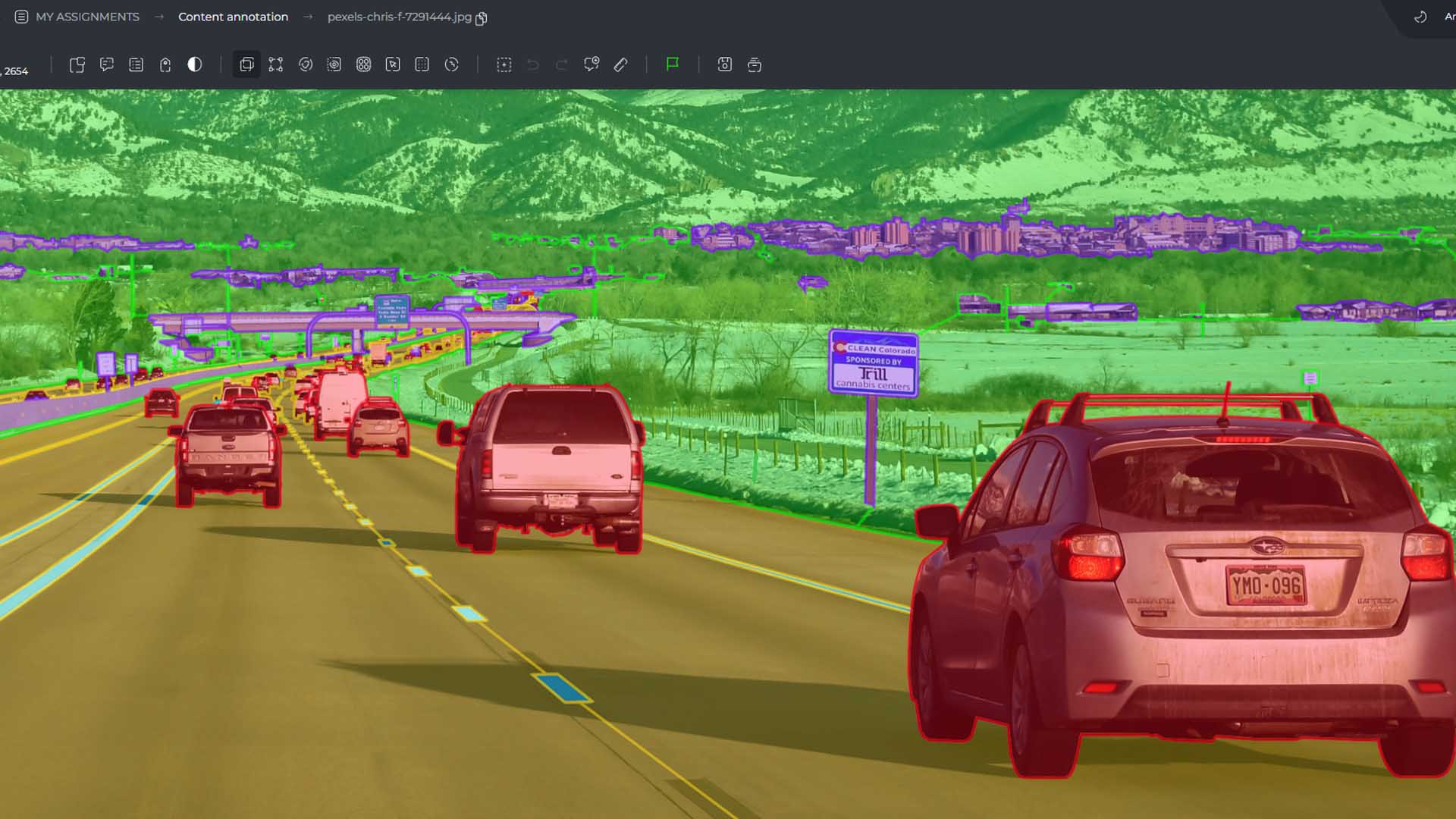
Comparative Analysis and Use Cases
When it comes to image analysis techniques, understanding the distinct applications and strengths of segmentation, detection, and classification is essential. In this section, we will compare these approaches, highlighting their differences and exploring their use cases in various industries.
Segmentation: Extracting Fine-Grained Information
Segmentation excels in providing fine-grained information by dividing an image or video into meaningful regions. This technique is particularly valuable in the field of medical image analysis, allowing professionals to identify and analyze specific areas of interest. For example, in the diagnosis of tumors or the assessment of diseases, segmentation enables the accurate delineation of affected regions. Additionally, segmentation finds relevance in manufacturing defect detection, where it helps identify and analyze defects in products during the quality control process.
Detection: Identifying Specific Objects and Locations
Detection focuses on identifying specific objects and their locations within an image or video. This technique is widely used in industries such as video surveillance and agriculture. In the realm of video surveillance, detection aids in identifying individuals, vehicles, or objects of interest. This crucial information enhances security measures and facilitates forensic investigations. In agriculture, detection plays a vital role in crop monitoring by identifying and tracking the growth patterns of plants, helping farmers optimize irrigation and fertilizer application.
Classification: Assigning Labels for Quick Analysis
Classification is a faster approach that assigns labels to images or regions, providing a holistic understanding of their content. Its efficiency makes it suitable for tasks like image tagging, where labels are assigned to images for better organization and retrieval. Classification also finds application in industries such as augmented reality, where real-time object recognition and labeling enable immersive experiences and interactive applications.
By comparing these techniques, we can see that segmentation excels in providing fine-grained information essential for medical image analysis and manufacturing defect detection. Detection, on the other hand, is prevalent in video surveillance and agriculture, where the identification and tracking of specific objects and locations are paramount. Classification is faster and more suitable for tasks like image tagging and augmented reality, where quick analysis and labeling are necessary.
Comparative Analysis of Segmentation, Detection, and Classification
| Technique | Strengths | Use Cases |
|---|---|---|
| Segmentation | Provides fine-grained information | Medical image analysis, manufacturing defect detection |
| Detection | Identifies specific objects and their locations | Video surveillance, agriculture |
| Classification | Assigns labels for quick analysis | Image tagging, augmented reality |
Segmentation vs Detection: When to Choose Each
When it comes to image analysis and object identification, two popular techniques stand out: segmentation and detection. Both approaches have their strengths and specific use cases, making it important to understand when to choose each one.
Segmentation is the preferred choice when the task requires a comprehensive understanding of object boundaries and extracting fine-grained information. This technique excels in applications such as medical image analysis and manufacturing defect detection, where precise delineation and identification of regions are essential.
On the other hand, detection proves to be more effective when the focus lies on identifying specific objects and their locations. This makes it particularly useful in video surveillance, where quick and accurate identification of people or objects is crucial.
The choice between segmentation and detection ultimately depends on the specific requirements of the application at hand. If the goal is to analyze medical images or detect anomalies during the manufacturing process, segmentation provides the necessary level of detail and fine-grained information. Conversely, in situations where the objective is to track objects in real-time or monitor activities through video surveillance, the speed and accuracy of detection make it the more suitable option.
Understanding the strengths and limitations of both techniques is key to implementing the most appropriate solution for a given scenario. By carefully considering the desired level of detail, the nature of the objects being analyzed, and the application requirements, professionals in the fields of medical image analysis, manufacturing defect detection, and video surveillance can make informed decisions on whether to opt for segmentation or detection.
"Segmentation is ideal for tasks that require understanding object boundaries and extracting fine-grained information, such as medical image analysis and manufacturing defect detection. Detection, on the other hand, is suitable for tasks that involve identifying specific objects and their locations, like video surveillance."
Table: Comparing Segmentation and Detection
| Segmentation | Detection | |
|---|---|---|
| Key Strengths | - Provides object boundaries | - Identifies specific objects and their locations |
| Use Cases | - Medical image analysis - Manufacturing defect detection | - Video surveillance - Object tracking |
| Level of Detail | - Fine-grained information extraction | - Quick identification of objects |
As seen in the comparison above, segmentation and detection have distinctive attributes that suit different application requirements. Therefore, it is vital to choose the right technique based on the desired level of detail, real-time analysis needs, and the specific industry or domain. By leveraging the advantages of segmentation and detection, professionals can enhance their image analysis capabilities for tasks such as medical diagnostics, manufacturing quality assurance, and video surveillance.
Detection vs Classification: Differentiating Factors
When it comes to analyzing images and identifying objects, two key tasks in computer vision are detection and classification. While both approaches have their own strengths and applications, they differ significantly in their outcomes and focus.
Detection: Detection goes beyond simple classification by providing not only class labels but also precise object locations through bounding boxes. By accurately localizing objects within an image, detection enables the contextual understanding and interaction with the environment. This makes detection particularly valuable in applications like augmented reality, where real-time interaction with objects is essential.
Classification: On the other hand, classification focuses on assigning labels to images or regions based on their visual content. It aims to provide a holistic understanding of the image by categorizing it into predefined classes or categories. Classification is typically faster than detection, making it suitable for tasks like image tagging and labeling, where speed is crucial.
While both detection and classification are vital in many computer vision applications, their use cases vary. Detection excels in tasks that require precise object locations, enabling augmented reality experiences and real-time interaction. Classification, on the other hand, is better suited for tasks that involve assigning labels to images or regions quickly, such as image tagging and labeling.
For a better understanding, refer to the table below:
| Task | Outcome | Applications |
|---|---|---|
| Detection | Precise object locations through bounding boxes | Augmented reality, object tracking, video surveillance |
| Classification | Assigning labels to images or regions | Image tagging, object recognition, content-based search |
As the table illustrates, detection provides precise object localization, making it invaluable in applications like augmented reality, object tracking, and video surveillance. Classification, on the other hand, focuses on assigning labels quickly and efficiently, making it suitable for image tagging, object recognition, and content-based search.
Understanding the differences between detection and classification helps professionals in computer vision choose the most appropriate approach for their
Combined Approaches: Fusion of Segmentation, Detection, and Classification
In advanced computer vision applications, a combination of segmentation, detection, and classification can achieve higher accuracy and richer insights. By fusing the outputs of these tasks, machines can leverage the strengths of each approach. For example, in autonomous driving, segmentation can identify drivable areas and objects, detection can identify specific objects like pedestrians and vehicles, and classification can assign labels for further understanding.
By combining these approaches, autonomous vehicles can navigate complex environments with precision and safety. The segmentation algorithm can accurately delineate the boundaries of lanes and obstacles, providing critical information for path planning. Object detection can identify pedestrians, cyclists, and other vehicles, ensuring the vehicle's ability to detect and respond to potential hazards in real-time. Classification algorithms can assign labels to different objects, enhancing the vehicle's understanding of its surroundings and enabling it to make informed decisions.
The fusion of segmentation, detection, and classification is crucial for achieving the level of autonomy required for self-driving cars. By integrating these techniques, autonomous vehicles can navigate and interact with the world in a manner that is closer to human-like perception and understanding.
Advantages of Combined Approaches
- Improved accuracy: By combining segmentation, detection, and classification, the overall accuracy of computer vision systems can be significantly enhanced, leading to more reliable and robust results.
- Richer insights: The fusion of these approaches allows for a deeper understanding of visual data, enabling machines to extract valuable information and make more informed decisions.
- Contextual understanding: By simultaneously analyzing various aspects of an image or video, computers can gain a holistic understanding of the scene, including object boundaries, locations, and labels.
- Adaptability: Combined approaches can be tailored to different use cases, making them versatile and adaptable to the specific requirements of various industries and applications.
Challenges and Considerations
While combined approaches offer significant advantages, there are challenges and considerations that need to be addressed:
- Computational complexity: The simultaneous execution of segmentation, detection, and classification tasks can be computationally intensive and may require optimized algorithms and hardware.
- Data requirements: Combined approaches typically require larger and more diverse datasets to train models effectively, which can be a challenge in domains with limited labeled data.
- Integration: Effective integration of segmentation, detection, and classification algorithms requires careful coordination and synchronization to ensure accurate and timely results.
- Real-time performance: In time-critical applications, such as autonomous driving, the combined approaches must be able to process and analyze visual data in real-time to support real-time decision-making.
Example Use Case: Autonomous Driving
Autonomous driving represents a compelling use case for the fusion of segmentation, detection, and classification. Let's consider an example scenario:
In a bustling city environment, an autonomous vehicle needs to navigate through congested traffic, perceive traffic signs, identify pedestrians, and avoid obstacles. Through combined approaches, segmentation can analyze the scene and identify drivable areas, while detection can locate and classify objects like cars, pedestrians, and traffic signs. Classification can provide additional context, such as the specific type of traffic sign or the intention of pedestrians.
With the fusion of these approaches, the autonomous vehicle gains a comprehensive understanding of its environment and can make informed decisions to ensure safe and efficient navigation.
To summarize, the fusion of segmentation, detection, and classification enables machines to achieve higher accuracy, richer insights, and contextual understanding in advanced computer vision applications. Whether in autonomous driving or other domains, the integration of these approaches paves the way for more sophisticated and intelligent systems.
| Advantages | Challenges | Considerations |
|---|---|---|
| Improved accuracy | Computational complexity | Data requirements |
| Richer insights | Integration | Coordination and synchronization |
| Contextual understanding | Real-time performance | Large and diverse datasets |
| Adaptability |
Conclusion
Semantic segmentation, object detection, and classification are essential tasks in computer vision that serve distinct purposes. Segmentation allows for the extraction of fine-grained information about object boundaries and regions, providing detailed insights into the composition of an image or video. Object detection, on the other hand, focuses on the identification and localization of specific objects within an image or video. Classification assigns labels to images or regions, enabling a holistic understanding of the content.
Choosing the right approach depends on the specific application requirements and desired outcomes. Semantic segmentation is particularly valuable in medical image analysis and manufacturing defect detection, where precise object boundaries and fine-grained information are critical. Object detection, with its ability to identify specific objects and their locations, is widely used in video surveillance and agriculture for tasks like crop monitoring.
Classification, with its speed and ability to assign labels to images or regions, is well-suited for tasks like image tagging and labeling. By understanding the nuances of segmentation, detection, and classification, professionals in computer vision can effectively select the appropriate approach for their projects, tailored to the specific objectives and constraints.
Overall, computer vision techniques like segmentation, detection, and classification enable machines to analyze and interpret visual data, unlocking a wide range of applications across various industries and domains.
Additional Resources
Are you looking to dive deeper into the world of computer vision and learn more about semantic segmentation and object detection? Here are some additional resources that can help expand your knowledge:
- "Introduction to Computer Vision" by Stanford University. This online course provides a comprehensive introduction to computer vision, covering various topics including semantic segmentation and object detection. You can access the course materials and lectures for free on the university's website.
- "Deep Learning for Computer Vision: A Hands-On Guide" by Adrian Rosebrock. This book offers practical guidance on implementing deep learning techniques for computer vision tasks, including semantic segmentation and object detection. It provides step-by-step tutorials and code examples to help you get started.
- "Computer Vision: Algorithms and Applications" by Richard Szeliski. This textbook is a valuable resource for understanding the fundamentals of computer vision. It covers a wide range of topics, including image segmentation, object detection, and other key techniques in the field.
By exploring these additional resources, you can gain a deeper understanding of computer vision, semantic segmentation, and object detection, and further enhance your skills in this exciting field.
FAQ
What is semantic segmentation and object detection?
Semantic segmentation is the process of dividing an image into meaningful regions and assigning class labels to each pixel. Object detection involves localizing and classifying objects within an image or video, providing their bounding boxes.
What are the differences between semantic segmentation and object detection?
Semantic segmentation focuses on identifying and classifying every pixel in an image, while object detection focuses on identifying specific objects and their locations.
What are some real-world applications of semantic segmentation?
Semantic segmentation has applications in medical image analysis, manufacturing defect detection, robotics, and more.
What are some real-world applications of object detection?
Object detection is used in video surveillance, agriculture for crop monitoring, retail analytics for customer behavior analysis, and other applications.
What is image classification?
Image classification is the process of assigning labels or categories to images or specific regions to provide a holistic understanding of image content.
How does deep learning contribute to image classification?
Deep learning techniques, particularly Convolutional Neural Networks (CNNs), have improved image classification by automatically learning hierarchical features.
What are the differences between segmentation, detection, and classification?
Segmentation focuses on object boundaries and fine-grained information, detection on specific object identification and localization, and classification on assigning labels or categories.
When should I choose segmentation over detection?
Segmentation is preferable when tasks require understanding object boundaries and extracting fine-grained information, like medical image analysis and manufacturing defect detection.
When should I choose detection over segmentation?
Detection is suitable for tasks that involve identifying specific objects and their locations, like video surveillance and agriculture.
How do detection and classification differ?
Detection provides precise object locations with bounding boxes, enabling contextual understanding, while classification assigns labels to images or regions and is faster.
Can segmentation, detection, and classification be combined?
Yes, in advanced computer vision applications, a combination of segmentation, detection, and classification can achieve higher accuracy and richer insights.