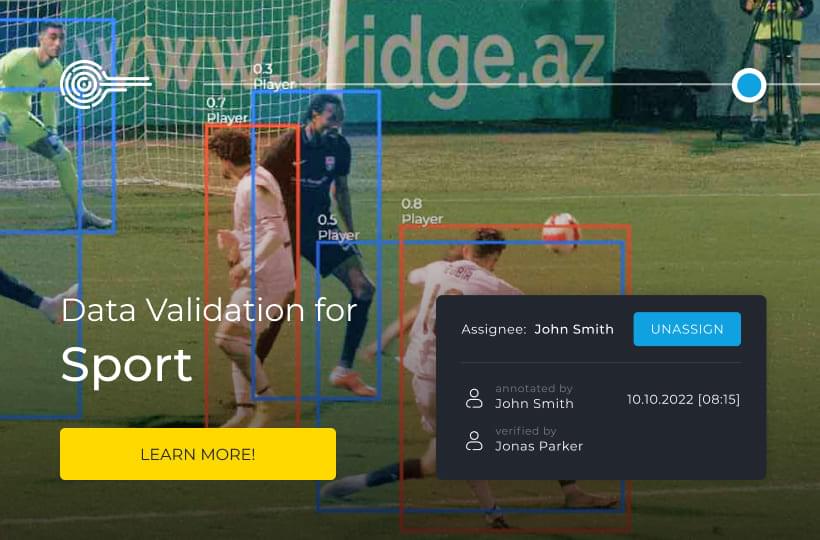
Uncertainty Sampling Explained: Targeting the Most Informative Samples
This AI training method can change how models are trained in machine learning, where large data sets can make the learning process difficult. The idea is to let the algorithm decide which examples it finds most informative. Compared to random sampling, the hope is to achieve better performance with the same amount of training data or to achieve the same performance with fewer data focused on the most informative samples, reducing the financial cost of labeling and increasing the training performance of the AI model.
Uncertainty sampling is excellent in cases where manual annotation is expensive and time-consuming. For example, let's say you need to do sentiment analysis for 8,000 tweets. In this case, uncertainty sampling can help determine which tweets to annotate, significantly improving the performance of your model
Focusing on the most informative samples regarding training data speeds up machine learning.
Key Takeaways
- Focusing on the most informative samples enhances machine learning efficiency.
- Uncertainty sampling is ideal for tasks where data annotation is costly and time-consuming.
- It significantly accelerates the training process of models, such as those used in sentiment analysis.
- This approach can drastically improve model performance and accuracy.

What is Uncertainty Sampling?
When a machine learning model makes a prediction, it often provides confidence in that prediction. If the model is uncertain (low confidence), then human feedback can help. Getting human feedback when the model is uncertain is a type of active learning known as uncertainty sampling.
The Importance of Sample Selection in Machine Learning
Machine learning has a "butterfly effect" like chaotic processes: even small changes can significantly impact the final result. Data sampling and labeling processes are not secondary; they play a key role. The quality of the selected samples directly affects the accuracy and efficiency of the model, so it is essential to pay special attention to this.
Types of Uncertainty Sampling
Uncertainty sampling in active learning encompasses different approaches. Each aims to optimize the labeling process by focusing on data points with maximum uncertainty. We will explore three key types: maximum uncertainty sampling, least confidence sampling, and margin sampling.
Maximum Uncertainty Sampling
The method of maximum uncertainty in the sample aims to find the data in which the model has the most doubts about its forecast. This means that the algorithm selects exactly those examples with the most uncertain predictions.
This approach helps to improve the model faster because it focuses on the most challenging cases that can significantly affect its training. Instead of wasting resources on labeling already precise or insignificant data, the method focuses on the most informative examples, thereby reducing unnecessary work and increasing training efficiency.
Least Confidence Sampling
The least confidence method looks for the data in which the model has the least confidence in its prediction. In other words, it focuses on cases where the model cannot confidently determine the correct annotation.
The algorithm benefits the most from selecting such examples for labeling, as such labels help to refine its prediction in the most questionable areas and allow for better class distinction and model accuracy, especially in complex or ambiguous cases that might otherwise be overlooked.
Margin Sampling
The margin sampling method searches for data in which the difference between a forecast's highest and second-highest probability is minimal. In other words, the model is almost equally confident in two options without knowing which class to assign this sample to.
If they are correctly labeled, it will help the model better determine the distinction between categories.
The margin sampling method lets you focus on the data, significantly improving classification quality. It makes it practical for active learning, as it helps reduce the cost of annotating data while maximizing the benefits.
Selection Process
After evaluating model uncertainty, selecting the most informative samples is vital. Sampling by Uncertainty and Density (SUD) and Clustering (SBC) enhance this selection. For example, SUD combines K-Nearest-Neighbor density with uncertainty metrics to pinpoint densely uncertain data points.
This careful selection process is essential for active learning. Active learning benefits from focusing on uncertain data points, including pool-based sampling. This is true, even in the early stages, where it improves performance in tasks like word sense disambiguation and text classification.
Active Learning Scenarios
Sampling with uncertainty is a powerful method in active learning, as it can significantly reduce the number of labeled examples needed to train an accurate model.
For example, the dual supervised learning approach focuses on those samples in which the model is most uncertain.
In areas where errors can have serious consequences, such as nuclear reactor modeling, uncertainty sampling techniques help improve safety and efficiency. By using Total Monte Carlo (TMC) and Correlated Sampling (CS), engineers can create more accurate models of reactor performance, assess potential risks, and improve safety measures.
Reducing Annotation Costs
One of the main advantages of uncertainty sampling is that it significantly reduces the cost of labeling the data. Instead of wasting resources on labeling all samples in a dataset, this method selects only the most valuable ones for model training.
The algorithm determines which data causes the most significant uncertainty in model predictions and sends them for manual labeling. This lets you get the most out of each added labeled sample, which is especially important when working with large amounts of data.
With this approach, analysts and machine learning specialists can significantly reduce the amount of data that needs to be manually checked, saving time, resources, and money.
Balancing Exploration and Exploitation
You can focus on familiar topics to consolidate your knowledge (this is exploitation) or try something completely new to broaden your horizons.
The same principle applies to machine learning. If an algorithm explores too much, it wastes resources on labeling less useful examples instead of improving the knowledge it already has. To solve this problem, special algorithms determine when to explore new data and focus on the already selected data. They analyze the dataset's structure and select the most useful examples for manual verification. This allows for faster model training, reducing unnecessary work and markup costs.
Best Practices for Using Uncertainty Sampling
Following best practices when selecting data to train machine learning models is important. First, you need to clearly define the goal to understand which data is most important for the model. Then, you should create a continuous improvement process where each new data set helps the model become more accurate. This allows you to focus on the most uncertain data, which leads to gradual improvement of the results.
Future Trends in Uncertainty Sampling
In the future, the uncertainty method will be more closely combined with the latest deep learning methods to find new applications in big data analysis. This will significantly improve the accuracy and speed of predictive models, promising significant progress in the development of machine learning.
Summary
Trends in uncertainty-based sampling show that it is increasingly being integrated with deep learning. This is a logical step, as deep learning works well with large amounts of data and complex models. Such integration helps to better manage different types of uncertainty in predictive models, including aleatory (uncertainty due to random factors) and epistemic (uncertainty arising from insufficient knowledge or data).
The introduction and use of probabilistic models and stochastic finite element methods (FEM) allows for a more accurate accounting of uncertainty in forecasts. Techniques such as the Nataf transformation and Copula functions are essential tools for this integration, as they help to represent and model uncertainty in deep learning models in more detail.
The uncertainty-based sampling method has great potential for dealing with big data. As the amount of data constantly grows, it becomes essential to have effective sampling methods to manage and analyze these vast data sets. Active learning, complemented by modern uncertainty-based sampling techniques, can significantly reduce the cost of data annotation while increasing the amount of helpful information.
Non-probabilistic methods such as fuzzy set theory and various membership functions (e.g., Gaussian and triangular functions) offer innovative solutions for incomplete information. Machine learning's success in multiple fields also contributes to its application to modeling random fields, allowing for more accurate spatial uncertainty simulation. This opens up new opportunities for more efficient and accurate big data analysis.
FAQ
What is uncertainty sampling?
Uncertainty sampling is an active learning method that identifies the most uncertain data points in an unlabeled dataset for labeling. This strategy focuses on samples where the model's prediction is least confident. Training on the most informative samples aids in improving model accuracy and performance.
Why is sample selection important in machine learning?
The quality of samples chosen for training significantly affects the performance of the resulting models. High-quality, informative samples improve model accuracy, efficiency, and robustness. They also reduce annotation costs and resource usage.
What are the different types of uncertainty sampling?
Uncertainty sampling can be categorized into several types. These include Maximum Uncertainty Sampling, focusing on the highest overall uncertainty across predictions. Least Confidence Sampling targets the data point with the lowest maximal probability. Margin Sampling considers the slightest difference between the most and second-most likely predictions.
How does uncertainty sampling work?
The process starts by evaluating each data point's uncertainty levels. Measures like classification uncertainty, margin of confidence, and entropy are used. Based on these evaluations, the most informative samples are selected for labeling, optimizing the model's learning process.
What are the benefits of uncertainty sampling?
The method's main advantage is that it reduces annotation costs, as only the most informative samples are selected for labeling. This lets you get more helpful information from each annotated sample, increasing the efficiency and effectiveness of the machine-learning project.
What challenges come with implementing uncertainty sampling?
Challenges include computational complexity due to the detailed calculations required to measure uncertainty. There is also a need to balance exploring new and exploiting samples that offer significant incremental learning.
How does uncertainty sampling compare to other sampling methods?
Unlike random sampling, which might miss critical data points, uncertainty sampling focuses on the most uncertain and informative samples. This makes it more cost-effective. While stratified sampling divides the dataset into subgroups, it doesn't always target uncertainty effectively. This is critical for optimizing machine learning models.
What are the best practices for using uncertainty sampling?
Adequate uncertainty sampling requires setting clear objectives and maintaining an iterative feedback loop. These practices ensure that selected samples genuinely reflect the most significant areas of uncertainty. This continuously improves the model through successive training iterations.
What are the future trends in uncertainty sampling?
Future trends include deeper integration with advanced deep learning techniques and emerging applications in big data. These innovations are expected to enhance predictive model accuracy and efficiency further. They mark a promising direction for the evolution of machine learning methodologies.