Types of Data Annotation: Image, Text, Audio, Video Guide
Data annotation is the foundation that helps AI understand the world around it. By adding meaningful labels to raw data, AI systems learn to recognize patterns, make decisions, and deliver valuable results. Depending on the project, the data can take many forms - like images, text, audio, or video - and each type needs its special approach to annotation.
Introduction to Data Annotation for AI and Machine Learning
Different projects require different types of annotation, each suited to a particular data form and use case. By carefully labeling data, AI systems learn to recognize patterns, interpret meaning, and deliver precise results. The main annotation categories include:
- Image annotation is used in computer vision tasks such as object detection, image segmentation, and facial recognition.
- Text annotation is crucial for NLP annotation, enabling machines to understand language through tasks like sentiment analysis, entity recognition, and intent classification.
- Audio annotation is essential for speech recognition, speaker identification, and sound classification.
- Video annotation - combines image and audio annotation techniques to handle temporal data in applications like action recognition and video surveillance.

Blueprint for Machine Readability
Data must be structured to train AI models effectively so machines can easily interpret. Machine readability involves clear, consistent, and precise annotation practices that turn raw data into valuable, labeled information. The blueprint includes the following key steps:
- Define Annotation Categories Clearly. Establish distinct and well-documented categories for labeling data, such as objects in images, text entities, or audio sounds. This clarity reduces ambiguity and improves annotation consistency.
- Use Standardized Formats. Adopt standard data formats (e.g., JSON, XML, COCO for images) to ensure compatibility across tools and workflows. Standardization simplifies data integration and processing.
- Ensure Consistent Labeling. To maintain quality, uniform rules and guidelines must be applied to all annotators and data samples. Consistency prevents confusion and improves model training outcomes.
- Incorporate Multimodal Annotation When Needed. For complex AI tasks involving multiple data types (image, text, audio, video annotation), coordinate annotations across modalities to preserve context and enhance model understanding.
- Perform Quality Checks and Validation. Implement systematic reviews and automated quality checks to catch errors and improve annotation accuracy before model training.
Exploring the types of data annotation
Each annotation category serves a unique purpose, helping AI models learn from different kinds of data. Image annotation powers computer vision applications by labeling objects, boundaries, and features within images. Text annotation, often called NLP annotation, involves tagging words, phrases, or sentences to help machines understand language. Audio annotation identifies sounds, speech, and patterns, while video annotation combines image and audio labeling to capture complex, time-based information.
Visual and Linguistic Labeling Systems
Visual and linguistic labeling systems represent two distinct approaches to organizing and tagging data for AI training. Objects are identified and marked in image annotation with bounding boxes, polygons, or key points to help computer vision models recognize and classify what appears in pictures. Video annotation extends these techniques to sequences of frames, adding the challenge of tracking moving objects and capturing changes over time.
Linguistic labeling, meanwhile, revolves around text annotation and NLP annotation. This includes assigning labels such as parts of speech, named entities, sentiment tags, or intent markers to words and sentences. When combined with audio annotation labeling speech segments, speaker identity, or sound events, it supports multimodal annotation, integrating multiple data types to improve AI understanding.
Each system has its tools, guidelines, and challenges. Visual labeling often requires specialized software to outline objects or actions in images and videos precisely. Linguistic labeling demands deep knowledge of language and context to tag ambiguous or complex text correctly.
This combination also allows AI solutions to become more versatile. For example, in autonomous vehicles, image and video annotation guide object detection on the road, while audio annotation may capture environmental sounds. In virtual assistants, text annotation helps interpret user commands, and audio annotation processes spoken input. Multimodal annotation ties these elements together, creating richer datasets that boost AI performance.
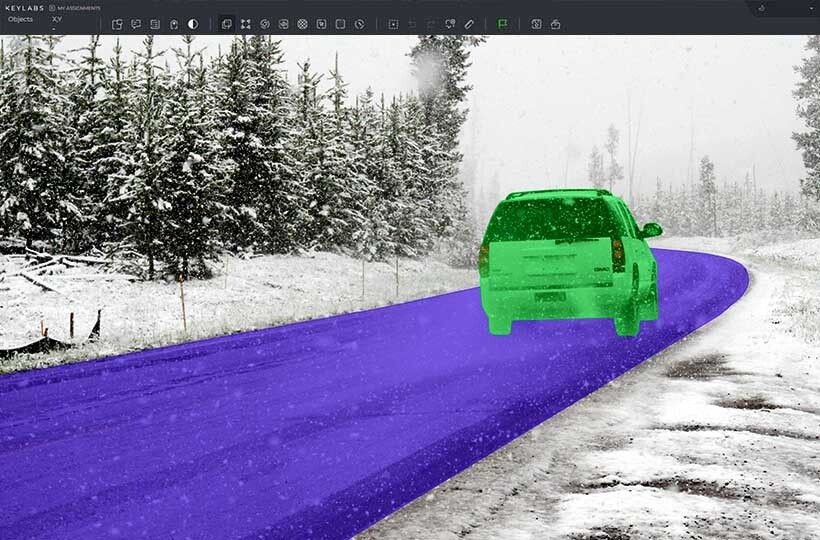
Image Annotation: Techniques and Applications
Depending on the project, the annotation can be as simple as tagging a single object or as complex as outlining multiple objects with precise boundaries, attributes, and relationships.
There are several standard techniques used in image annotation:
- Bounding Boxes. Rectangular boxes are drawn around objects to help models detect and classify them. This method is widely used in pedestrian detection, vehicle recognition, and retail shelf analysis.
- Polygons and Segmentation. Polygonal annotation traces an object's exact shape for more detailed labeling. Semantic and instance segmentation go further by labeling each pixel, making this method ideal for medical imaging or autonomous driving.
- Key Point Annotation. Specific points (like joints or facial landmarks) are marked to train models for pose estimation or facial recognition.
- Image Classification. Sometimes, the whole image is labeled as belonging to a particular category. This is useful for scene recognition or content moderation.
- Attribute Tagging. Objects are labeled not only by what they are, but also by characteristics like color, size, or condition, which helps fine-tune AI decision-making.
Image annotation is used across a wide range of industries. It's applied to X-rays, CT scans, and MRI images to train diagnostic models in healthcare. In agriculture, satellite or drone images are annotated to detect crop health or identify land use. In retail and e-commerce, annotated product images help improve search and recommendation systems. Self-driving cars rely heavily on annotated images to recognize road signs, lane markings, and other vehicles.
Text Annotation: Methods and Tools
Text annotation is at the heart of NLP annotation, allowing AI models to process and understand human language. It involves labeling parts of a text with tags that describe structure, meaning, sentiment, or intent.
There are several key methods used in text annotation:
- Entity Annotation. Words or phrases are marked as names, locations, organizations, dates, or product names. This method supports named entity recognition (NER) systems used in customer service, legal tech, and finance.
- Part-of-Speech (POS) Tagging. Every word in a sentence is labeled with its grammatical role (noun, verb, adjective, etc.). This helps models understand sentence structure and is often a foundational step in other NLP tasks.
- Sentiment Annotation. Phrases or sentences are labeled with a positive, negative, or neutral emotional tone. This is widely used in social media monitoring, brand tracking, and customer feedback analysis.
- Intent Annotation. This method, especially important in training virtual assistants and chatbots, involves labeling the user's goal or purpose behind a query or message.
- Relationship Annotation. Connections between text parts are labeled, helping models understand cause-effect relationships, coreference, or logical structure.
- Linguistic Attribute Tagging. Labels are added for features like slang, dialect, or formality level, improving model performance across diverse language inputs.
Audio Annotation: Strategies for Accurate Labeling
Audio annotation helps AI models interpret and analyze sound. It involves labeling raw audio files with information about speech, music, ambient noise, and other audio events. These labels train systems for speech recognition, speaker identification, language understanding, and sound classification, making audio annotation a key part of standalone and multimodal annotation workflows.
Accurate audio annotation requires attention to detail, as sound data is often complex and continuous. Several strategies are used to ensure clarity and consistency:
- Speech Transcription. Spoken content is transcribed into text, either verbatim or with cleaned-up formatting. This is essential for training speech-to-text systems, voice assistants, and transcription services.
- Speaker Diarization. Annotators mark who is speaking and when, distinguishing between different voices in a conversation. This supports models that handle meetings, interviews, or call center recordings.
- Timestamping. Labels are aligned precisely with time, often down to the millisecond. Timestamping is used in transcription and sound event detection to help models learn timing and duration.
- Sound Event Tagging. Non-speech audio, such as footsteps, sirens, door knocks, or background chatter, is labeled with tags describing the sound type. These tags are used in environmental sound recognition and intelligent surveillance systems.
- Emotion and Tone Annotation. Annotators tag audio segments based on vocal tone or emotional expression (e.g., angry, happy, neutral), which supports sentiment-aware systems like customer service bots.
In NLP and multimodal annotation projects, audio labels are frequently paired with text annotation, such as aligning transcripts with spoken audio or tagging intent in spoken phrases. In customer support, for example, models learn from the words and how they're said.
Summary
As AI continues to evolve, the ability to combine multiple data types—through multimodal annotation is becoming more central to real-world applications. From virtual assistants to autonomous vehicles and medical tools, annotation quality directly affects how well these systems perform. Selecting the proper methods and tools for each data type ensures that training datasets are machine-readable and closely matched to the needs of the task they're meant to support.
FAQ
What is data annotation and why is it used in machine learning?
Data annotation labels raw data such as images, text, audio, or video to make it understandable for AI models. Training machine learning systems needs to recognize patterns and make accurate predictions.
What is image annotation and where is it applied?
Image annotation involves labeling visual content using techniques like bounding boxes or segmentation. It's widely used in computer vision tasks like object detection, facial recognition, and autonomous driving.
How does text annotation support NLP models?
Text annotation labels language data with tags like sentiment, named entities, or intent. This allows NLP annotation models to understand human language's structure, meaning, and context.
What makes audio annotation different from other types?
Audio annotation involves continuous sound and requires precise time-based labeling of speech, music, or noise. It's used in voice assistants, speaker recognition, and sound classification applications.
What is video annotation and how is it performed?
Video annotation involves labeling objects and events across multiple frames to track changes over time. It often combines image and audio annotation in dynamic environments like surveillance and robotics.
What are annotation categories and why do they matter?
Annotation categories refer to data types and labeling strategies, such as classification, segmentation, or entity tagging. Choosing the right category ensures the model receives relevant and structured training data.
What is multimodal annotation?
Multimodal annotation combines two or more data types, like images with text or audio with video. This approach trains models to interpret multiple signals simultaneously, improving performance in complex AI tasks.
What challenges are common in audio and video annotation?
Overlapping speech, poor audio quality, and fast-moving visuals can make audio and video annotation difficult. These types often require more advanced tools and trained annotators to ensure accuracy.
What best practices apply to scaling annotation projects for large datasets?
We prioritize annotator training, detailed guidelines, and modular task design. Using platforms like Scale AI or Amazon SageMaker Ground Truth, we maintain consistency across millions of data points while adapting to edge cases critical for NLP models processing diverse linguistic patterns or CV systems handling variable lighting conditions.
Why is consistency important in data annotation?
Consistent annotation across all data points ensures that AI models learn correct patterns without confusion. It improves the reliability of computer vision, NLP, and multimodal annotation systems during training and deployment.