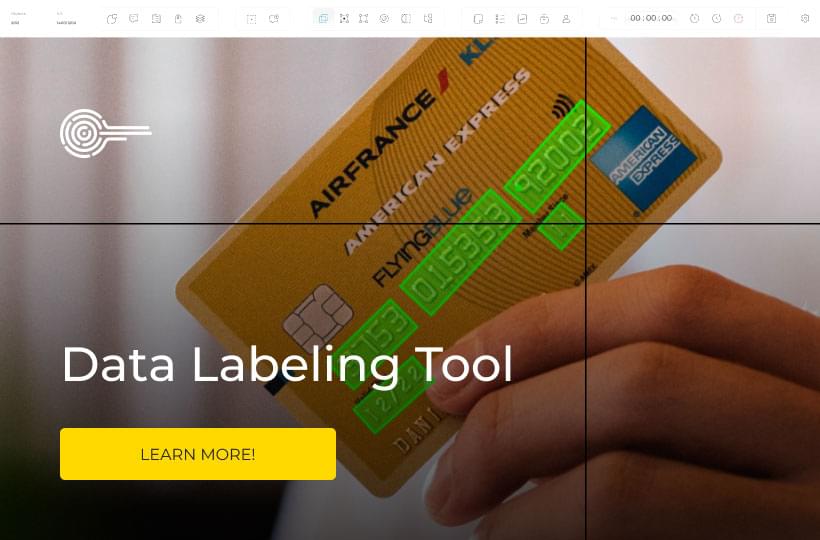
What Is Data Labeling And How To Use It To Create Specialized Answers And Predictions
There is a massive amount of data in the modern world, and it’s growing at an exponential rate. When trying to solve a problem using an ML-based AI system, the first step is to identify which data is relevant to your problem and the vast amounts that won’t be. Data labeling is the process of identifying objects and patterns in raw data that gives context to machine learning algorithms. It allows AI to identify people, cars, buildings, lines, etc., without having a person to specifically code that information. It’s creating context from raw data that ML-based AI systems can use to start to identify patterns on their own.

The uses of these systems are constantly evolving, and we already have thousands of uses. Computer models can use data from images to recognize traffic patterns, faces, and the volume of pedestrians, to name a few. Language programs can now recognize speech patterns, translate languages, restructure sentences, and even understand certain contexts within a human speech. While it may not be the most exciting step when using ML-based AI systems, it is arguably the most important.
Start At The Beginning: Types Of Data
When using an ML-based AI system, data is lumped into two categories to start structured and unstructured data. Structured data can be thought of as “recorded” data, i.e., information sets that are in relational databases, such as spreadsheets. Information such as serial numbers, phone numbers, product descriptions, and license plate numbers fall into this category.
Unstructured data is the majority of data that is floating around out in the world today. It is data that is not stored in organized databases. Audio files, video, weather data, or sensor data are all good examples of unstructured data. The biggest challenge to working with unstructured data is the sheer volume of it. It is not uncommon to find unstructured datasets with hundreds of billions of items. Making sure that you have the infrastructure to handle the amount of data you are going to use is the first hurdle in any project using ML-based AI systems.
Once you have the data you want to use, it is time to label all that data. Curating this is a huge task and make or break a project. We’ll go through the five most important factors and how they can impact your project.
The 4 Most Important Factors That Will Affect Your Data Labeling Process
1. Financial Cost Consideration
Understanding the budget required to acquire, store, and label data is something that must be considered at the start of every project. Many companies underestimate the time and cost of labeling data. The two main options are paying per hour or paying per task. Paying per hour can become expensive as you will have to pay for the training of your own staff (we’ll get into this later) or hire an external team that will have to be trained on what the expectations of your project specifically require.
Training per task may be more cost-efficient. However, it can encourage less quality as labelers focus more on how many tasks they can finish and how quickly they maintain quality. There are many factors when considering the cost of any project, but the first thing you should decide is our next factor, the type of workforce you want to use.

2. Workforce Management
Once you have the raw data, whether structured or unstructured, it’s time to start labeling. You’ll need a team of specifically trained people for such a job. Inconsistent labeling will lead to more generalized prediction models or unreliable prediction models that may end up sinking a project. Companies can either choose to train their staff how to label data or hire external specialized companies to do the work for them. Each presents its own factors to be considered and managed.
Training your own in-house staff will require the extra step of training them, of course! This adds extra time to the project, but it also may be beneficial because your staff will already be familiar with the type of work and the expected results that you are looking for the AI to produce. As data sets get larger and larger, it’s generally advisable to hire an external team. The major issue is organizing clear communication with this new team, especially if this communication crosses time zones and different languages/ cultures.
3. Quality Control
Now that you have your team/teams working on labeling data, you must maintain quality control. Because you are using humans to label data, they are subject to the laws of being human! This is what we call subjective data labeling. There will be many people labeling different data sections, and it would be impossible for one person to do any labeling data project unless you have years to spare. Because of this, each labeler is influenced by their own biases, culture, language, sense of humor, personal history, etc. Therefore, creating a guideline for labelers is vital to maintain consistent quality.
There is something called objective data, where this is a correct answer that each labeler must know. This often happens in more specialized fields, labeling types of trees, for example. The challenge posed here is that each labeler must have that specific field of knowledge. You also have to consider that no matter how expert a labeler may be, there is always human error, so you have to create a feedback system where the information is checked and double-checked. This is the case for both subjective and objective data.
4. Compliance with Privacy Laws
With the rise of the information age, the major concern has always been privacy - what is private vs. what is public in a time where the lines are blurred by social media, cookies, and customized technology. Many regulatory bodies must be kept in mind when working with large data. For any project, it is essential that both you and any employees who work on the project are aware of the regulations they must follow. This includes third-party contractors as well as in-house employees. It also means that data has to be stored and accessed only from secure devices that are well-protected.
This last factor seeps into the other factors as it directly affects how you train your workforce, your budget creating the secure infrastructure, and the quality control of the data being labeled. Always know the laws, and be up to date on the current regulations, or you will find whole projects sinking after all the work has already been done.
Conclusion
These factors are the most important aspects to consider when planning your data labeling projects. These are all foundational parts of the project that must be designed and built solidly not to undermine your project. Any project is headed for success with a well-trained workforce, a proper budget, a system of checks and double-checks, and knowledge of the information world.