Why is Data Quality So Important for Data Annotation?
Data quality is one of the most important factors in the creation of modern artificial intelligence. Data quality is also a critical factor for data annotation. Why is that? Like many processes in computing, data annotation is a garbage-in-garbage-out system.
Think of cooking. The best chefs demand the best quality ingredients to cook their recipes and prepare fine gourmet meals. That is because the chef's meals are only ever as good as the ingredients that they use. With data annotation, the data is the main ingredient. The annotated data you feed into a machine learning algorithm is the meal.

You want to feed it healthy data, the same way you need to feed yourself healthy food. If you eat junk food, that will affect your health and performance. You should know that, like the best chefs who have their own quality ingredients in their kitchens, we have high-quality datasets that could be used for your project.
Much of the data used in annotation are things like videos and pictures. One way to measure the quality of such information is in things like resolution and frame rates. Another factor is to make sure that the information is relevant.
For example, if you want to detect an object, say an apple, you'll need high-resolution pictures with apples in them. A labeling tool for object detection won't help detect apples if they aren't in the images, to begin with.
Another way to think of this is how humans learn and become educated. You may have a classroom of the best and brightest children. They don't know much about anything and will learn whatever you teach them.
Educating those children in nonsense instead of facts will have done them a great disservice. Those students' performance in life will suffer. Your AI is like your child. You want it to receive the best education possible. The world is, unfortunately, full of poorly educated AI. The performance of those AI products suffers much the same way as a poorly educated person's performance suffers.
Even smart people will make bad decisions if they only have bad information to ground their decisions on. An AI product is much the same. It needs to have been trained with good information to make good decisions and predictions. Any machine learning model or AI product.
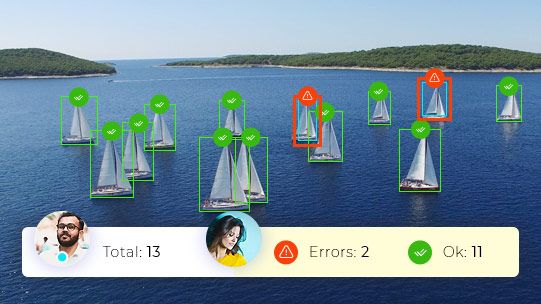
The Benefits of High-Quality Data for Machine Learning
High-quality data will ensure you will have the following benefits:
- Faster data training. Better quality data means faster and better results, with less mistakes that may need to be manually corrected. Such error correction is a time-consuming process.
- Increased accuracy and precision. While full 100% accuracy is usually unrealistic, you can greatly increase the level of accuracy with high-quality data.
- Support more features. Better quality data can allow you to create a more featureful AI that can handle more complex use cases. Less time spent on error correction means more time to move on to complex edge cases and more demanding features.
- Better quality of data annotation. It really is like cooking a meal this way. Better quality of data makes for better quality data annotation, just like better quality ingredients make a better meal.
- Save time and money. Data annotation and training can be much more expensive when there is bad quality data or erroneous and a lot of errors to correct. Having high-quality data ensures the processes of data annotation and data training go faster and more smoothly.
High-Quality Data Annotation is Important Too!
The processes of data annotation enhance the quality of your data. Data annotation also adds information in the form of metadata.
Continuing our cooking analogy, chefs also like using the best stoves, cookware, and sharpest knives. We like to use the best image annotation tools to get the best results. It is also important to have the right tools for the job.
Computer vision is usually a common feature of AI products. That's because a CV is needed to support many other features, such as object recognition. That is why we have and use the best image annotation tools for computer vision. That supports other vital features, such as object recognition, which of course, is the best image labeling tool for object detection too.
The Pit Falls of Low-Quality Data
Low-quality data can introduce mistakes and create delays every step of the way. In addition, low-quality or just plain bad data impacts the entire process of data annotation and data training. When that is all eventually done, a poor-quality product is created. We then have to ask, "Is it even worth it?" because it will create a bad user experience or even worse.
Poor-quality AI is a product of poor-quality data and takes much longer to train and create. It is also much more expensive because it takes so much longer. Errors that bad-quality data introduces take time to catch and correct. They introduce complicated bugs into your model.
That also means more iterations of data training and a long process of validating bug fixes. This can also be a bad experience for you, your company, and your team. It can get so bad that there is an old industry term: development hell. Once a project has entered into development hell and has been too long delayed, it can lead to some of the worst outcomes.
All the extra expenses, delays, and frustrations can mean that the project never leaves development hell. Instead, the project gets abandoned and is never completed. Before the project is abandoned, an expensive dead project can even kill a company.
Fortunately, that can all be avoided in a few different ways! Obviously, you should use high-quality data. You can improve your data through data annotation and other methods too.
You can enhance and improve your data annotation pipeline. You can closely monitor the data training process to understand better what it needs. Expanding your dataset can provide more of what your machine learning model needs. You can also try outsourcing what you need help with.