YOLOv7: A State-of-the-Art Real-Time Object Detector Explained
Simplicity meets innovation as YOLOv7 shatters the barriers of complexity by allowing rapid training on small datasets without the need for pre-trained weights. As state-of-the-art real-time object detectors pivot predominantly on the YOLO versions like YOLOv3, YOLOv4, YOLOv5, and now YOLOv7, this model represents not just technological evolution but also a revolution in accessible, real-time object detection capabilities.
While the application of object detection models was once confined to powerful, specialized processors, the times are changing. Edge devices equipped with CPU/GPU processors and NPU technology such as Neural Compute Sticks, Jetson AI edge devices, the Apple Neural Engine, Coral Edge TPU, and Neural Processing Engines are now increasingly popular for AI inferencing, thanks to their cost-effectiveness and proficiency. YOLOv7, with its array of optimized models, including YOLOv7-tiny and YOLOv7-W6, is at the forefront, delivering end-to-end optimization for varying computational environments.
Key Takeaways
- YOLOv7 surpasses former object detection models in both speed and accuracy, optimizing real-time object detection.
- Its cost-effectiveness is notable, as YOLOv7 thrives on several times cheaper hardware than other comparable neural networks.
- The model's training efficiency is significantly improved, requiring no pre-trained weights even for smaller datasets.
- Viso Suite by Viso.ai enhances YOLOv7's integration into the industry, indicating widespread adoption.
- YOLOv7 models are diverse, including versions for edge computing and high-performance computing, exemplifying its adaptability.
- The YOLOv7 introduction denotes not just an upgrade in the series but also a shift towards more inclusive and efficient real-time object detection solutions.

What Sets YOLOv7 Apart in Real-Time Object Detection
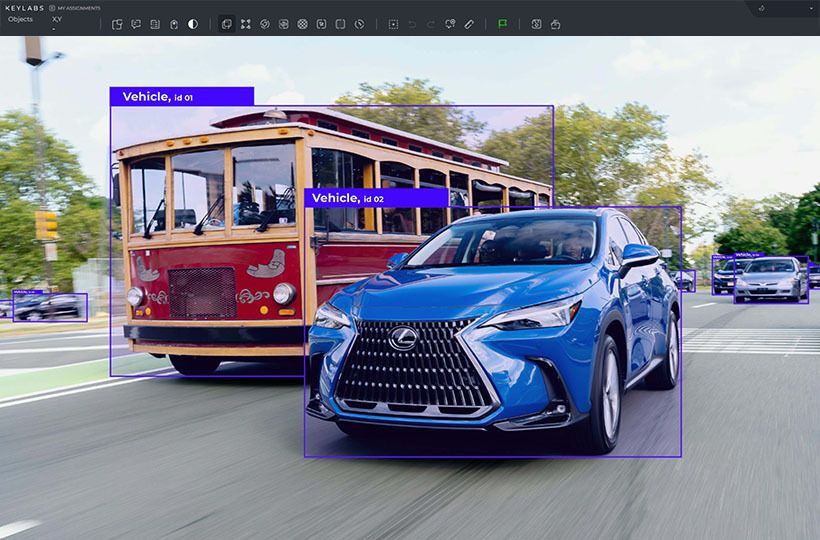
YOLOv7 has redefined the landscape of real-time object detection with its advanced capabilities, setting a new benchmark for performance. By achieving an impressive 56.8% AP accuracy rate, it has surpassed other high-profile models including YOLOX, YOLOR, and even Scaled-YOLOv4, making it the top choice for developers and researchers in the field of computer vision.
One of the key object detection advancements in YOLOv7 is its use of Extended Efficient Layer Aggregation Networks (E-ELAN), which enhance the learning capabilities of the network while maintaining the integrity of the original gradient paths. This is complemented by a sophisticated model scaling technique that adjusts the model's attributes to optimize various inference speeds.
Furthermore, YOLOv7 utilizes planned re-parameterized convolution techniques in its architecture, which significantly reduce the identity connections in layers that incorporate residual or concatenation. This innovation allows YOLOv7 to achieve higher speeds and accuracy in object detection, setting it apart from its predecessors and current competitors.
An additional unique feature of YOLOv7 is its implementation of Deep Supervision with lead and auxiliary heads, strategically improving the training performance of deep neural networks. This approach ensures that YOLOv7 not only learns more effectively but also adapts more dynamically to different object detection tasks.
The practical applications of YOLOv7's enhanced capabilities are vast, spanning from video analytics and robotics to autonomous vehicles. Its robust architecture and state-of-the-art object detection advancements make it an essential tool for industries requiring reliable and swift object detection.
The Evolution of YOLO Algorithms: From Inception to YOLOv7
Tracing the YOLO algorithm history reveals a dramatic evolution in the field of object detection, with each version increment bringing us closer to the peak of efficiency and accuracy embodied in the YOLOv7 official version. The journey from the original YOLO to the latest edition is not just a tale of technological advancement but a reflection of a growing understanding of what can be achieved in real-time object detection with the right YOLO architecture.
The YOLO Family: A Timeline
The inception of YOLO marked a pivotal shift in object detection. Traditional methods struggled with speed and computational efficiency, but YOLO revolutionized the process by introducing simultaneous prediction of bounding boxes and class probabilities for each grid cell, vastly enhancing real-time application capabilities. Through continuous improvements, including the adoption of Darknet-19 architecture in YOLOv2 (YOLO9000), YOLO algorithms have consistently pushed the boundaries, optimizing both accuracy and processing speed.
YOLOv7: The Official Descent
The YOLOv7 evolutionary journey is highlighted by its consolidation of past learnings and innovations into a robust framework ideal for real-world applications. Authored by the original creators of the YOLO series, YOLOv7 not only aligns with the technical pedigree of its predecessors but also introduces new enhancements that solidify its position in the cutting-edge of real-time object detection, making it a preferred choice in various applications from autonomous driving to retail analytics.
With each version, starting from YOLOv1's introduction on the PASCAL VOC2007 dataset achieving an mAP of 63.4, to YOLOv4's significant leap in both speed and accuracy in April 2020, the series has exemplified a commitment to progress and excellence. The YOLOv7 encapsulates this ongoing evolution, tailored by hands that have steered its course from the beginning.
| Version | Release Date | Key Improvements | mAP on COCO |
|---|---|---|---|
| YOLOv1 | 2016 | Initial model, 7x7 grid | 63.4 on PASCAL VOC2007 |
| YOLOv2 (YOLO9000) | 2017 | Multi-scale training, Darknet-19 architecture | 78.6 on PASCAL VOC2007 |
| YOLOv3-spp | 2018 | Optimizations for speed & mAP balance | 60.6% at 20 FPS on MS COCO |
| YOLOv4 | April 2020 | Focus on optimal speed and accuracy | Improvement noticed |
| YOLOv7 | 2022 | Further enhancements by original creators | Comprehensive improvements |
The table not only demarcates the milestones of YOLO's development but clearly illustrates the relentless pursuit of enhancing real-time object detection. YOLOv7, bearing the mark of its original innovators, is now robustly adopted, reflecting widespread trust and confidence in its capabilities throughout the machine learning community.
Understanding YOLOv7's Technological Advancements
The YOLOv7 architecture represents a significant leap forward in the field of real-time object detection. Leveraging the latest advancements in neural networks, YOLOv7 introduces a suite of optimization and efficiency features that distinctly set it apart. Key among these features are model re-parameterization, Extended Efficient Layer Aggregation Networks (E-ELAN), and sophisticated model scaling strategies. These elements not only enhance the model's accuracy but also improve the speed of inference, making YOLOv7 a powerhouse in neural network technology.
| Feature | Description | Impact |
|---|---|---|
| Model Re-parameterization | Merges computational models to reduce redundancy and enhance throughput. | Increases efficiency and speeds up real-time detection capabilities. |
| E-ELAN | Utilizes extended layer aggregation to optimize data flow within the network. | Enhances model responsiveness while maintaining high accuracy. |
| Model Scaling | Adjusts network size and complexity based on computational resources and requirements. | Ensures optimal performance across various devices from edge to cloud computing. |
YOLOv7's neural network base not only supports traditional GPU platforms but is also optimized for less conventional computing environments such as edge and cloud GPU scenarios. This flexibility allows YOLOv7 to be deployed in a variety of settings, from high-traffic areas requiring real-time processing to research environments where accuracy and speed are paramount.
Noteworthy performance statistics:
- YOLOv7 reduces parameter count by approximately 40% and computational load by about 50% compared to other leading object detectors.
- The architecture's capacity for rapid training on modest datasets without pre-trained weights presents a revolutionary advantage, especially in scenarios with limited resources.
- Despite its simplified framework, YOLOv7 delivers faster inference speeds and heightened detection accuracy, ensuring it stands out in the neural networks landscape.
At the core of YOLOv7's success is its innovative use of anchor boxes and a novel loss function which greatly minimizes the challenge of detecting small objects, a common hurdle in neural networks. Its capability to perform multi-scale detection allows for precise and reliable object identification across various sizes and scenarios.
The ongoing evolution of YOLOv7 exemplifies how neural network models like YOLO continue to advance the field of real-time object detection, making them indispensable tools in the tech industry. The adaptability and robust performance of YOLOv7 architecture secure its position as a front-runner in the development of AI applications across diverse sectors.
YOLOv7 introduction: Features and Functionalities
In the rapidly evolving landscape of real-time object detection, YOLOv7 marks a significant technological advancement. The introduction of YOLOv7 into the world of computer vision promises not only enhanced performance but also optimizes computational efficiency, making it a powerhouse in the YOLO series.
Benchmarking YOLOv7 Against Other Models
YOLOv7 benchmarks clearly demonstrate its superior capabilities in the field. Comparative studies show this model significantly outperforming its predecessors and other contemporary object detection models. For instance, YOLOv7 achieves faster inference speeds and higher object detection accuracy, qualities that are crucial for applications demanding real-time responses, such as autonomous driving and public safety monitoring.
In terms of computational efficiency, YOLOv7 cuts down on parameters by about 40% and reduces computation needs by nearly 50% compared to models like YOLOv6 and YOLOv5. These reductions not only preserve computational resources but also improve the model’s scalability and ease of integration into various platforms.
The YOLOv7's enhancements are not just about speed and efficiency; they translate into tangible improvements in object detection accuracy. This model sets new standards in recognizing and processing images with precision in diverse and challenging environments.
Innovations in Model Architecture
The architectural advancements in YOLOv7 are nothing short of revolutionary. With a refined focus on maximizing performance without compromising on speed, YOLOv7 incorporates cutting-edge technologies such as Extended Efficient Layer Aggregation (E-ELAN) and a novel re-parameterization approach.
The innovations extend to methodical enhancements in the model's backbone, which ensures that YOLOv7 remains not only robust but also adaptable to different computational demands. The integration of techniques like group convolution and model scaling optimizes the flow of operations and supports the model's dynamic learning capabilities.
YOLOv7 technological advancements also include a balanced training approach involving auxiliary and lead loss optimization. This method enhances the model's ability to learn from varied data inputs, thereby increasing its effectiveness in real-world applications.
Conclusively, YOLOv7 stands as a prime example of how thoughtful architectural design can lead to substantial improvements in both performance and practical usability, making it a standout model among contemporary object detection models.
YOLOv7's Impact on Industries and Applications
The deployment of YOLOv7 has significantly transformed several sectors by enhancing the capabilities of real-time object detection systems. This state-of-the-art technology has not only increased the automation processes but has also improved safety measures and operational efficiencies across various industries.
One of the standout implications of YOLOv7 application in the public safety sector is its ability to perform crowd detection in large public spaces, thereby enhancing security operations by facilitating the quick identification of abnormal behavior or other safety concerns. Similarly, in the construction industry, the technology is used to detect persons in unsafe zones, contributing markedly to onsite safety standards. Another compelling use-case of YOLOv7 involves enhancing computer vision systems in aviation for better monitoring and automated management.
The industry impact of YOLOv7 is also prominently seen in the realm of autonomous vehicles and smart city systems. By integrating YOLOv7's robust real-time object detection functionalities, autonomous vehicle systems are now equipped to recognize obstacles or pedestrians with enhanced accuracy, thereby improving navigational decisions and overall road safety.
"The introduction of YOLOv7 in smart city infrastructure has led to a new era of urban traffic and security management, where real-time data from numerous sources are analyzed instantaneously to improve urban living."
In terms of practical implementations, YOLOv7 has paved the way for real-world applications that were previously hindered by slower response times and lesser accuracy. Below is a comparison table to show how YOLOv7 stacks against previous methods in some practical applications:
| Application | Previous Methods | YOLOv7 Advantages |
|---|---|---|
| Retail Inventory Management | Manual audits, Basic barcode scans | Automated real-time tracking, Suspect activity alerts |
| Urban Traffic Control | Conventional video feeds | Real-time analytics, Enhanced incident detection |
| Agricultural Health Monitoring | Periodic human inspection | Continuous drone surveillance, Instant data analysis |
The industry impact of YOLOv7 extends further into high accuracy applications in various fields such as healthcare, where it assists in early anomaly detection in medical imaging, and environmental monitoring, where detection of minute changes in ecosystems can happen almost instantaneously. This widespread adoption underscores the versatile and scalable nature of YOLOv7, making it a cornerstone in the advancement of industry-specific applications powered by AI and machine learning.
YOLOv7 vs. Unofficial YOLO Versions: A Serious Comparison
In the realm of real-time object detection, the distinction between official and unofficial YOLO versions is crucial for understanding advancements in technology and performance. While all iterations carry the YOLO name, they do not share the same lineage of development, making a YOLOv7 comparison particularly enlightening.
Debunking Myths Around YOLOv5 and YOLOv6
YOLOv5 and YOLOv6, often mentioned in discussions about modern object detection frameworks, are not part of the YOLO series developed by the original creators. These unofficial YOLO versions have contributed useful enhancements in the field but lack the peer-reviewed foundation that YOLOv7 boasts. Unlike its predecessors, YOLOv7 was developed by the original authors, ensuring continuity in innovation and a strict adherence to quality that markedly improves both YOLOv7 predictive performance and YOLOv7 accuracy.
Predictive Performance and Accuracy in the Spotlight
When evaluating object detection platforms, the efficiency of the model under real-world conditions is paramount. YOLOv7 isn’t just part of the official series; it also sets new highs in performance metrics. Compared to its unofficial predecessors, YOLOv7 demonstrates enhanced speed and accuracy, making it the leader in real-time object detection capability. These advancements are not just theoretical – they translate into significant practical gains in applications ranging from autonomous driving to public safety surveillance.
Through a combination of Extended Efficient Layer Aggregation and innovative Model Scaling Techniques, YOLOv7 offers a streamlined architecture that requires less computation and fewer parameters while delivering faster and more accurate detections. These technical enhancements allow YOLOv7 to operate effectively on simpler hardware setups, making it more accessible and cost-effective for a broader range of use cases.
Understanding the gap between the official YOLOv7 and its unofficial counterparts is key for organizations and developers in making informed decisions. In summary, YOLOv7’s verification by its original developers, coupled with its superior architecture, makes it a substantially more reliable and powerful choice in the landscape of real-time object detection technologies.
Implementation and Training of YOLOv7 Models
YOLOv7 has set a new standard in the realm of real-time object detection, emphasizing both innovative model implementation and efficient training approaches. This section delves into the practical aspects of YOLOv7 custom training and the optimized use of the model across different computational environments.
Step-by-Step Guide for Custom Training
The process of custom training a YOLOv7 model is streamlined for accessibility, even for those new to the machine learning domain. YOLOv7's GitHub repository offers comprehensive resources, including PyTorch implementations and Python scripts, facilitating YOLOv7 custom training on diverse datasets. A typical setup involves adjusting the "custom.yaml" file to specify dataset paths, class numbers, and other relevant details. Training can be executed on platforms like Google Colab, which provides free GPU resources, enhancing the learning and development cycle significantly.
Leveraging YOLOv7 for Optimized Object Detection
Engineered for scalability and performance, YOLOv7 leveraging includes deployment across a variety of devices, from edge hardware to robust cloud-based systems. YOLOv7 model variants, such as YOLOv7-tiny and YOLOv7-W6, cater specifically to the needs of different computing environments. This adaptability ensures that users can achieve optimized object detection, whether in low-latency edge devices or high-performance cloud settings.
To illustrate the diversity and capabilities of the YOLOv7 models tailored for specific computational demands, consider the comparative table below:
| Model Variant | Use Case | Optimization Focus |
|---|---|---|
| YOLOv7-tiny | Edge Devices | Low-latency, resource-efficient |
| YOLOv7-W6 | Cloud Computing | High-performance, scalability |
| YOLOv7-E6 | Enterprise solutions | Balance between speed and accuracy |
| YOLOv7-X | Advanced research | State-of-the-art accuracy |
Each model is meticulously designed to meet specific operational requirements, making YOLOv7 a versatile tool in both commercial and research-oriented projects. By choosing the appropriate model version, users can harness the full potential of YOLOv7 for optimized object detection, tailored to their specific scenario.
The Future of Object Detection: Predictions Post YOLOv7
The rapid evolution of YOLOv7 opens new vistas in the realm of object detection future, setting a benchmark for efficiency and integration. With YOLOv7 leading the charge, the trajectory of object detection technologies seems poised for a transformative phase, where more sophisticated systems could become the norm.
Among the exciting prospects is the potential unification of specialized tasks such as instance segmentation and pose estimation into a single holistic framework. This integration hints at a future where YOLOv7 evolution could streamline complex vision tasks into seamless operations, driving the adoption of next-gen sensors and AI processors across diverse fields.
YOLOv7 evolution
The following points elaborate on the projected advancements in the object detection future post-YOLOv7's influence:
- Greater focus on integrated systems that reduce the need for multiple distinct models for different tasks.
- Improvements in real-time processing speeds that could redefine parameters for surveillance and autonomous vehicle navigation.
- Inclusion of more intuitive AI features, which could self-calibrate based on the environmental inputs and detection feedback.
- Expansion of YOLO architecture to embrace wider applications areas including urban planning and managed healthcare systems.
Moreover, the ongoing advancement of edge computing complements the YOLOv7 evolution, by bringing powerful object detection capabilities closer to the real-world applications where instant data processing is crucial. These developments could likely trigger significant shifts not just in technological strategies but also in organizational dynamics within industries.
Summary
The arrival of YOLOv7 has undeniably ushered in a new era for real-time object detection, offering unparalleled performance and efficiency. This model not only surpasses all its predecessors but also dramatically outperforms competing technologies in accuracy and speed, as evidenced by its impressive results on the MS COCO dataset. What is even more remarkable about YOLOv7 is its ability to achieve these groundbreaking results without the need for any pretrained weights, setting a benchmark for leaner, more efficient neural network training.
YOLOv7 signifies more than just an incremental update; it is a testament to the ongoing advancements in computer vision. With the object detection advancements it introduces—processing images in their entirety in one forward pass, touting a balance of speed and accuracy, and offering swift real-time detection capabilities—YOLOv7 stands at the forefront of applicable AI technologies. Moreover, its development journey, from the meticulous code dissection to the creation of a tailored PyTorch dataset, underscores the complexities and triumphs involved in pushing the boundaries of machine learning models.
FAQ
What is YOLOv7 and why is it important for real-time object detection?
YOLOv7 is the latest and most advanced iteration in the YOLO series of object detection models. Its importance lies in its remarkable speed and accuracy, making it well-suited for real-time object detection tasks in various applications such as video analytics, robotics, and autonomous vehicles.
How does YOLOv7 differ from previous YOLO versions and other object detection models?
YOLOv7 stands out due to its utilization of sophisticated features like model re-parameterization, Extended Efficient Layer Aggregation Networks (E-ELAN), and model scaling strategies. These advancements allow YOLOv7 to surpass previous YOLO versions and other object detection models in both speed and accuracy while being more computationally efficient.
What is the YOLO algorithm and how has it evolved over time?
The YOLO (You Only Look Once) algorithm is a method used for object detection that is known for its speed and efficiency. It has undergone various improvements since its inception, with each version bringing enhanced performance and features. YOLOv7 is the latest official version, continuing the YOLO legacy with significant strides in technological advancement.
Can YOLOv7 be used on different hardware platforms?
Yes, YOLOv7 is designed with a flexible architecture that can be deployed on various hardware platforms. It features different versions optimized for specific computational environments, like YOLOv7-tiny for edge devices and YOLOv7-W6 for cloud-based applications, ensuring adaptability across a range of hardware setups.
How does YOLOv7's performance compare to unofficial versions like YOLOv5 and YOLOv6?
YOLOv7 outperforms unofficial versions such as YOLOv5 and YOLOv6 in both speed and accuracy. While unofficial models have been useful, YOLOv7 is the authentic continuation of the YOLO series released by the original authors and has gone through rigorous peer-reviewed research to ensure top-notch performance.
What industries can benefit from YOLOv7?
Various industries can benefit from YOLOv7, including public safety, transportation, and smart city initiatives. Its real-time object detection capabilities are instrumental in applications like crowd and person detection, improving safety and operational efficiency in these sectors.
Is YOLOv7 suitable for custom object detection tasks, and how can it be trained?
YOLOv7 is well-suited for custom object detection tasks. It can be trained on diverse datasets, and with detailed guides and open-source codebases available, it is accessible to machine learning practitioners at various levels of expertise. Platforms like Google Colab can also be used to facilitate training with GPU resources.
What kind of technological advancements does YOLOv7 incorporate?
YOLOv7 incorporates a range of technological advancements, including planned re-parameterized convolution, compound scaling methods, and an array of techniques such as group convolution and channel shuffling. This blend of features ensures an optimal architecture that scales efficiently while maintaining robustness.
What are the predictions for the future of object detection following the release of YOLOv7?
The release of YOLOv7 has sparked discussions about the future of object detection, with expectations leaning towards more integrated and multifunctional systems. There is anticipation that future YOLO models could unify tasks like instance segmentation and pose estimation, further enhancing their utility in computer vision.