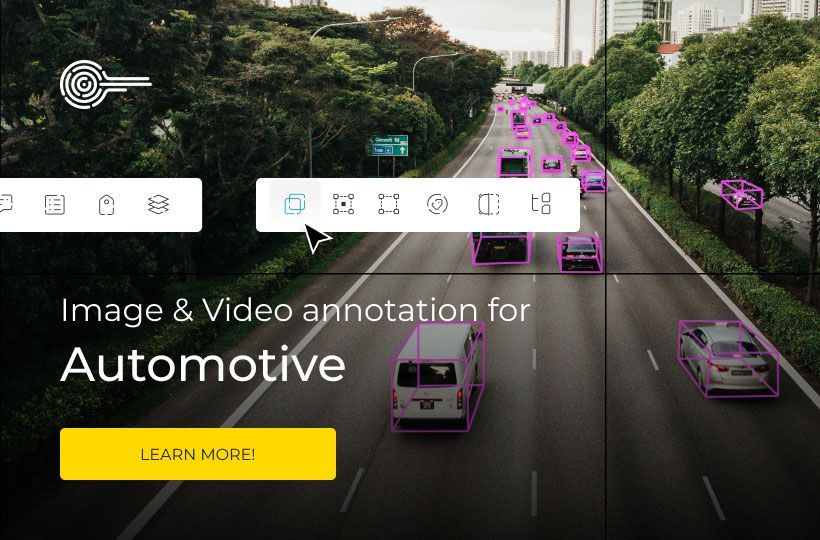
Active learning to reduce data annotation costs
Traditional data preparation approaches for AI systems manually label thousands of examples, wasting resources on irrelevant information. Modern solutions allow machine intelligence to guide the human experience, enabling cost reduction and annotation efficiency.
Modern methods show how intelligent systems identify essential data points for manual review. This creates a cycle of continuous improvement, where each labeled example improves the accuracy of the AI model. The result is rapid deployment cycles and robust frameworks that adapt to various industries, from driver monitoring systems to medical imaging analysis.
Quick Take
- Strategic data selection reduces labeling costs.
- AI-based annotations create self-improving systems.
- Reusable frameworks enable rapid adaptation across industries.
- Combining algorithmic precision with human supervision improves AI model performance.

Active Learning Annotation
Active learning annotation is a data labeling process where an AI model selects the most informative examples for annotation, improving training data optimization and overall ML algorithms performance. Unlike traditional approaches, the system identifies those examples that will have the most significant impact on improving its accuracy. Annotators only work with selected examples, which reduces time and resource consumption. This approach is helpful in areas where data is expensive or difficult to label, such as medical imaging, autonomous transportation systems, or financial analysis.
An iterative process of AI model improvement
Start with a base AI model trained on a curated dataset. The system then evaluates unlabeled content and labels examples where predictions show uncertainty. These data points are prioritized for human review, creating a feedback loop that enhances machine learning optimization and ensures an effective annotation strategy.
Three phases define this progression:
Setting Up an Active Learning Pipeline on AWS
Cloud infrastructure is the foundation of modern data processing workflows as you scale intelligent systems. Our AWS implementation combines six core services into a cohesive architecture that adapts to changing needs while maintaining tight cost control.
Overview of AWS Services and Tools
Using SageMaker Ground Truth and automated workflows enables annotation strategy implementation that balances human supervision with AI-driven training data optimization. To build a secure infrastructure, AWS uses services such as AWS Identity and Access Management and AWS Shield to protect against DDoS attacks. The ecosystem also includes DevOps tools, including AWS CodePipeline and CloudFormation, which automate CI/CD and infrastructure management as code. With its broad integration and scalability, AWS is a universal platform for any business.
Three layers define a workflow:
- Orchestration. CodePipeline automates the transitions between data processing stages.
- Processing. Lambda functions handle format conversions and quality checks.
- Human input. SageMaker Ground Truth manages markup tasks with front-end work.
Using AWS CDK for modular deployment
The AWS Cloud Development Kit allows teams to convert infrastructure into reusable code components. This will enable them to deploy similar environments across development, test, and production with a single command.
Key CDK constructs include:
- Auto-scaling training clusters that adjust based on the size of the dataset.
- Pre-configured IAM roles that provide access to data across services.
- Template-based S3 buckets for cost management.
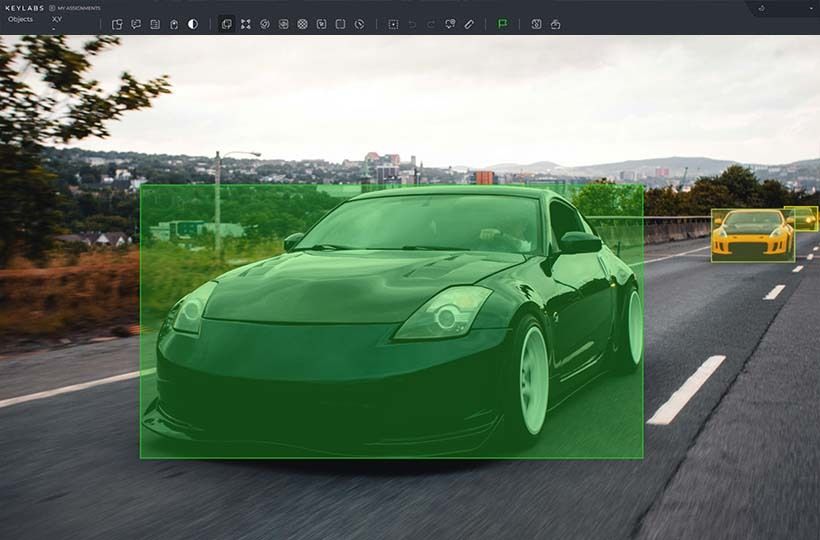
Automating Image Annotation with Machine Learning
Through intelligent automation, computer vision systems now have human-level accuracy. Keylabs platform combines specialized neural networks with validation protocols to create custom, production-ready labeling solutions.
Head Bounding Box Annotation Methods
Head bounding box annotation methods are used to determine the position and dimensions of a person's or object's head in an image to train computer vision models. A popular approach is bounding box annotation, where a rectangular box is drawn around the head that encompasses the entire object. In some cases, a tight bounding box is used close to the head's contours, reducing the amount of background information. Another method uses angular coordinates, where the annotation fixes the location of the box's upper left and lower right corners. Semi-automatic tools are used for tasks requiring greater accuracy, where an algorithm creates the box and an annotator adjusts it. Video streams use tracking methods that allow you to extend the frame to successive frames, reducing manual labeling time.
Keypoint detection methodology
The keypoint detection methodology in computer vision combines deep neural networks and accurate regression algorithms that allow you to find anatomical or structural landmarks in the image automatically. Convolutional neural networks and their extensions preserve global and local details. Heatmap-based methods are used for accuracy, where the model predicts a probability map for each keypoint instead of direct regression of coordinates. Multi-scale feature extraction and attention mechanisms are also used, considering different spatial information levels and focusing on relevant areas. Keypoint detection is used for motion tracking, medical diagnostics, emotion recognition, and AR/VR systems, making this methodology a key in modern computer vision.
Integrating human expertise into automated annotation
Automated systems quickly process large amounts of data, but errors occur, especially in complex or ambiguous cases. Human experts add context, correctly interpret specific objects, and provide high-quality examples for training AI models. This approach is implemented through human-in-the-loop, where the algorithm performs pre-labeling and the annotator checks and corrects the results. Also, experienced annotators form standards that help algorithms work consistently. This ensures data quality for training AI models in medicine, autonomous transportation, and financial monitoring.
Cross-domain adaptation strategies
Cross-domain adaptation strategies aim to work with new datasets that are different from those on which they were trained. The main problem is domain shift, when the statistical characteristics of the source and target domains do not match, which leads to a decrease in accuracy. Different approaches are used to overcome this:
- Feature-based methods reconcile the feature space using normalization techniques or shared latent representations.
- Adversarial training uses generative adversarial networks that train the model to ignore domain differences.
- Instance-based strategies select examples from the source set relevant to the target environment.
- Self-supervised and semi-supervised approaches involve small amounts of labeled data in the target domain.
Such strategies are important in industries where data collection is expensive or limited, such as medicine, autonomous transportation, or industrial automation, because they ensure the stability of models and performance in real-world conditions.
FAQ
How does active learning reduce the cost of data labeling?
The model automatically selects informative examples, leading to cost reduction and improved annotation efficiency..
How do you maintain the quality of labels in scaled deployments?
Quality is maintained through multi-level controls, clear annotation guidelines, and automated consistency checks.
Which industries benefit?
The pipeline is adaptable to medical imaging analysis, retail customer behavior tracking, and industrial quality control.
How does human supervision improve model performance?
Annotators detect and correct errors in the data or predictions that the algorithm might misinterpret. This ensures accuracy, reduces the risk of bias, and makes the system robust in real-world scenarios.