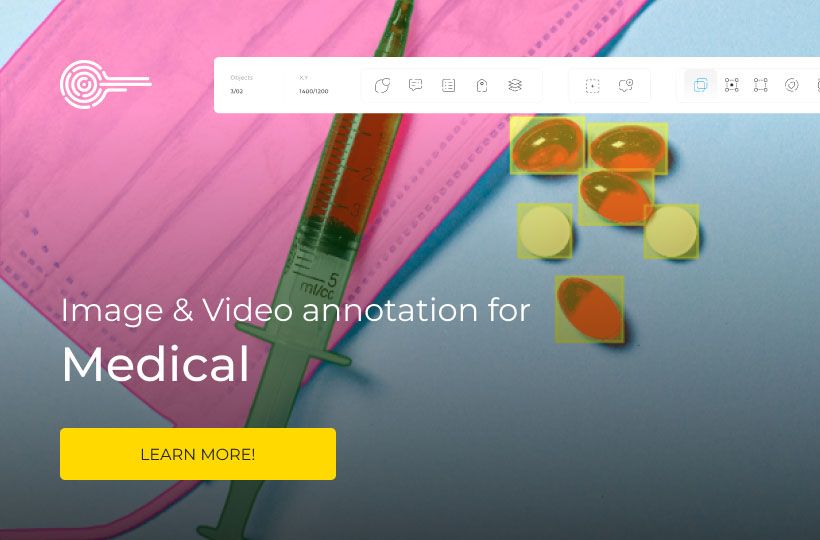
HIPAA-compliant data annotation: health data labeling standards
Hospitals, research institutions, and AI developers need annotated datasets to train machine learning models for diagnostics, treatment planning, and predictive analytics. However, working with health information comes with strict responsibilities: patient privacy and regulatory compliance are paramount.
The Health Insurance Portability and Accountability Act (HIPAA) sets standards for protecting personal health information (PHI), and these HIPAA requirements guide all aspects of health data labeling and annotation. For organizations engaged in data annotation, understanding and implementing HIPAA-compliant practices is essential to protecting sensitive health information and supporting AI development.
Key Takeaways
- Security and privacy measures should be part of every annotation workflow.
- Structured standard operating procedures and governance improve model performance and audit readiness.
- Adopt an approach that involves collecting only the information needed, annotating early, and controlling access.

HIPAA key provisions for labeling health information
HIPAA establishes standards for protecting the privacy, security, and exchange of health information that are important to health care organizations and providers. Proper labeling and classification of data is key to ensuring patient protection and regulatory compliance. Key provisions include:
- Definition of personally identifiable information (PHI). PHI includes any information about a patient’s health, health care services provided, or payment for those services that can identify an individual.
- Required encryption and access control. Data containing PHI must be protected from unauthorized access through encryption and access controls.
- Minimum necessary rule. When processing or sharing data, access is granted only to the extent necessary to perform a specific task.
- Auditing and access tracking requirements. Organizations must maintain a log of PHI access, including the date, time, and user.
- Anonymization and deidentification of data. If data is used for research or analytics, it must be anonymized or de-identified in accordance with HIPAA standards.
- Must provide notice of restrictions on use and disclosure. PHI may not be used or disclosed without the patient’s express consent, except as required by law.
- Physical and electronic storage policies. PHI must be stored in a secure environment, whether on physical media or in electronic databases.
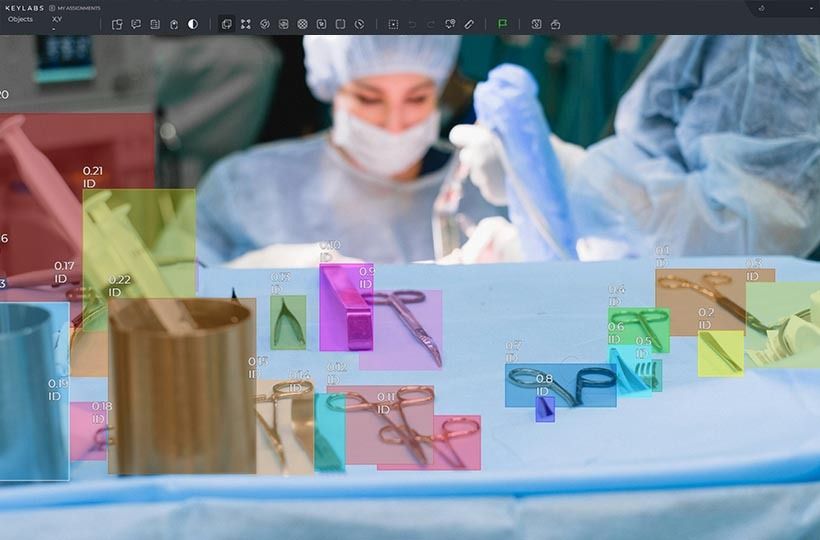
HIPAA-compliant medical data annotation
Health insurance portability and accountability act (HIPAA) - compliant medical data annotation involves a structured workflow that protects patients’ personal health information using privacy preserving annotation techniques that ensure sensitive information is not exposed during labeling or model training. Because medical datasets contain sensitive information, organizations must implement specific procedures for de-identification, access control, and auditing. This approach allows medical data to be used for technological and scientific purposes without violating confidentiality requirements.
De-identification and privacy-enhancing methods
Medical datasets contain sensitive patient information, so privacy must be protected before they are used to train models. The goal of de-identification is to remove or transform data elements that can identify an individual while preserving the analytical value of the information.
Various de-identification methods are used during development to reduce the risk of patient re-identification and ensure the safe use of data for research and technological solutions.
Tools, formats, and workflows adapted to medical data
Keymakr specializes in creating high-quality, annotated medical data for artificial intelligence, particularly for computer vision in medicine (X-ray, CT, MRI, ultrasound, histology, surgical videos, etc.).
The most important aspect of the work is the creation of accurate, structured datasets that meet the requirements of quality, security, and analytical value for AI systems.
Keymakr’s main tools, data formats, and workflows for medical applications:
FAQ
What are the key requirements for HIPAA-compliant data labeling in healthcare AI projects?
All health data should be de-identified or anonymized, labeled with accurate, standardized categories, and protected with access controls and auditing to ensure that patient personal information is protected in accordance with HIPAA.
What PHI elements commonly appear in annotation tasks?
Patient name, date of birth, medical ID numbers, address, contact information, and medical history are common in health data annotation tasks.
How do role-based access and audit trails mitigate risks during labeling?
They limit the use of health data to authorized users only and log all actions, which reduces the risk of unauthorized access or information leakage during labeling.
What encryption methods are recommended for protecting ePHI in projects?
To protect ePHI, projects recommend using modern encryption standards such as AES-256 for storage and TLS 1.2/1.3 for transmission.
What methods protect images and videos from human review?
Images and videos are protected from human review by methods such as de-identification, pseudonymization, masking of sensitive areas, and data encryption.