How to Validate Synthetic Data for Model Training
Synthetic data has opened a new era in AI development, allowing teams to bypass real-world information shortages and create datasets of any scale. However, the haphazard use of generated samples without strict verification turns this advantage into a hidden threat to a project. The main problem is that synthetics are merely a mathematical copy of reality. If the generator makes even a minor mistake or fails to account for the complex relationships of the real world, the model will start learning a distorted logic that has nothing to do with reality.
Training on unverified data often leads to an "echo-chamber" effect, where the model gradually loses the ability to see real-world nuances and becomes locked into repeating the generator's idealized patterns. This creates an illusion of high accuracy in the laboratory, which instantly shatters when encountering the unpredictability of real life. Furthermore, synthetics can contain logical errors or reinforce hidden stereotypes, making the AI system biased or unstable.
This is why validation becomes a mandatory filter that confirms the generated content truly carries educational value. It is a strategic process of checking whether the generated data complies with the laws of physics and common sense. Without proper quality control, developers risk wasting resources on training an algorithm that demonstrates flawless results in a simulation but proves completely helpless in real situations.
Quick Take
- Without validation, the model trains on a simplified mathematical copy, which can lead to its failure in real-world conditions.
- Without diversity control, the model will ignore real nuances and lock itself into the generator's templates.
- A visually beautiful frame with incorrect shadows or a lack of gravity will teach the neural network false features.
- Continuous validation is the only way to notice the "degradation" of the generator after updates in time.
- Auto-labeling of synthetics often has systemic biases that must be corrected through manual review.

Application Areas for Synthetic Data
Each industry has its unique challenges when collecting real information; therefore, approaches to creating and verifying synthetics differ significantly depending on whether we are working with images, text, or complex simulations.
Computer Vision and Autonomous Systems
In the field of CV, synthetic data helps solve the problem of a shortage of rare frames. For self-driving cars or drones, entire virtual worlds are created where accidents, difficult weather conditions, or unpredictable pedestrian behavior can be safely modeled. This allows the system to be trained to react to moments that occur once every thousand kilometers in real life.
The key here is the synthetic-real validation method, where developers check whether the model perceives a synthetic tree or car in the same way as a real one. If virtual objects are too perfect, a domain gap arises, and the model may fail to recognize a real dirty car on the road. Therefore, in a CV, data is often intentionally "spoiled" with digital noise and varying lighting for greater realism.
Large Language Models
For training language models, synthetics are used to improve the logic and quality of responses. When there are insufficient real texts on a specific narrow topic, stronger models generate training examples for weaker models. This helps expand the system's knowledge in mathematics, programming, or specific linguistic dialects.
It is important to perform distribution matching to ensure the artificial text hasn't become too repetitive. If a model learns from texts where the same phrases are constantly repeated, its own language will become poor and uninteresting.
Medicine and Privacy
In medicine, synthetic data is perhaps the only way to train neural networks without violating privacy laws. Instead of using real patient records or test results, algorithms create "digital twins." These are artificial medical histories that statistically copy real diagnoses entirely but do not belong to any living person.
The main task here is to ensure that quality metrics that confirm medical patterns in the synthetics are preserved correctly. If an artificial X-ray contains a pathology that is impossible from an anatomical standpoint, the model will learn a false sign of a disease. Therefore, validation in medicine often includes checks by doctors who must confirm that the synthetic cases look clinically plausible.
Validation Assessment Criteria
For synthetics to be beneficial, they must pass through technical and logical checks. This guarantees that the model isn't just memorizing digital patterns but truly understands the "rules of the game" by which the world operates.
Consistency with Real Data
The primary task of this stage is distribution matching – confirming that the artificial dataset is not oversimplified. It is important to check not only average indicators but also edge cases. If a real dataset contains rare scenarios, such as black ice or sun glare, the synthetic set must also have these conditions in the correct proportion.
For this, domain gap analysis is conducted, measuring the "distance" between the two data arrays. If the mathematical difference between them is too large, the model may fail real-world tasks after training on synthetics. Object behavior analysis helps identify anomalies: whether pedestrians move too linearly or if chat-bot conversations are too formal compared to living speech.
The next level of verification concerns the logic of scene construction. Even if an image looks bright, it may contain physical errors that confuse the neural network. Checking quality metrics includes an analysis of realism: whether shadows fall correctly, whether reflections on glass correspond to the environment, and whether there are objects passing through one another.
Semantic quality is responsible for context. For example, if we are generating a night city scene, streetlights should be on, and lights should appear in building windows. In the case of text, this means the absence of "hallucinations" where the model invents facts that never existed. Such visual and logical purity ensures that the AI will learn useful patterns.
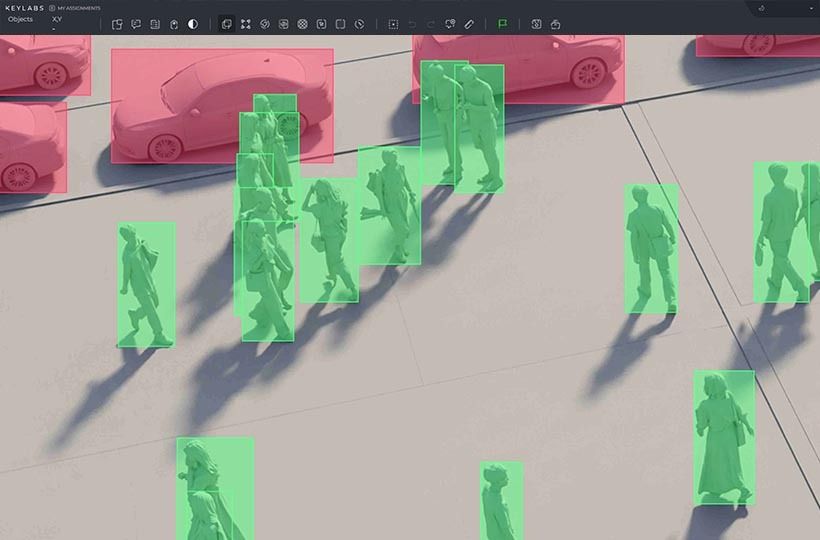
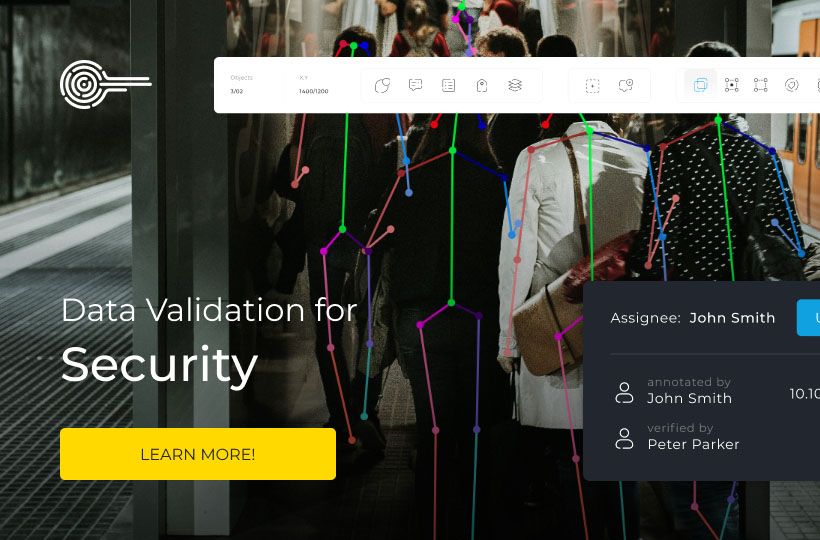
Annotation and Ground Truth Verification
Since synthetic data is usually generated along with ready-made labeling, there is a risk of systemic biases in the annotation process itself. Therefore, verifying ground truth is vital for training accuracy.
To ensure reliability, selective manual checks by experts or comparisons with results from other independent algorithms are used. If the labeling in the synthetics has a constant error, the model will get used to this mistake and demonstrate low accuracy on real objects where labeling is performed manually and more tightly.
Measuring Success with Production Implementation
For synthetic data to benefit the model, its verification process must be a clear system with mathematical metrics and automated pipelines.
Automated Test Metrics
The assessment of synthetic quality is based on comparing its properties with the real world using specific numerical indicators. Instead of subjective evaluation, engineers use a set of mathematical tools:
- Fréchet Inception Distance is the primary metric for computer vision. It compares feature vectors of real and artificial images. The lower the FID score, the closer the synthetics are to real photos in structure and quality.
- KL Divergence is a metric used to analyze numerical data and probabilities. It shows how much the distribution of features in the synthetics deviates from the real dataset.
- Coverage is a metric that checks the diversity of generated data. It answers whether all possible variations of objects, angles, and scenarios were created.
In addition to statistical methods, automation includes technical error checks:
- Error Rates. Automated search for systemic defects in labeling, such as empty boxes or incorrectly assigned classes.
- Consistency Checks. Control of logic over time. For example, the system checks that a car does not change color while moving in a single video frame or that a pedestrian does not walk through walls.
- Physically-based validation. Verifying compliance with the laws of physics regarding shadows, lighting, and gravity.
The Continuous Validation Process
Quality verification cannot be completed at the data creation stage. It must become a permanent part of the data pipeline, as models and their tasks constantly change. Every new batch of synthetic data should automatically pass through a system of tests before entering the training set.
Continuous validation allows for the timely detection of generator "degradation" or data shifts. This creates a closed-loop training cycle where the model provides feedback to the generator: if the neural network frequently makes mistakes on certain artificial scenarios, the validation system marks them as questionable and sends them for refinement.
Practical Examples from the Industry
Synthetic data has already become standard in the most technologically advanced industries, where a model error can be very costly:
- Autonomous driving. Companies use simulators to create millions of kilometers of virtual roads. Validation here focuses on the physics of movement and object recognition in critical conditions, such as blinding headlights from oncoming cars.
- Robotics. Robots are trained to manipulate objects in virtual space. Here, they check whether the virtual forces of friction and gravity match the real ones so that the robot does not drop the object in a real workshop.
- Medical imaging. Creating artificial MRI images for rare diseases allows you to train diagnostic models without waiting for real patients with such diagnoses. The key is to validate the annotations by experienced doctors.
- Simulation-based training. Training operators of complex equipment or pilots is based on scenarios that cannot be reproduced in real life due to the high risk. Here, the semantic logic of interactions is validated so that the experience gained in the simulator is suitable for reality.
FAQ
How can synthetic data cause model "poisoning"?
If a generator constantly creates objects with a barely noticeable technical artifact, the model may learn to recognize objects by this digital "signature" rather than their real features. Validation via FID helps detect such discrepancies early.
How does the use of synthetics affect the model's ability to generalize?
Using only perfect synthetics narrows the model's horizons, making it vulnerable to noise. To improve generalization, "digital dirt" is deliberately added to the data during validation: blur, interference, and lighting variations. This forces the algorithm to look for essential features of objects, rather than relying on a perfect image.
What is the role of Adversarial Validation?
This is a test where you train a separate classifier model to distinguish synthetic data from real data. If the classifier succeeds easily, your domain gap is too large. Ideal synthetics are those that another neural network cannot distinguish from reality with high confidence.
Are there risks of copyright or intellectual property infringement when generating synthetics?
Yes, if the generator was trained on copyrighted data, it may accidentally reproduce recognizable elements of the original in synthetic samples. The validation process in an LLM or CV should include plagiarism and uniqueness checks to ensure that the generated content is the original product of the mathematical model and not a copy of someone else's work.
How to validate synthetic data for resource-constrained edge devices?
For such cases, validation shifts towards checking information density. It is important to ensure that the synthetics are not overloaded with unnecessary details that the model on the Edge device will not be able to process anyway due to architectural limitations. Validation helps to select only those samples that best train the lightweight model on the underlying features.