Hybrid Datasets: Blending Real and Synthetic Data for Optimal Performance
In recent years, the search for more efficient and effective data-driven decisions has led to exploring innovative approaches combining different data sources. Hybrid datasets have emerged as a compelling strategy to overcome the limitations faced when relying solely on real data or fully synthetic data. The interplay between real and synthetic data opens up new ways to overcome challenges such as data scarcity, privacy concerns, and the need for diverse training scenarios.
The attractiveness of hybrid datasets lies in their ability to increase the volume of data and their potential to enrich the information landscape from which machine learning models draw. Real data, with its authentic nuances, provides the foundation for realistic performance, while synthetic data provides the flexibility and control to fill gaps and simulate rare events. The growing interest in hybrid approaches reflects a broader realization that no single data source can meet all needs in isolation.

The Evolution of Challenges in AI Training
The journey of learning AI is marked by a constant evolution of challenges reflecting the growing complexity of the technology and its applications. Early efforts focused primarily on collecting sufficient data and building basic models that could be learned from examples. As AI systems have evolved, the focus has shifted to improving data quality, removing biases, and ensuring that models can generalize well beyond their training environment. With the development of deep learning and more complex architectures, new obstacles have emerged regarding AI solutions' computational requirements, interpretability, and ethical implications.
Along with these technical and ethical challenges, practical constraints have significantly shaped AI training strategies. Data privacy regulations and the increasing difficulty of obtaining diverse, representative datasets have complicated efforts to build reliable models. At the same time, the need for AI systems to operate reliably in dynamic real-world environments has prompted researchers to look for innovative ways to model and predict a wide range of scenarios.
Traditional vs. Algorithmic Generation
Traditional methods of data generation have long relied on collecting information from the real world through direct observation, surveys, or manual labeling, emphasizing authenticity and accuracy. These approaches focus on capturing the natural variations and complex patterns inherent in real-world environments, which are often difficult to reproduce artificially. However, traditional methods can be time-consuming, expensive, and limited by data availability, especially in rare events or sensitive information scenarios.
In contrast, algorithmic generation uses computational methods to create synthetic data miming real data sets' statistical properties and structural patterns. This method allows for rapidly creating large volumes of data with controlled variability, allowing for modeling scenarios that may be rare or otherwise unavailable in practice. Algorithmic generation offers greater flexibility, allowing practitioners to customize datasets to meet specific training needs or augment existing data with targeted examples. However, synthetic data must be carefully validated to avoid introducing artifacts or biases that could mislead models.
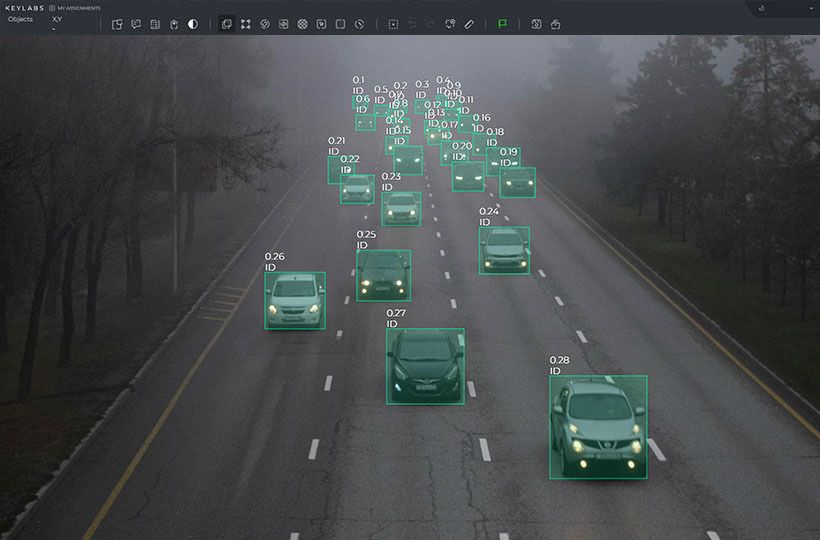
How Combining Synthetic + Real Data Enhances Model Performance
Real data offers the true complexity and authentic variation that anchors models in reality, but it can be scarce, expensive, or limited in scope. On the other hand, synthetic data can be generated in large quantities and tailored to cover specific cases or rare scenarios that real data may miss. These datasets provide a more prosperous and diverse training environment, allowing models to learn realistic and comprehensive patterns.
The interaction between synthetic and real data allows for more efficient experimentation and fine-tuning. Synthetic data can be generated quickly and at a large scale, which supports thorough testing of model behavior in various settings without the constraints of collecting new real-world data. This iterative process helps refine models, ensuring that they remain grounded in patterns while benefiting from the expanded coverage provided by synthetic data.
Combining synthetic and real-world data can improve accuracy and reliability and address practical concerns such as data privacy and bias reduction. Synthetic data can be generated without disclosing sensitive information, making it a valuable tool in regulated industries or situations requiring anonymization.
Closing the Uncommon Scenario Gap
Many traditional datasets have difficulty capturing rare or marginal cases, which can lead to model failures when they encounter unexpected inputs or unusual conditions. These unusual scenarios are often tricky and expensive to collect through real-world data, leaving significant training processing gaps. By including synthetic data designed to represent these rare events, developers can enrich datasets with examples that might otherwise be missing.
Closing the gap in unusual scenarios improves model robustness and increases safety and reliability, especially in high-value applications such as autonomous driving, healthcare, or security systems. When AI systems are exposed to a broader range of scenarios during training, they become better prepared to recognize and handle anomalies or unexpected behavior. Additionally, simulating rare conditions allows for thorough testing before deployment, which is often impossible with purely real-world data.
Rather than relying solely on random encounters in the real world, the intentional inclusion of rare cases through synthetic generation ensures that models understand their operational context fully. This approach promotes continuous improvement and adaptation, allowing AI to evolve with the complexity of the environments it serves.
Optimizing Resource Allocation
- Effective resource allocation starts with determining which parts of the data pipeline benefit most from real data and which can be supplemented with synthetic data, balancing cost and quality.
- Using synthetic data to create large volumes of training examples reduces the need for expensive and time-consuming data collection efforts, freeing up budget and human resources for other tasks.
- Real data should be prioritized for critical validation and fine-tuning steps to ensure that models remain based on authentic, high-quality examples that reflect real-world environmental conditions.
- By automating synthetic data generation, organizations can accelerate cycles of experimentation and iteration without proportionately increasing computing or human resources.
- Strategically combining real and synthetic data helps avoid over-reliance on any source, optimizing both financial investment and model performance results.
The Role of Synthetic Data in ADAS, Edge AI, and Manufacturing
Synthetic data is playing a key role in developing technologies such as ADAS (Advanced Driver-Assistance Systems), Edge AI, and manufacturing, addressing the unique challenges these industries face regarding data availability and diversity. In ADAS, synthetic data allows for modeling complex driving scenarios, including rare and dangerous situations that are difficult or dangerous to capture in real life. This helps improve autonomous vehicles' safety and reliability by exposing models to a broader range of conditions. For Edge AI, where computational resources and real-time processing constraints are critical, synthetic data allows for efficient training of lightweight models that perform well despite limited real-world data.
In manufacturing, synthetic data supports the development of AI systems that monitor and optimize production processes by simulating rare faults or variations not often observed on the factory floor. This capability helps reduce downtime and improves predictive maintenance strategies. In addition, synthetic data helps to maintain confidentiality, especially in industries where sharing real production data can pose security risks. In these areas, the ability to tailor synthetic datasets to specific operational requirements accelerates innovation and adoption while reducing the risks associated with data scarcity and sensitivity.
Solving ADAS Development Roadblocks
One of the main challenges is obtaining enough high-quality data that covers a wide range of driving conditions, including rare and dangerous scenarios that are difficult to capture in real-world testing. By integrating synthetic data generation, developers can simulate these edge cases, accelerating model training without compromising safety. In addition, robust validation systems that combine real and synthetic data help ensure that ADAS algorithms work reliably before deployment.
Another significant obstacle in ADAS development is the computational and latency limitations of deploying AI models in real-time in vehicles. Optimizing algorithms to run efficiently on embedded systems while maintaining high accuracy is critical. Synthetic data can help this process by providing training focused on specific problems, such as sensor noise or lighting conditions. Such targeted training improves the model's robustness in real-world conditions without requiring exhaustive data collection.
Meeting stringent safety standards requires rigorous testing in various scenarios and conditions, some of which may be impractical or dangerous to test physically. Combined with transparent reporting and validation methods, this approach helps demonstrate compliance and build trust with regulators and consumers.
Computer Vision Transforms Manufacturing
Computer vision transforms manufacturing by enabling greater automation, accuracy, and efficiency across all production lines. Advanced visualization and AI-powered analysis allow machines to inspect products in real-time, identifying defects or inconsistencies that human operators might miss. In addition, computer vision systems can monitor the condition of equipment and predict maintenance needs, preventing unexpected failures that disrupt operations.
In addition to quality assurance, computer vision supports increased flexibility in production processes by enabling adaptive control and customization. Vision-controlled robotics can adjust their actions based on continuous visual feedback, allowing them to handle different types of products or change assembly requirements without significant reprogramming. In addition, integrating computer vision with other data sources creates a comprehensive view of the manufacturing environment, enabling more intelligent decision-making and optimizing workflows.
The impact of computer vision also extends to worker safety and operational transparency. Vision systems can monitor dangerous areas, warn personnel, or automatically stop equipment to prevent accidents. They also support ergonomic assessments and process optimization by analyzing human movements and identifying inefficiencies. Data collected with these technologies
Integrating Synthetic Data into Machine Learning Workflows
Integration begins with identifying gaps or limitations in existing datasets, such as insufficient coverage of rare cases or unbalanced classes, where synthetic data can provide a meaningful addition. Synthetic data is then generated using techniques such as simulation, procedural modeling, or generative algorithms designed to capture real-world data's statistical properties and variability. Incorporating this data into the training pipeline helps expand the input data's diversity and volume, improving the model's ability to generalize and perform effectively in a broader range of scenarios.
The workflow also requires balancing real and synthetic data to optimize learning outcomes. Over-reliance on synthetic data risks moving away from authentic patterns, while too little use can limit the potential benefits. Strategies such as weighted sampling, incremental learning, or domain adaptation techniques can help maintain this balance, allowing models to take advantage of both data types. Additionally, synthetic data can speed up experimentation by rapidly generating customized datasets to test specific hypotheses or tune model parameters.
Methods for Blending Simulation With Real-World Data
- Data augmentation. One standard method involves simulations to create additional training examples that complement real-world data, especially for underrepresented scenarios. This helps to increase the diversity of datasets without the need for large-scale collection of real data. The simulated data can be modified with lighting, angles, or noise variations to more accurately mimic real-world conditions.
- Domain adaptation. Another effective method focuses on matching the statistical characteristics of the modeled data with those of the real data to reduce the "reality gap". Methods such as adversarial learning or feature space transformation help models learn representations that work well in both domains. This combination ensures that the knowledge gained from modeling is seamlessly transferred to practical, real-world applications. Domain adaptation reduces discrepancies and increases robustness when deploying models partially trained on synthetic data.
- Hybrid learning pipelines. A more integrated approach combines modeling and real-world data throughout the learning process. Models can first be pre-trained on large amounts of simulated data to learn general patterns and then fine-tuned with real data to improve accuracy. This stepwise combination leverages the scalability of modeling while anchoring the model in real-world conditions.
- Scenario-based modeling. This method aims to generate synthetic data that fills specific gaps in real-world data sets, such as rare or dangerous events. By carefully designing scenarios in simulation environments, developers create targeted datasets that account for critical edge cases. These targeted synthetic samples are blended with real-world data to improve coverage and resilience.
- Data fusion techniques. Advanced blending can also combine features or outputs obtained separately from simulated and real data sources. For example, sensor data collected in the real world can be combined with modeled sensor readings to create richer input for machine learning models. Combining the data, feature, or decision level allows you to leverage the complementary strengths of both data types.
Fine-Tuning Models and Domain Adaptation Strategies
Fine-tuning models and domain-specific adaptation strategies are crucial for improving machine learning performance when applying pre-trained models to new, often slightly different, real-world environments. Fine-tuning involves taking a model that has already learned general features from a large dataset-often synthetic or a different subject area, then continuing to train it on a smaller, more specific dataset that closely resembles the target application.
Subject matter adaptation complements fine-tuning by addressing the issues that arise when the source data (such as synthetic or modeled data) differs significantly from the target real-world data. These differences, called domain offsets, can degrade model performance if left unaddressed. Domain adaptation strategies include feature alignment techniques, which transform the data representation to minimize the differences between the source and target domains, and adversarial learning techniques, where the model is trained to be invariant to domain-specific features.
Summary
Hybrid datasets, which combine real and synthetic data, offer a powerful approach to overcoming the limitations of relying on a single data source. Combining the authenticity and complexity of real data with the flexibility and scalability of synthetic data improves model training, robustness, and generalizability across different scenarios. It addresses issues such as data scarcity, privacy concerns, and the need to cover rare or dangerous cases that are difficult to capture. Integrating these data types through careful techniques such as augmentation, domain adaptation, and hybrid learning pipelines optimizes resource utilization and model performance. The thoughtful combination of real and synthetic data is shaping the future of AI development, enabling more reliable, efficient, and adaptive systems.
FAQ
What are hybrid datasets in AI?
Hybrid datasets combine real-world data with synthetic data to leverage both strengths, improving model training and performance.
Why is synthetic data important in machine learning?
Synthetic data helps fill gaps in real data, especially for rare or sensitive scenarios and allows for scalable, controlled data generation.
How does blending real and synthetic data improve model robustness?
It increases dataset diversity and exposes models to a broader range of scenarios, helping them better generalize unseen data.
What challenges does synthetic data help address in ADAS development?
It enables the simulation of rare and dangerous driving conditions that are hard to capture in real life, enhancing safety and testing.
How does domain adaptation support the use of synthetic data?
Domain adaptation techniques align synthetic data features with real-world data, reducing the reality gap and improving model transferability.
What role does fine-tuning play in hybrid dataset workflows?
Fine-tuning adjusts pre-trained models on real data to better fit specific target environments, improving accuracy and relevance.
What methods are commonly used to blend simulation with real data?
Standard methods include data augmentation, domain adaptation, hybrid training pipelines, scenario-based simulation, and data fusion techniques.
How does combining synthetic and real data optimize resource allocation?
It reduces dependence on costly real data collection by supplementing with synthetic data, speeding up training and experimentation.
Why is addressing uncommon scenarios critical in AI training?
Uncommon scenarios are often underrepresented in real data but crucial for safety and reliability; synthetic data helps fill this gap to improve model resilience.