Identifying and Annotating Rare Edge Cases to Improve Model Robustness
Carefully annotating rare cases can ensure the reliability of an AI model. Edge identification and annotation strategies help tune an AI model's accuracy and reliability, which is needed in autonomous driving, medical diagnostics, and financial forecasting.
Quick Take
- Identifying and annotating rare edge cases improves AI model performance.
- Domains such as autonomous driving and medical diagnostics benefit from robust AI models.
- Edge cases include low-light conditions, closed objects, and unusual angles.
- Improving AI model predictions by managing edge cases increases the capabilities of AI for interpretation.

Understanding Edge Cases in Machine Learning
An edge case in machine learning is a rare situation or data on the edge or outside the range on which an AI model was trained. They often belong to a long-tailed distribution, representing rare and atypical cases that differ significantly from the bulk of the data.
Edge cases are important in machine learning. They are used to test and evaluate models because they help identify weaknesses in an algorithm and improve its reliability. Training an AI model on various data, including edge cases, makes it more resilient to unpredictable real-world situations.
The Role of Edge Case Curation
Edge Case Curation is identifying, collecting, and processing edge cases in machine learning datasets. This process aims to train a model on rare or atypical examples, which can improve its robustness and accuracy.
Benefits of Curation
Identifying Edge Cases
Edge case identification identifies rare or complex examples in data sets that lead to machine learning model errors.
Edge cases are identified by:
- Analysis of failed AI model predictions reveals situations with incorrect responses.
- Anomaly analysis is performed using algorithms that detect anomalous data patterns.
- Visualization shows groups of data that differ from the bulk.
- Uncertainty metrics provide a score to identify examples with low confidence.
- Human expertise verifies complex cases.
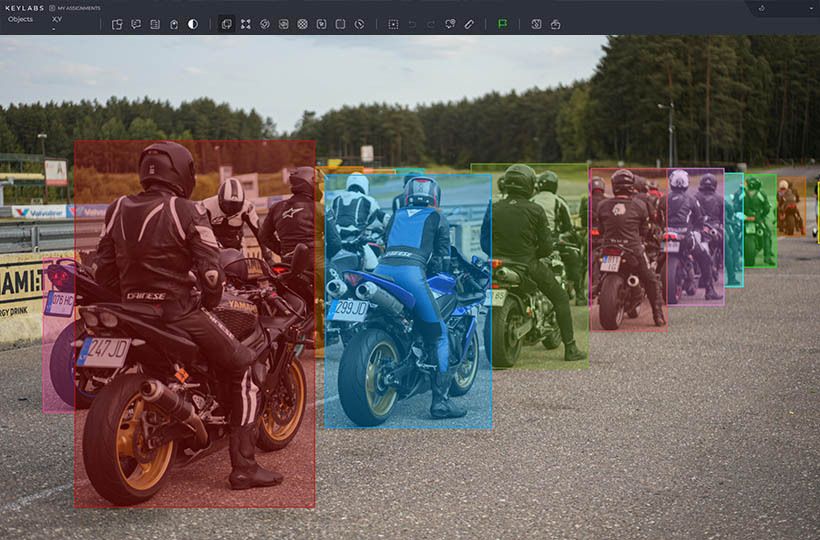
Data sources for edge case identification
AI data management involves collecting and managing data from various sources. Sources of data anomalies include:
- User annotations indicate problematic or rare cases.
- System logs (log files) of failed or atypical queries allow edge cases to be identified.
- Model error analysis identifies cases where the AI model exhibits low accuracy.
- External sources and open databases for comparison with your own data.
- User feedback.
Annotation Techniques for Edge Cases
- Manual annotation. Annotators manually mark edge cases based on their own experience and knowledge. Used in projects that require high accuracy and labeling quality. This process is time-consuming and expensive.
- Feedback-based annotation. Uses feedback from system users who identify incorrect predictions. Labels are created or adjusted based on the comments received. This improves accuracy based on real data.
- Automated annotation with verification. AI models automatically generate annotations for edge cases. These data are then verified by humans. This process is faster and maintains data quality at an appropriate level.
- Iterative annotation with active learning. The AI model independently identifies edge cases based on low confidence or high error rates. Involves annotators only for complex or ambiguous samples.
- Crowdsourcing of annotations. Involve a wide range of users or annotation platforms to label edge cases. Suitable for projects with large amounts of data with simple annotation.
- Semi-supervised learning. First, an AI model annotates samples automatically, and then humans only check the problematic cases. This method reduces the amount of manual checks required.
Challenges in Edge Case Curation
- Identification Difficulty. Edge cases are difficult to predict and detect due to their rarity and non-standardity.
- Data Constraints. Collecting edge cases is time-consuming and requires significant investment. Due to the rarity of such cases, there will be insufficient data to train on these data.
- Annotation Errors. Annotators may incorrectly label edge cases due to complexity or ambiguity. This can lead to incorrect training of the AI model.
- Cost of Verification and Correction. Involving experts in verification and correction can be expensive and time-consuming.
- Interpretation Ambiguity. The same edge case can be annotated differently.
- Dynamics of Edge Cases. Edge cases change over time in dynamic environments. Therefore, without updates, the AI model annotation may not be relevant.
A structured approach, including unbiased data collection methods and constant verification, is required to overcome these data challenges.
Tools for Edge Case Curation
Edge Case Curation tools automate the identification, annotation, and management of edge cases. These tools integrate with data collection and processing systems. This enables rapid analysis of rare or unusual scenarios.
Edge case management platforms have interfaces for manual verification and annotation. This allows annotators to verify the results of automated analysis.
The Keylabs platform has a large selection of tools and an experienced team of annotators. Thanks to these capabilities, our annotation is accurate and relevant for training AI models.
Practices in Edge Case Curation
- Clear annotation guidelines. This will ensure consistency and uniformity in the annotated data. The steps to establishing these guidelines include:
- Defining criteria for identifying edge cases.
- Establishing consistent guidelines for data annotation.
- Quality checks for data integrity.
2. Continuous monitoring and iteration. This method allows for real-time evaluation and timely correction of annotated data. Iteration is the process of repeating actions to achieve a desired result.
These methods ensure that the datasets are high-quality, accessible, and meet the organization's specific needs. This contributes to the development of a reliable AI model.
Metrics for Assessment
Evaluation metrics are used to measure the performance of machine learning models or algorithms. These metrics provide insight into how robust an AI model is.
Future Trends in Edge Case Curation
Innovations like deep learning and reinforcement learning will change how edge cases are detected and annotated. These advances will significantly improve the accuracy and efficiency of data annotation review processes.
The development of artificial intelligence is changing the edge case management system. Sophisticated algorithms and reinforcement learning are improving review processes. The embedding algorithm has improved visual data analysis. This now allows for creating advanced AI models for tasks like image classification and object detection.
Integrating digital twins with data improves real-time understanding. This controls the accuracy of edge case detection.
Human supervision remains essential for the correct management of rare cases. For complex cases, the best option is to combine automated tools with human expertise.
FAQ
What are edge cases in machine learning?
Edge cases are unusual cases that are significantly different from normal data.
Why is edge processing important to improve model reliability?
Edge processing helps identify weaknesses in AI models.
What are the common problems faced while curating edge cases?
The most common problems are data scarcity and data selection bias. This degrades the performance and efficiency of AI models.
How do we identify edge cases in data?
Anomaly, outlier analysis, and special algorithms identify rare cases in large datasets.
What are the best practices for edge case annotation?
Detailed instructions, consistent annotation, and a combination of manual and automated annotation are the key components for accurate edge case annotation.
What are the future trends in edge case processing?
Future trends include artificial intelligence techniques and a focus on human validation of annotation.