Integrating Annotation Into MLOps: A Step-by-Step Approach
Annotated data is the foundation for the success of machine learning models. MLOps integrates annotation into the ML lifecycle. This creates clear workflows for training and deploying models.
You will learn how to integrate annotation into the MLOps pipeline. We will explain how MLOps works and how to build an annotation process. You understand how to ensure data quality. Finally, we will show you steps to optimize the processes and improve the accuracy of your models.
Key Point
- Annotated data is essential for machine learning model success.
- High-quality annotated data streamlines machine learning processes and boosts model accuracy.
- Data annotation involves tagging objects and defining regions, which is key for accurate model training.
- Quality assurance processes are vital for maintaining consistency and accuracy in annotated datasets.
- Automated data annotation tools help reduce the labor-intensive nature of manual annotation.
- MLOps combines machine learning with software engineering, focusing on model lifecycle management.

What is MLOps and Its Importance in Machine Learning
Machine Learning Operations (MLOps) combines DevOps and machine learning to make ML systems productive, stable, and efficient. It helps manage annotated data, simplifies model launch, and reduces time and complexity.
MLOps enables continuous integration, delivery, and monitoring of ML models. It improves collaboration between data, development, and operations teams.
What is MLOps?
MLOps is a set of practices for managing the machine learning lifecycle. It includes several stages:
- Designing the ML-powered application
- ML Experimentation and Development
- ML Operations
This framework ensures ML models are continuously tested, retrained, and monitored.
Benefits of MLOps
- Streamlined Operations. MLOps provides control, integration, and monitoring.
- Enhanced Model Performance. Testing keeps models accurate and up-to-date.
- Improved Scalability. Enable faster iteration, debugging, and updates.
Levels of MLOps
These levels help MLOps annotations to provide consistent machine learning solutions.
The Role of Data Annotation in MLOps
Data annotation is essential for developing robust machine learning models. A well-structured data annotation workflow is essential for creating accurate and robust datasets. This directly impacts the performance and accuracy of the model.
Why Annotation is Important
Generative AI models like GPT use large datasets. They include unstructured and semi-structured data: text, images, audio, and video. Each data type requires its own annotation strategy. (Guide to Data Annotation)
- Text annotation. Entity tagging and contextual relationships.
- Image annotation. Segmentation and object detection. How to Choose an Image Annotation Tool
- Audio annotation. Transcription and event labeling.
Automatic labeling is effective, but human experience is also important. The problem is that complex scenarios are difficult for machines to understand. Hybrid annotation can significantly improve results.
Types of Data Annotation
Understanding the various types of data annotation is key to building a successful annotation pipeline. These include:
Building an Annotation Pipeline
An efficient annotation pipeline is essential for achieving high accuracy and reliability in machine learning projects. The global ML market is estimated to grow from $21.17 billion in 2022 to $209.91 billion in 2029, which is important for annotation management and process automation.
Project Requirements
Before beginning annotation, you should assess the needs, goals, complexity, and quality of the project. Correctly defining the range of work helps streamline the process and ensure data consistency.
Сonsiderations include:
- Objective Clarity. Define the purpose of the annotation to improve model performance or increase data diversity.
- Complexity Assessment. Determine the complexity of the annotation tasks. Complex tasks need specialized training or tools.
- Quality Benchmarks. Set quality benchmarks. For example, achieving consistency is critical for dataset quality.
Identifying Data Sources
The success of an annotation pipeline depends on the quality of the data sources. Reliable sources provide high-quality data for training ML models, which enables annotation automation. Compare sources to make the right choice.
By assessing your project requirements and choosing the best sources, you build a foundation for an efficient and scalable annotation pipeline.
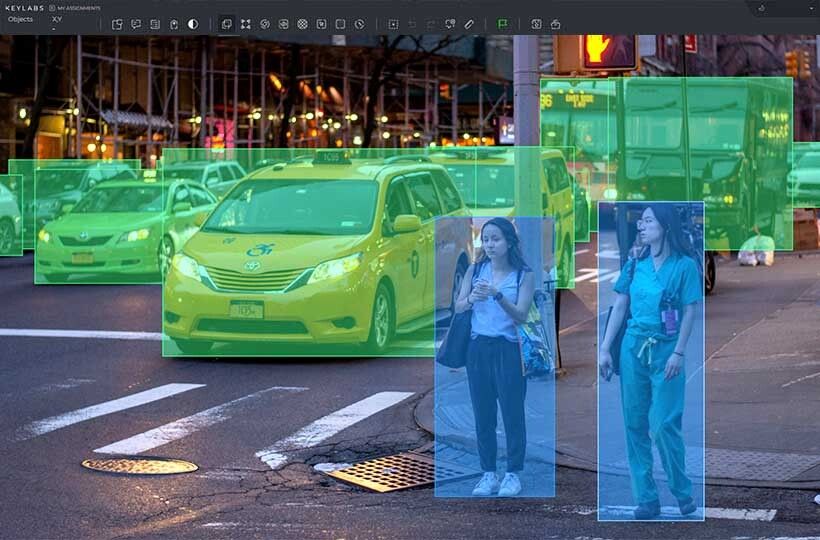
Tools and Technologies for Annotation
Choosing quality annotation tools is essential and is the foundation for successful MLOs. They allow experts to focus on model development, not data preparation. Here are some popular options.
Popular Annotation Tools
Keylabs is a leading data annotation platform that offers user-friendly image and video annotation tools, as well as machine learning support to improve process efficiency.
These features are essential in the field of data annotation, enabling the process of preparing data for machine learning.
Open-source vs. Commercial Solutions
The difference between open source and commercial tools depends on the needs, budget, and skills of the team. Open-source tools offer flexibility and customization, while commercial tools offer ready-made solutions with integration capabilities.
This knowledge helps improve data quality and grow the success of ML projects.Check out Keylabs blog explores factors to consider when choosing annotation tools for data annotation projects.
Designing Your Annotation Workflow
Effective annotation workflow management is quality in machine learning projects. We'll look at setting up workflow stages and best practices to boost your data annotation workflow's efficiency.
Best Practices for Efficiency
Here is a list to improve your annotation workflow management:
- Automation. Use tools like Nexus to automate the process, saving time and reducing errors.
- Parallel Workflows. Use parallel workflows to manage workload.
- Сlear Guidelines. Have detailed annotation guidelines for consistent data labeling.
- Continuous Testing. Testing the annotation pipeline to improve functionality.
- Feedback Loops. Include feedback loops for ongoing improvement.
These practices will streamline your data annotation workflow and improve its accuracy and efficiency in the MLOps pipeline.
Integrating Annotation into an Existing MLOps Pipeline
Integrating annotation into an existing MLOps pipeline can smooth machine learning model development. Using the right tools can improve annotation pipeline monitoring, which leads to better workflow automation and increased efficiency.
Automation Techniques
Automation reduces manual work and improves the process of annotation.
Automation can also be achieved through custom scripts and software extensions. This ensures data moves smoothly through the MLOps lifecycle.
Monitoring keeps the workflow running and quickly fixes any issues. This monitoring is not just for maintaining the workflow but also for improving annotation quality. Better annotations lead to better model performance.
Using API solutions and automation, companies can improve their MLOps pipelines.
Importance of Quality Control
Quality control in annotation pipelines is maintaining data integrity. Several errors in the early stages can impact a model's performance. It adopted robust quality assurance practices. Data cleansing can improve the quality of the final solution better than advanced algorithms.
Inter-annotator agreement (IAA) metrics measure consistency among annotators. Audits and automated tools help identify errors and reduce human error rates. You can find detailed information in this Keylabs blog.
How is Ensuring Accuracy
We have several methods that you can use:
- Comprehensive Annotation Guidelines. Detailed guidelines standardize annotations, reducing ambiguity and ensuring uniform quality.
- Domain Expert Validation. The accuracy and relevance of annotated data.
- Automated Quality Checks. Automated tools and scripts speed up error detection. Analyzing errors in annotated data updates training materials.
- Training and Continuous Feedback. Training sessions and feedback enhance annotators' skills and adherence to quality standards.
Through these methods, we improve the reliability of ML.
Feedback Loops for Improvement
Creating strong feedback mechanisms is essential for annotation process automation. Feedback loops enable human reviews and expert consultations to evaluate predictions and annotations:
- Human-in-the-loop Reviews. Ensuring accurate model predictions support real-world decisions through periodic expert reviews.
- Expert Consultations. Engaging domain and ML experts and business users to offer model performance and data quality insights.
- Data Capture and Retraining. Collecting model performance data, labeling new data, and retraining models to enhance accuracy.
Regular model upgrades and data checks throughout the ML lifecycle improve model and data quality. Explicit feedback loops help detect and address bias, ensuring our models perform at their best.
Challenges in MLOps Annotation
In this section, we will learn two common challenges: data bias elimination and scalability management in MLOps.
Addressing Data Bias
Data bias is the first problem that can occur during data collection, annotation, and model training. Let's see what we must do to address this problem:
- Implementing robust data validation processes.
- Utilizing automated tools.
- Regularly auditing data annotated.
Eliminating data bias is critical for developing reliable machine-learning models.
Scalability Issues
Managing scalability in MLOps is the second problem. The complexity increases as the number of models in a project increases. These factors include:
- Operational overhead managing multiple compute environments, from cloud to on-premises servers.
- Monitoring and debugging become more challenging as data volumes and model counts increase.
- Maintaining multiple model types requires sophisticated orchestration capabilities.
Effective scalability management in MLOps ensures efficient workflows. Developing a cloud-agnostic deployment strategy can reduce issues.
Future in Annotation and MLOps
Rapid progress in automation and artificial intelligence manage these changes. Integrating new technologies will change how we manage annotation pipelines and optimize MLOps workflows.
Automation and AI-driven Annotation
Automation in annotation is rapidly advancing, thanks to AI. By using AI-driven annotation, companies can significantly improve the efficiency of labeled data. This speeds up annotation workforce management and the development of machine-learning models. Reduces labor costs and human error.
The Rise of Computing in MLOps
It enables data processing at the source, facilitating analytics and decisions. Edge computing will be vital in addressing latency issues and optimizing bandwidth usage.
As investing more in edge computing, we expect a shift towards more efficient AI deployments. This will lead to reliable AI-driven.
The mix of automation, AI-driven annotation, and edge computing organizations can unlock the full value of their data.
FAQ
What is MLOps?
MLOps merges DevOps with Machine Learning. MLOps enables continuous integration, delivery, and monitoring of ML models.
What are the benefits of MLOps?
MLOps workflow advantages: Streamlined Operations, Enhanced Model Performance, and Improved Scalability.
Why is data annotation critical in MLOps?
Data annotation is important for training ML models. A well-structured set creates robust datasets.
What types of data annotations?
Include text, images, audio, and video. Each type is vital in various applications.
How are annotation pipelines created?
Assess project needs and find reliable data sources. Determine the project's scope to choose quality data effectively.
What are some popular tools and technologies for data annotation?
Many tools are available, both open-source and commercial. Keylabs is a leading data annotation platform that offers user-friendly image and video annotation tools.
How do open-source annotation tools compare to commercial solutions?
Open-source tools are cost-effective and customizable but need technical know-how. Commercial options offer robust features and support but are pricier.
What are the best practices for designing an annotation workflow?
Establish clear stages from data collection to quality control. Ensure consistency in feedback loops for efficiency.
How can annotation be integrated into the MLOps pipeline?
Use API integration and automation to add annotated data to model development phases.
Why is quality necessary in annotation pipelines?
Quality assurance is essential for building reliable and effective ML models.
What techniques can be used to ensure annotation accuracy?
Implement quality control, like double-checking and setting validation protocols. Use specialized tools.
What are common challenges in MLOps annotation pipelines?
There are two issues: data drift and scalability. Strategies to address these issues are important to maintaining data integrity and efficiency.
How can data bias be addressed in annotation pipelines?
Use diverse annotator training and balanced datasets. Implement bias checks during annotation to address bias.
What are the approaches to managing scalability in annotation pipelines?
Automate tasks, use scalable platforms and manage annotator workforces. These strategies help handle large data volumes efficiently.
What future trends are expected in annotation and MLOps?
Automation and AI-driven annotation are emerging trends. Edge computing will also enhance real-time data processing and model deployment.
