Maximizing Object Detection: YOLOv8 Performance Tips
In the pursuit of excellence within the field of computer vision, harnessing the capabilities of YOLOv8 has become quintessential for professionals aiming to maximize object detection efficiency. This state-of-the-art model offers unparalleled superior real-time object detection, pushing the boundaries of speed and accuracy to new heights. Critical to achieving optimal YOLOv8 performance is commencing with the default settings. Establishing a performance baseline is the foundation from which improvements can be made, only after thorough analysis of extensive training results data is performed.
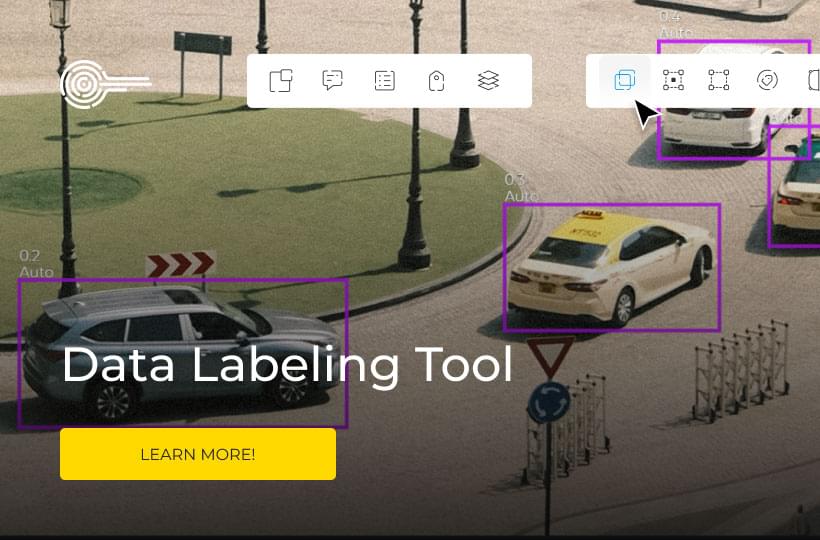
The confluence of a sufficiently large and meticulously labeled dataset is a fundamental prerequisite for the effective training of the YOLO architecture. As practitioners traverse the complexities of YOLOv8, the emphasis is invariably placed on precision—ensuring that the precision-recall curves resonate with high mAP scores, reflecting the adept maneuvering through the nuances of real-time object detection.
Key Takeaways
- Starting with default settings is vital for establishing a YOLOv8 performance baseline.
- Significant performance enhancements can be achieved after analyzing initial training results.
- Success in object detection with YOLOv8 depends heavily on large, well-labeled datasets.
- An understanding of precision-recall curves and mAP scores is crucial for refining object detection capabilities.
- Efficiency in real-time object detection is the hallmark of YOLOv8's prowess in the field of computer vision.

Understanding YOLOv8 and Its Evolution
The field of computer vision has rapidly evolved with the advent of YOLO architectures, with the latest iteration, YOLOv8, marking a significant milestone in YOLOv8 evolution. Much more than a conceptual redesign, YOLOv8 brings to the table transformative speed improvements and high accuracy object detection, addressing critical needs in real-time object detection. As the technology makes strides, understanding the advancements YOLOv8 offers becomes paramount for those invested in pushing the envelope of computer vision performance.
From YOLO to YOLOv8: Tracking the Improvements
From its original incarnation to the present, the YOLO algorithm has undergone numerous updates, each improving upon the last in terms of YOLO architecture performance. Starting as an anchor-based approach, YOLO has transitioned through versions, enhancing its ability to swiftly and accurately detect objects within a variety of environments. YOLOv8 epitomizes these advancements by offering enhanced detection speed—a game changer for applications requiring instantaneous analyses.
Key Innovations in YOLOv8: Speed and Accuracy
YOLOv8 has taken significant leaps in innovation, with pivotal enhancements that bolster its prowess in object detection tasks. The shift from an anchor-based system to an anchor-free architecture not only simplifies the training procedures across diverse datasets but also serves as a testament to the algorithm's versatility. Furthermore, the introduction of multi-scale prediction solidifies YOLOv8's ability to discern objects of varying sizes with a high degree of accuracy, thereby setting a new standard for efficiency and effectiveness in real-time object detection scenarios.
Building a Strong Foundation: Dataset Essentials
The quest for peak object detection performance begins with laying the correct groundwork, which in the realm of computer vision pertains to the assembly of a robust dataset. Mastery over dataset construction for deep learning is a pivotal cornerstone in establishing a high benchmark of efficacy in efficient object detection strategies. Prior to delving into the intricacies of image assortment and labeling protocols, it is imperative to highlight the dataset's role as the foundational scaffold upon which YOLOv8's algorithms are trained to accurately recognize and localize objects.
Importance of Image Variety and Background Selection
A diverse array of images constitutes the structural backbone of any dataset fashioned for deep learning and is instrumental in refining object detection capabilities. Each image incorporated into the dataset must reflect the conditions of the intended deployment environment, whether it be diverse lighting conditions, a plethora of angles, or a multitude of backgrounds. A deliberate selection of images, including a spectrum of operational scenarios, imbues the model with the versatility necessary for efficient object detection in real-world applications.
Labeling Accuracy and Verification for Reliable Training
The tagging and marking of data points within images must be executed with precision, as this step delineates the parameters for the model to identify and classify objects accurately. Precise labeling encapsulates the notion of bounding each object within a tight frame, ensuring no gap resides between the object and its label. Such thoroughness affords the model the clarity to discriminate between objects of interest and the background effectively. The veracity of these labels can be ascertained via an inspection of training batches, thereby verifying the correctness and reliability of the annotations — a steadfast protocol that significantly impacts object detection performance.
| Aspect of Dataset Construction | Significance | Impact on Object Detection |
|---|---|---|
| Diverse Image Assortment | Facilitates generalization; covers various environmental factors. | Enables detection across different conditions, improving robustness. |
| Background Selection | Aids in reducing false positives through situational context. | Enhances precision by familiarizing the model with negative examples. |
| Accurate Labeling | Critical for the correct identification of object boundaries in training. | Directly correlates to the model's ability to detect and classify objects. |
| Label Verification | Assures the label's positional and dimensional accuracy on objects. | Ensures high confidence in detections and low rates of misclassifications. |
Model Selection Strategy: Balancing Speed and Accuracy
When advancing towards the apex of efficient object detection, the symbiosis of speed and accuracy is non-negotiable. In the cosmos of YOLOv8 model performance, this balance is heavily influenced by model architecture choices. Compelling as it may be to reach for larger models like YOLOv8x for their heightened accuracy, one must be cognizant of the computational heft they carry. It is this very evaluation of requirements—be it swiftness for mobile deployment or meticulousness for cloud-based applications—that steers the selection process.
Pretrained weights stand as beacons of efficiency for those navigating the vast seas of smaller datasets. They offer a vantage point, a head start in the race towards reliable object detection without the torment of extensive computational burdens. Conversely, as the dataset amplifies to larger scales, a bespoke commencement—a granular 'start from scratch' approach—behooves the performance, allowing for custom calibration fine-tuned to specific dataset intricacies.
The choreography of choosing the right YOLO model underscores the gravitas of intended use and expected environmental conditions. It is a strategic poise between the alacrity of detection and the precision of results, a deliberate calibration influenced by numerous factors:
| Model Type | Purpose and Suitability | Accuracy and Speed Consideration |
|---|---|---|
| YOLOv8x | Ideal for high-precision scenarios with computational resources | High accuracy with a proportional decrease in speed |
| YOLOv8 Pretrained | Suitable for environments with limited data diversity | Competent accuracy while leveraging speed |
| YOLOv8 Custom Start | Optimized for expansive datasets with unique requirements | Customized balance of accuracy and speed contingent on training |
In essence, the triumphant orchestration of aligning YOLOv8 models with bespoke operational prerequisites underscores the quintessential balancing act of speed and accuracy. It is a discerning tactician who, aware of the constraints and freedoms of each deployment landscape, can maneuver through these considerations to attain peak YOLOv8 model performance and uphold the zenith of efficient object detection.
Navigating YOLOv8 Performance Parameters
In the dynamic realm of computer vision performance, tuning YOLOv8 is akin to a meticulous art form that marries technology with precision. Key performance parameters stand as the pillars upon which the structure of deep learning performance is built. Mastering these variables is non-negotiable for those seeking to refine their object detection systems to operate with unrivaled efficiency.
Role of Image Size and Batch Size in Model Performance
The intricacies of YOLOv8 optimization require a nuanced understanding of the role played by image size and batch size. Both these parameters are influential in steering the performance parameters of the model, dictating the proficiency with which it can process and interpret visual data. While a larger image size can lead to increased accuracy by preserving more detail, it necessitates a trade-off in terms of computational demand.
Conversely, batch size is a critical lever that modifies the learning process. An optimum batch size strikes the balance between memory limitations and efficient learning, reducing the number of updates needed to achieve convergence. Hence, striking a balance with batch size is fundamental for achieving peak YOLOv8 performance.
| Performance Parameter | Impact on YOLOv8 | Best Practice Considerations |
|---|---|---|
| Image Size | Higher resolution increases accuracy but demands more computational power. | Maintain high resolution in alignment with dataset traits and hardware capacity. |
| Batch Size | Larger batches improve generalization but require more GPU memory. | Use the largest batch size possible without exceeding hardware constraints. |
Implications of Epochs and Hyperparameters on Training
The architecture of YOLOv8 is fine-tuned not only through elements like image size and batch size but also through the careful calibration of epochs and hyperparameters. The number of epochs directly correlates with the model's exposure to the training data, with an extended training period enriching the model's ability to discern and detect nuanced features within an image.
Amid the vast spectrum of performance parameters, hyperparameters hold the key to unlocking the full potential of YOLOv8. Their optimization, while complex, is instrumental in adapting the learning process to the unique contours of the dataset. Adjusting these settings allows for the fine-tuning required to reach peak performance in object detection tasks.
| Training Parameter | Impact on YOLOv8 Training | Adjustment Strategy |
|---|---|---|
| Epochs | Determines the model's exposure to the training data. | Adjust based on model performance and overfitting indicators. |
| Hyperparameters | Influences the learning rate, weight adjustments, and other key training aspects. | Tune systematically based on baseline performance and dataset specificity. |
Ultimately, navigating the labyrinth of YOLOv8's performance parameters demands not only a thorough understanding but also an adaptive approach. Such agility in tuning YOLOv8 allows visionaries in the field of computer vision to push beyond the frontiers of what's possible, pioneering innovations that redefine the standards for deep learning performance.
Hyperparameter Optimization: The Journey to Peak Performance
The art and science of fine-tuning YOLOv8 to achieve peak performance in object detection is largely predicated on the effective optimization of hyperparameters. By harnessing Bayesian optimization, a systematic search for the optimal hyperparameters unfolds, utilizing previous iterations' data to strike an ideal balance between exploration and exploitation of the parameters' space.
This journey involves leveraging an array of computational tools, among which Weights & Biases stands out, providing an intuitive and robust platform to track, visualize, and fine-tune the model's performance. Each hyperparameter, from learning rate to batch size, plays a critical role in the network's learning ability, affecting the precision with which the model can detect and localize objects in various scenarios.
Through Bayesian optimization, the process of hyperparameter optimization transcends brute force grid search, becoming an intelligent strategy that prioritizes promising areas of the search space. In the context of YOLOv8, this translates to a refined search that continually narrows down towards the combinations that yield the most promising improvements in model accuracy, as gauged by the Mean Average Precision (mAP) score.
| Hyperparameter | Impact on Detection | Bayesian Optimization Insight |
|---|---|---|
| Learning Rate | Controls the magnitude of weight updates | Lower values can improve convergence to optimal weights |
| Batch Size | Affects memory usage and model generalization | Larger sizes may enhance generalization but are limited by hardware |
| Image Size | Influences the resolution of input data | Higher resolutions can increase accuracy at the cost of computational load |
| Epochs | Number of complete passes through the dataset | More epochs can lead to better learning until overfitting occurs |
The ultimate goal of this exploration is not just to attain a high mAP score on validation datasets but to calibrate the model such that it realizes its full potential in diverse real-world applications. By perfecting the art of hyperparameter optimization, YOLOv8 can reach a crescendo of peak YOLOv8 performance, equipped to tackle the myriad of challenges presented by real-time object detection across various environments and contexts.
Choosing the Right Training Settings
The labyrinth of YOLOv8 training settings demands careful navigation to fully harness the model's capabilities. To optimize object detection tasks, one confronts a pivotal crossroads: the utilization of pretrained weights versus the initiation of training from scratch, with each path tailored to dataset size and specificity. Training optimization is further nuanced by a myriad of strategic decisions surrounding augmentation and dropout, all of which can furnish a system with the resilience to nullify overfitting and ascend to its zenith performance.
When to Use Pretrained Weights vs Training from Scratch
Embarking on the YOLOv8 journey with pretrained weights is akin to receiving a navigational chart, accelerating progression toward success, especially with smaller datasets that may fail to provide the variance necessary for comprehensive learning. For endeavors submerged within the oceans of large-scale data, training from scratch permits the model to charter unknown territories, crafting its own map with the deep-seated intricacies unique to vast volumes of data.
Understanding the Impact of Augmentation and Dropout
Strategically enhancing YOLOv8 training settings with data augmentation introduces a realm of varied patterns, bolstering the model's robustness against overfitting. Dropout, in tandem, operates as a failsafe, severing connections within the neural network at random intervals to promote a more generalized understanding of the data. Its mastery lies not in its application, but in fine-tuning its magnitude to strike equilibrium between preventing overfitting and maintaining neural path richness.
| Training Decision | Benefits | Considerations |
|---|---|---|
| Using Pretrained Weights | Accelerates initial convergence and beneficial for smaller datasets. | May limit model's ability to learn complex patterns unique to specific datasets. |
| Training from Scratch | Allows model to adapt deeply to dataset intricacies offering potentially higher performance. | Requires large datasets and can significantly increase training time and computational resources. |
| Implementing Data Augmentation | Enhances model's ability to generalize and reduces risk of overfitting. | Needs careful adjustment to prevent too much complexity which could hinder learning. |
| Applying Dropout | Effectively prevents overfitting by simplifying the network during training. | Dropout rate must be finely calibrated as too much can starve the model of necessary information. |
Maximizing mAP: The Metric for Performance Measurement
In the competitive landscape of computer vision, the accurate assessment of an object detection model's efficacy is paramount. Among the various performance measurement metrics, the mean Average Precision (mAP) score emerges as essential for gauging the precision and reliability of models like YOLOv8. As a trusted benchmark, mAP focuses on the intersection over union (IoU) to quantify the overlap between the predicted bounding boxes and the ground truth, offering a clear indicator of YOLOv8 accuracy.
Interpreting mAP for Object Detection Success
Distinctively positioned at the core of mAP maximization strategies, the mAP score serves as a definitive signal of model performance, especially at an IoU threshold of 0.5, or mAP50. The nuanced interpretation of this score affords experts a method to compare and contrast the accuracy of object detection across various models and conditions. Through rigorous evaluation, mAP50 becomes a pivotal focal point that helps data scientists optimize for YOLOv8 accuracy, ultimately leading to more refined and adept object recognition technologies.
Factors Contributing to Higher mAP Scores
The attainment of higher mAP scores is influenced by a multitude of factors, all intrinsic to the meticulous design and training of the YOLOv8 model. How thoroughly a dataset is annotated, the diversity and representation within the image sets, and the alignment between training circumstances and real-world deployment conditions—all contribute heavily to the mAP calculus. Subsequently, these factors act in concert to boost the predictive prowess of the model, elevating mAP maximization from a goal to an achievement.
| Factor | Role in mAP Maximization | Impact on YOLOv8 Accuracy |
|---|---|---|
| Comprehensive Dataset Labeling | Improves the reliability of training outputs | Leads to more precise object localization |
| Image Set Diversity | Ensures robustness across varied scenarios | Increases mAP by enhancing model adaptability |
| Real-World Training Alignment | Prepares the model for practical application | Enables consistent, accurate detection in deployment |
The systematic pursuit of mAP maximization calls for an unwavering dedication to quality and precision, underpinned by a robust evaluation framework that foretells the performance measurement metrics indicative of YOLOv8's capabilities. It is this relentless drive for perfection that underscores the ongoing evolution and improvement of object detection systems.
YOLOv8 Architecture: Designed for Efficiency
The evolving landscape of object detection algorithms witnesses a landmark advancement with the advent of YOLOv8 architecture performance. Central to this progression is the model's innovative design, which significantly improves operational efficiency in computer vision tasks. By stepping away from conventional methods and embracing a more streamlined process, YOLOv8 creates new paradigms for machine learning and artificial intelligence.
The Anchor-Free Approach for Streamlined Detection
At the crux of YOLOv8's effectiveness is its anchor-free architecture, a revolutionary shift from traditional anchor boxes that have long been a staple in object detection. This liberated structure redefines the detection process, granting the model not only an agility unencumbered by prior constraints but also aiding in an expedited and more flexible training experience. With YOLOv8, the anchor-free mechanism has proven to transform the way datasets of various kinds are approached, easing the training process and fostering improved performance outcomes.
Multi-scale Prediction for Diverse Object Sizes
The strength of YOLOv8 is encapsulated in its ability to conduct multi-scale prediction. Reliable detection across a spectrum of object sizes stands as a testament to the model's intricate design, crafted to confront the challenges presented by the diversity in scale. Such versatility in detection ensures that the YOLOv8 architecture renders itself indispensable for robust object detection applications where performance cannot be compromised by the limitations of scale.
Together, these features create a harmony of high performance and adaptability, setting YOLOv8 apart as a leader in the realm of efficient object detection architectures. The seamless integration of an anchor-free approach along with multi-scale predictability foster a conducive environment for defining future best practices in object detection.
Impact of Environmental Variety on YOLOv8 Model Performance
The robustness of YOLOv8 in diverse environments is a testament to its design as a solution for real-time object detection. However, this resilience is not inherent but largely results from a dataset that adequately represents the multitude of conditions an AI may encounter. With the complexity of our world's varying scenes, a model must be ready to decipher and accurately identify objects amidst the environmental mosaic it is deployed in, be it a sunlit highway or a fog-enshrouded street at dusk.
Challenges of Real-time Object Detection in Diverse Conditions
Challenges abound when deploying YOLOv8 for real-time object detection across conditions that fluctuate from dawn to dusk and in all too common unpredictable weather. High-performance models must discern subtle nuances in shadow and light transitions. The unpredictability of such scenarios poses considerable challenges, where computational models like YOLOv8 must continuously adapt to ensure the slightest aberration doesn't lead to misidentification or critical omissions.
Adapting YOLOv8 for Day, Night, and Severe Weather Performance
Successfully integrating YOLOv8 in diverse environments hinges on the model's ingenuity to maintain robust object detection capabilities in the face of day-to-night changes and adverse weather. In severe conditions, traditional sensors might falter, but YOLOv8's advanced architecture and training protocols allow it to persevere, making it instrumental for applications requiring consistently high performance. The key is the training on datasets encompassing all possible variances—to prepare YOLOv8 for the real-world test, ensuring precision and reliability are not compromised.
FAQ
What are some essential tips for maximizing YOLOv8 performance in object detection?
To maximize object detection efficiency with YOLOv8, begin with default settings to establish a baseline, ensure your dataset is substantial and well-labeled, and adjust performance parameters such as image size and batch size. Additionally, consider the trade-off between speed and accuracy when selecting your model.
How has YOLO evolved to YOLOv8, and what improvements have been made?
YOLOv8 has evolved from previous iterations to offer significantly faster speeds and improved accuracy, crucial for real-time object detection. Key innovations include an anchor-free architecture and multi-scale prediction capabilities, which have greatly enhanced its ability to detect smaller objects with precision.
Why is the choice of images and backgrounds important for YOLOv8 training?
A diverse array of images and backgrounds is essential for constructing an effective dataset because it must reflect the real-world conditions in which the YOLOv8 model will operate. This variety ensures that the model can perform efficiently and accurately when deployed.
What is the importance of labeling accuracy in YOLOv8 model training?
Labeling accuracy is crucial for reliable training as every instance of each class in the dataset must be meticulously labeled to tightly enclose each object. Verified, precise labels are fundamental for the model to learn correct object detection.
How should one balance speed and accuracy when selecting a YOLOv8 model?
Balancing speed and accuracy depends on the deployment setting. Larger models may offer better accuracy but require more computational resources. Consider the operational environment and select a model that provides the best compromise between detection speed and accuracy.
What roles do image size and batch size play in YOLOv8 performance?
Image size affects the resolution at which the model detects objects, while batch size influences memory utilization and learning stability. Optimal training involves selecting the largest possible batch size and maintaining high image resolution within hardware constraints.
How do epochs and hyperparameters influence YOLOv8 training?
The number of epochs determines the duration of the training process. Adjusting epochs in response to overfitting helps refine model performance. Hyperparameters, such as learning rate and momentum, require tuning to achieve the best object detection results.
When is it preferable to use pretrained weights or start training from scratch?
Use pretrained weights for smaller datasets to leverage existing learned patterns. For larger, more diverse datasets, starting from scratch might be more beneficial as it allows the model to uniquely adapt to the specific data characteristics.
What is the role of data augmentation and dropout in YOLOv8 training?
Data augmentation introduces variability into the training process, which can prevent overfitting and improve model robustness. Dropout randomly deactivates neurons during training, encouraging a more generalized model that doesn't rely too heavily on specific data features.
How is mAP used to measure YOLOv8 performance?
Mean Average Precision (mAP) quantifies how accurately the model identifies and delineates the correct bounding boxes around detected objects. A higher mAP score indicates better object detection performance, making it a crucial metric for assessment.
What are the advantages of YOLOv8's anchor-free approach?
YOLOv8's anchor-free approach simplifies the detection process, reduces the need for hyperparameter tuning related to anchors, and generally streamlines training on varied datasets, resulting in a more efficient object detection framework.
How does multi-scale prediction enhance YOLOv8's accuracy?
Multi-scale prediction allows YOLOv8 to detect objects of varying sizes more accurately by predicting at different scales. This capability enables the model to maintain high accuracy across a broader range of object dimensions.
How does diverse environmental conditions affect YOLOv8 performance?
Variable lighting, weather, and times of day can significantly impact model performance. YOLOv8 must be trained on a dataset representative of these conditions to ensure robust object detection in real-world scenarios.
What strategies can be employed to maintain YOLOv8 accuracy in various conditions like day, night, and severe weather?
Strategies include using a representative dataset that includes diverse conditions, applying data augmentation techniques to simulate these environments, and adjusting model settings to maintain performance across different scenarios.