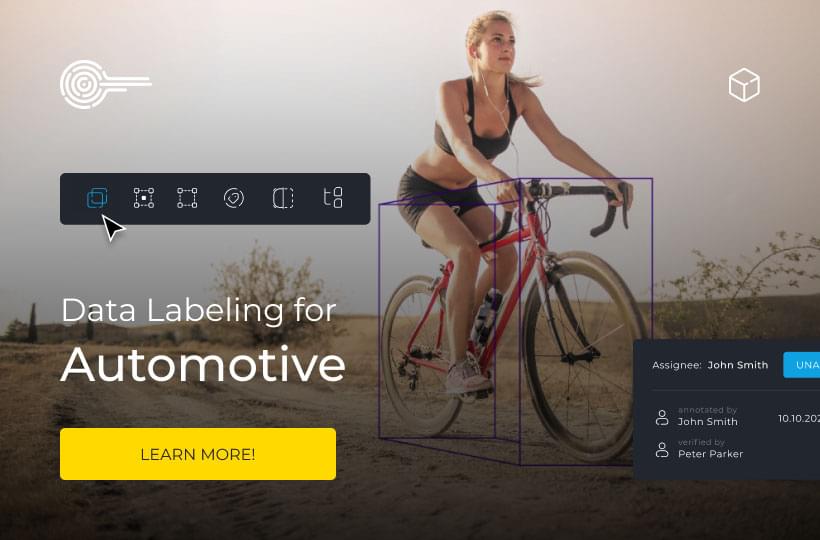
The Role of Machine Learning in Enhancing Object Recognition
Recently, object recognition technology started getting used to analyze mental health issues. It does so by spotting early signs in patient photos, like those linked to Parkinson's. This finding underlines the vast potential of machine learning in improving how we recognize objects, which is changing a wide range of sectors and elevating our daily experiences.
Object recognition is a key part of computer vision, allowing computers to pinpoint and identify items in pictures or video. It has uses in fields including video surveillance, self-driving cars, and medical imaging. Thanks to advances in AI and machine learning, the accuracy and speed of identifying objects in both images and videos have increased. This makes object recognition a must-have in today's tech world.
Machine learning and deep learning are vital for top-tier object recognition. They work together, with deep learning's neural networks, particularly CNNs, capturing intricate and abstract features. These surpass the capabilities of traditional methods. While machine learning is swift, deep learning excels in accuracy but needs more data and processing power.
The blend of computer vision and machine learning shines in recognizing objects, from reading characters to driving cars. With further technological advancements, we anticipate even more innovative applications and stronger performance in all sectors. This progression will make our lives not just safer but more efficient and simpler as well.
Key Takeaways
- Object recognition is a computer vision technique that identifies and locates objects in videos or images, with applications in various domains.
- Machine learning and deep learning algorithms, particularly convolutional neural networks (CNNs), play a crucial role in enhancing object recognition capabilities.
- Deep learning methods achieve high performance but require more computational resources and data compared to traditional machine learning approaches.
- Object recognition technology has the potential to revolutionize industries such as healthcare, retail, and autonomous driving.
- The synergy between computer vision and machine learning is evident in object recognition applications, ranging from optical character recognition to automated driving systems.

Introduction to Object Recognition
Object recognition, within computer vision, has flourished lately, captivating many due to its diverse applications. It entails spotting objects in images or videos, drawing boundaries around them and labeling them. This involves two key processes: image classification, for identifying the object, and object detection, for pinpointing its location.
Its critical role spans across sectors like autonomous vehicles, medical analysis, and security. By enabling machines to recognize their surroundings, it leads to smarter, more automated systems. These systems can act on what they 'see,' based on their visual interpretation.
Traditional Approaches to Object Recognition
In the past, object recognition heavily leaned on manual design and custom-built algorithms. However, these techniques often faltered due to the changing appearances of objects and lighting conditions. Moreover, they struggled with large datasets and real-time demands.
| Traditional Approach | Description |
|---|---|
| Template Matching | Comparing an input image with a set of pre-defined templates to find the best match |
| Feature-based Methods | Extracting hand-crafted features, such as edges and corners, and using them for object recognition |
| Viola-Jones Algorithm | A machine learning-based approach that uses a cascade of classifiers to detect objects, particularly faces, in real-time |
Limitations of Traditional Approaches
Even with some early wins, traditional methods face barriers in tackling real-world complexity. These challenges include:
- The need for manual feature engineering, which is both time-consuming and reliant on specialized knowledge.
- An inability to manage varied scenes and object appearances.
- Real-time application difficulties, especially with vast datasets.
- Sensitivity to lighting changes, varied viewpoints, and object obstructions.
Thus, the spotlight has shifted to machine learning and deep learning. These techniques have made significant strides in enhancing object recognition. They offer a path to better accuracy and operational efficiency. In championing data-driven solutions and autonomous feature learning, they mark a new phase in object recognition's evolution.
Fundamentals of Machine Learning
Machine learning offers a powerful method for computers to learn and make decisions from data without direct programming. It falls under artificial intelligence, which has seen a surge of interest. This is thanks to its capability to enhance itself and recognize patterns within vast data sets. With the increasing volume of data created each day, machine learning becomes indispensable for making informed decisions using technological insights.
The main methods of machine learning are supervised and unsupervised approaches. Supervised learning trains models with labeled examples to predict outcomes. In contrast, unsupervised learning allows models to identify patterns on their own. Semi-supervised algorithms combine aspects of both to better understand data.
Supervised Learning
In supervised learning, algorithms learn from data paired with known outcomes. The aim is to deduce a function that connects input to the correct output. Common applications include:
- Image classification: Identifying objects or scenes in images
- Sentiment analysis: Determining the sentiment (positive, negative, or neutral) of a piece of text
- Fraud detection: Identifying fraudulent transactions based on historical data
Unsupervised Learning
Unsupervised learning focuses on drawing patterns from data without known outcomes. It lets the algorithm find hidden structures independently. It is used in:
- Clustering: Grouping similar data points together based on their characteristics
- Anomaly detection: Identifying unusual or rare events in a dataset
- Dimensionality reduction: Reducing the number of features in a dataset while preserving its essential information
Deep Learning
Deep learning uses neural networks with multiple layers to extract intricate features from data. It can learn features on its own, optimize itself, and manage large data efficiently. This has led to significant achievements in fields such as:
| Domain | Applications |
|---|---|
| Computer Vision | Object detection, image segmentation, face recognition |
| Natural Language Processing | Language translation, sentiment analysis, text generation |
| Speech Recognition | Voice assistants, speech-to-text, speaker identification |
Transfer learning is a critical aspect of deep learning, improving model adaptability to new tasks with little data. This approach speeds up training and enhances accuracy, making deep learning more accessible across various fields.
To grasp machine learning, one should understand linear equations, graphs, statistics, and more. With a strong foundation and the enthusiasm for data analysis, the journey to mastering machine learning is open to all. It presents an opportunity to tackle significant real-world issues.
Machine Learning Techniques for Object Recognition
Machine learning has radically shifted object recognition, equipping computers to identify and pinpoint items within images and videos without human input. There are various methods to tackle this feat, each having unique characteristics but all aiming to enhance recognition accuracy. We dive into the top machine learning avenues critical for pinpointing objects, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and transfer learning.
Convolutional Neural Networks (CNNs)
Among these, convolutional neural networks (CNNs) stand out as a leading choice for deep learning in object spotting. They are designed to glean critical features from images automatically, capturing both their spatial and temporal relations. Within the CNN structure lie important elements like convolutional layers and pooling layers that work in sync to extract significant features and achieve precise object classification.
CNNs shine in handling vast amounts of data and decoding intricate patterns without earlier manual intervention. Their prowess is evident in various fields, from enhancing autonomous vehicles to investigating medical images, and bolstering security through surveillance.
Recurrent Neural Networks (RNNs)
RNNs, on the other hand, specialize in recognizing objects within dynamic content like videos. They process sequentially, honing in on the motion and progression of objects, thereby capturing temporal dependencies. This knack makes RNNs highly effective in tasks like tracking objects throughout a video sequence.
Included in RNNs' list of successful applications are video object detection, tracking for identification, and accurate segmentation. Their aptitude in capturing temporal context significantly raises the bar in recognizing objects amid change or visual obstruction.
Transfer Learning
Transfer learning makes a mark by transforming general knowledge from pre-trained models into specific, defined tasks with only limited data. It shaves off training hours and boosts the accuracy of new object recognition models. By inheriting wisdom from a broader domain, it stands as a pivotal method for accelerating deployment and fine-tuning for unique tasks.
Its popularity in the realm of object spotlights is closely linked to well-established models such as AlexNet, VGGNet, and ResNet that benefitted from big datasets like ImageNet. With this foundation, models can swiftly adapt to new tasks with the availability of less data.
Data augmentation, meanwhile, aids by diversifying the training dataset, thus curbing overfitting and enhancing generalizability. Techniques like rotation and scaling not only add variety but prove crucial when working with scant or unbalanced data. This approach is pivotal for a model's robust recognition across diverse object sceneries.
| Technique | Strengths | Applications |
|---|---|---|
| Convolutional Neural Networks (CNNs) | Automatic feature learning, handling large-scale datasets, high accuracy | Image classification, object detection, segmentation |
| Recurrent Neural Networks (RNNs) | Processing sequential data, capturing temporal dependencies | Video object detection, tracking, segmentation |
| Transfer Learning | Leveraging pre-trained models, reducing training time, improving accuracy | Fine-tuning for specific object recognition tasks |
When determining the efficiency of object recognition models, we often employ metrics like precision and recall. Precision gauges the model's accuracy in identifying objects from those it detected, while recall measures it against the total objects available. This dual assessment focuses on the model's correctness and its ability to minimize misidentification.
Wrapping up, object recognition has experienced a profound transformation thanks to convolutional and recurrent neural networks, alongside transfer learning and data augmentation. Researchers and experts can achieve breakthroughs in object identification systems for various applications by employing these techniques, supported by judicious evaluations.

Advantages of Machine Learning in Object Recognition
Machine learning has transformed object recognition, vastly improving accuracy, efficiency, scalability, and adaptability. It allows systems to learn features and patterns automatically. This eliminates the need for manual feature engineering, boosting performance and precision.
Machine learning, especially through deep learning models like CNNs, excels in complex scenarios. These models perform well in the real world, accurately spotting objects despite variations in appearance, size, and position.
Machine learning also shines in scalability. It enables systems to handle large data sets easily, getting better at recognizing new objects and scenes. This adaptability is essential in our data-rich, rapidly evolving digital landscape.
The ability to continuously learn and improve with more data makes machine learning-based object recognition systems more robust and efficient over time.
Here are statistics that underscore machine learning's advantages:
- Deep learning models, with extensive image data training, excel in recognizing objects in varying conditions.
- They learn new features without manual intervention, making them particularly useful for complex image detection.
- Deep learning excels with large datasets, pulling valuable insights from big data.
The adaptability of machine learning in object recognition is key. These systems continually learn and enhance, staying effective in changing conditions. This feature is invaluable in sectors like autonomous vehicles, where agility in recognizing new objects is vital.
| Advantage | Description |
|---|---|
| Accuracy | Machine learning enables object recognition systems to automatically learn features and patterns from data, reducing the need for manual feature engineering and improving accuracy. |
| Efficiency | Deep learning models, such as CNNs, can handle complex scenes and object variations, achieving high performance in challenging real-world scenarios. |
| Scalability | Machine learning techniques enable object recognition systems to scale to large datasets and adapt to new objects and environments through transfer learning and fine-tuning. |
| Adaptability | The ability to continuously learn and improve with more data makes machine learning-based object recognition systems more robust and efficient over time. |
As machine learning advances, its influence on object recognition deepens. The ongoing evolution of algorithms and the accumulation of vast data sets promise even better, more flexible, and effective systems. This progress is set to change entire fields and enhance our daily experiences.
Challenges and Limitations of Machine Learning in Object Recognition
Machine learning has truly transformed object recognition. Yet, it faces distinct challenges and limitations. Despite remarkable progress in this domain, various factors significantly influence the operational efficacy and dependability of object recognition systems based on machine learning.
Data Quality and Availability
The quality and availability of training data present a major hurdle for machine learning in object recognition. The efficacy of these systems significantly hinges on the scale and diversity of data applied. The process of gathering and annotating extensive datasets proves both arduous and costly, especially in tasks as intricate as object identification.
Take the COCO dataset, for example, provided by Microsoft. It encompasses 300,000 images in fragments spanning 80 object types. This dataset accounts for 1.5 million object instances in total, along with over 200,000 images that have been labeled. Despite its scale, this dataset mirrors only a small portion of the myriad objects and situations object recognition systems could potentially face.
Computational Resources
Machine learning in object recognition also grapples with significant demands on computational resources. The training and deployment of deep learning models, particularly convolutional neural networks (CNNs), necessitate extensive processing power and memory to operate effectively.
For illustration, R-CNNs generate 2,000 region suggestions in the detection process from a single image. Meanwhile, techniques like single-shot detectors leverage anchor boxes to detect objects, handling various scales and aspect ratios simultaneously. Such processes are computationally demanding, presenting obstacles to deploying object recognition technologies on devices with limited resources, such as smartphones or embedded systems.
Interpretability and Explainability
The complex nature of deep learning models, characterized by a lack of interpretability and explainability, poses a unique challenge. In contrast to rule-based systems, deep learning models often function like "black boxes," leaving the mechanisms behind their predictions obscured and challenging to comprehend.
This opacity is particularly troublesome in critical sectors like healthcare and autonomous vehicles, where offering clear reasoning behind a decision is essential for trust and accountability. Although efforts are being made to enhance deep learning models' interpretability, solving this issue remains a significant, ongoing endeavor.
| Model | Strengths | Limitations |
|---|---|---|
| R-CNN | State-of-the-art results on PASCAL VOC dataset | Computationally expensive, slow detection speed |
| YOLO | Real-time performance, simultaneous detection of multiple objects | Lower accuracy compared to two-stage detectors |
| ResNet 50 | High prediction accuracy (75%-90%) for large objects | Requires more computational resources |
| Tiny-YoloV3 | Fast execution time, suitable for real-time applications | Lower prediction accuracy (35%-80%) for large objects |
Additional obstacles faced by machine learning in object recognition involve addressing occlusion, clutter, and variances in object appearance. Ensuring systems' robustness and reliability under real-world conditions is likewise a significant challenge. As the field's body of knowledge continues to advance, mitigating these limitations is critical for the broader application and success of machine learning in object recognition.
Future Trends and Developments
Machine learning keeps making strides, particularly in object recognition. In the upcoming years, we expect major advancements in this field. By merging object recognition with advanced AI, such as natural language processing, the horizon broadens for smart vision systems. These systems will not only spot and place objects but also understand their context and connections, allowing for more sophisticated use in a range of areas.
Edge computing is emerging as a pivotal trend in the future of spotting objects. It brings data processing closer to the point of capture, allowing for spot-on object recognition even on devices with limited resources. For sectors like autonomous vehicles, where quick reactions based on spotting objects are vital, this could be a game-changer.
Integration with Other AI Techniques
Merging object recognition with additional AI technologies opens doors to new capabilities in vision systems. For example, pairing it with natural language processing means these systems can do more than just spot objects; they can also describe them in ways we understand. This mix improves interactions between humans and machines, making object recognition more approachable and easy to work with.
Adding reasoning powers to object recognition systems is another leap forward. It means these systems can make sense of what they see, drawing conclusions and taking actions without human help. This leads to highly intelligent, self-sufficient systems that are ready to deal with intricate situations on their own.
Edge Computing and Real-time Object Recognition
Edge computing is set to transform how we apply object recognition technology. By analyzing data closer to where it's captured, we cut down on the need for lots of data to stream to the cloud. This means less time lag and the ability to identify objects in real-time.
This is especially crucial for applications needing instant responses, like in autonomous vehicles and surveillance. Edge computing lets these systems analyze live video streams on the spot, making quick decisions without waiting for cloud-based processing that could slow things down.
| Technology | Impact on Object Recognition |
|---|---|
| Edge Computing | Enables real-time object recognition on resource-constrained devices, reducing latency and improving responsiveness. |
| Lightweight Deep Learning Architectures | Makes object recognition more accessible and deployable on a wider range of devices, including edge devices with limited computational resources. |
| Unsupervised and Self-Supervised Learning | Reduces the reliance on labeled data, enabling object recognition systems to learn from vast amounts of unlabeled data, improving scalability and adaptability. |
The future also holds advancements in leaner, more efficient deep learning architectures. These developments will spread the reach of object recognition, making it applicable on various platforms. From consumer tech to industrial IoT, these steps will ready the world for broad object recognition use.
Breakthroughs in unsupervised and self-supervised learning are set to be key. These methods slash the need for painstakingly labeled data, turning to unmarked data in learning. This means object recognition systems can scale and adapt better, handling more objects and situations.
AI techniques developments
As we watch object recognition evolve, its role in intelligent systems grows. From smart environments to self-driving cars and robots, this tech will be everywhere. By combining object recognition with insightful AI, powerful edge computing, and efficient learning, the eyes of our devices are about to see the future.
Best Practices for Implementing Machine Learning in Object Recognition
Implementing machine learning in object recognition demands careful steps to achieve superior models. One must meticulously prepare data to train powerful models. Tasks such as clearing data of noise and defining objects with labels are key. Adding variety to the data through techniques like rotation and scaling is also vital.
Choosing the right architecture and parameters greatly impacts the effectiveness of your system. For tasks in object recognition, CNNs stand out because they extract features well from images. While models like Faster R-CNN ensure high accuracy, they might be slow. Simultaneously, YOLO and SSD are praised for their speed yet may sacrifice a bit on precision.
It's crucial to use the right measures for evaluating model success accurately. Metrics like precision, recall, and mAP offer insights. Precision indicates how many correct identifications the model made compared to the total predictions. Recall shows the ratio of correctly identified instances over all actual cases. mAP, on the other hand, gives a comprehensive view of a model’s efficacy across different situations and items.
| Metric | Formula | Description |
|---|---|---|
| Precision | TP / (TP + FP) | Proportion of true positive predictions among all positive predictions |
| Recall | TP / (TP + FN) | Proportion of true positive predictions among all actual positive instances |
| mAP | Average precision across all classes and IoU thresholds | Comprehensive evaluation of the model's performance |
Application in real scenarios demands model compression and efficient system integration. Methods like quantization and pruning help keep models lightweight without significant loss of accuracy. Furthermore, optimizing the architecture and using frameworks designed for swift operations like TensorRT can enhance performance.
Maintenance and adaptation of the model are crucial for continuous high performance. This includes ongoing data collection, model retraining, and performance checks. Employing active learning can streamline the process, making model updates faster and more cost-effective while ensuring they meet current needs.
best practices data preparation
Summary
Machine learning, especially deep learning, has revolutionized object recognition. It has advanced computer vision significantly. Models now learn complex features from large data sets. This boosts the accuracy and efficiency of recognition systems.
This innovation has impacted various fields. It's in autonomous vehicles and medical diagnostics. It also helps in detecting threats accurately. But, several hurdles remain for machine learning in object recognition. Large, high-quality datasets are a necessity and you can get a headstart by creating your own with the help of Keymakr.
FAQ
What is object recognition?
Object recognition is a key aspect of computer vision. It allows machines to spot and pinpoint various items in images or videos. Its uses are widespread, from enhancing video surveillance to advancing autonomous driving.
How do machine learning and deep learning contribute to object recognition?
Machine learning and deep learning are pivotal for object recognition. They synergize, enhancing precision and performance. Deep learning architectures, like CNNs, excel by extracting intricate visual features. This surpasses the capabilities of traditional machine learning.
What are the main components of object recognition?
The process of object recognition entails two key steps. First, it identifies what the object is (image classification). Second, it locates where the object is (object detection). This is achieved by assigning class labels and drawing bounding boxes around the objects.
What are the limitations of traditional approaches to object recognition?
Traditional methods face several challenges. They rely heavily on manual feature engineering, struggle with complex scenes, and lack real-time performance. Additionally, the vast diversity among objects presents a significant hurdle.
What are the main approaches to machine learning?
In machine learning, we primarily use supervised and unsupervised learning. Supervised learning teaches models by showing them labeled examples. Unsupervised learning enables models to uncover hidden patterns without direct guidance.
What are convolutional neural networks (CNNs) and how are they used in object recognition?
CNNs stand as the premier architecture for deep learning in object recognition. They can automatically identify complex features within images. This is due to their unique structure, which includes convolutional, pooling, and fully connected layers. These elements are designed to understand both spatial and temporal relationships in visual data.
How does transfer learning benefit object recognition?
Transfer learning accelerates the adaptation of models to new tasks using existing knowledge. By reusing pre-trained models, it enhances accuracy and efficiency, requiring less new data for a task. This is especially beneficial in scenarios with limited resources.
What are the advantages of using machine learning in object recognition?
Machine learning brings several benefits to object recognition systems. It automates the extraction of data features, thereby easing the burden of manual engineering. Models like CNNs shine in this setup, excelling at complex categorizations and situations, ultimately delivering superior real-world performance.
What are some real-world applications of object recognition?
There are numerous practical uses for object recognition. This technology powers autonomous vehicles, aids in medical diagnostics, enhances surveillance and security, optimizes industrial processes, refines retail strategies, and drives augmented reality.
What are the challenges and limitations of machine learning in object recognition?
The field faces various hurdles, encompassing the necessity for abundant, well-labeled training data and significant computational resources. Deep learning models' opacity also poses issues, along with challenges in handling occlusion and varied appearances of objects.
What are the future trends and developments in machine learning for object recognition?
The future holds prospects for object recognition's integration with NLP and reasoning, alongside a focus on edge computing for agility. Efforts also concentrate on producing deep learning networks that are efficient and compact. Furthermore, there's a push towards unsupervised and self-supervised learning to decrease dependency on labeled data.