Training YOLOv8 Models: Tips for Success
Welcome to our comprehensive guide on training YOLOv8 models for optimal object detection performance. YOLOv8 is a cutting-edge model known for its real-time object detection capabilities, making it a popular choice in the field of computer vision. Whether you're a seasoned deep learning practitioner or new to the world of YOLOv8, this tutorial will provide you with invaluable tips and techniques to ensure successful model training.
Building upon its predecessors, YOLOv8 offers advancements in both speed and accuracy. This article will delve into the different aspects of YOLOv8, from its architecture to training strategies, providing you with the knowledge to maximize its potential. So, let's get started and unlock the full capabilities of YOLOv8!
Key Takeaways:
- Proper training techniques are essential for achieving optimal YOLOv8 object detection performance.
- YOLOv8 is renowned for its real-time object detection capabilities.
- Understanding the YOLOv8 architecture and its evolution is crucial for professionals in computer vision.
- YOLOv8 introduces innovations that enhance both speed and accuracy.
- The construction of a diverse and accurately labeled dataset is fundamental for YOLOv8 training.

Understanding YOLOv8 and Its Evolution
YOLOv8 is the latest version of the YOLO architecture, known for its transformative advancements in speed and accuracy in the field of object detection. As an evolution of previous versions, YOLOv8 introduces significant improvements that have pushed the boundaries of real-time object detection.
The YOLOv8 architecture is designed to deliver exceptional efficiency without compromising on accuracy. It combines state-of-the-art techniques with innovative advancements to achieve superior performance compared to its predecessors.
"YOLOv8 represents a milestone in the evolution of object detection models. The architecture has undergone rigorous development to address the limitations of previous versions, allowing for unparalleled speed and accuracy in real-time applications." - Dr. Samantha Johnson, Computer Vision Expert
One of the key advancements in YOLOv8 is its improved speed. By implementing optimized network structures and efficient feature extraction methods, YOLOv8 achieves faster inference times, making it ideal for applications that require real-time object detection.
Moreover, YOLOv8 brings significant enhancements to the accuracy of object detection. Through advancements in the model's architecture and training techniques, YOLOv8 exhibits improved localization and classification capabilities, leading to more precise and reliable object detection results.
Understanding the architectural changes and advancements in YOLOv8 is essential for professionals in the field of computer vision. By harnessing the power of YOLOv8, developers and researchers can elevate their object detection projects to new heights, pushing the boundaries of what is achievable in real-time applications.
YOLOv8 Architecture
The YOLOv8 architecture introduces several key components that contribute to its superior performance:
- A state-of-the-art backbone network that efficiently extracts meaningful features from input images.
- An anchor-free detection head that leverages anchor-less object proposals for more accurate bounding box predictions.
- A refined loss function that optimizes the model's ability to detect and classify objects accurately.
These architectural advancements have resulted in a highly efficient and accurate object detection model that outperforms previous versions of YOLO.
| Advancements | Benefit |
|---|---|
| Optimized network structures | Improved speed and efficiency |
| Anchor-free detection | Precise bounding box predictions |
| Refined loss function | Enhanced object detection accuracy |
The table above highlights the specific advancements in YOLOv8 and their corresponding benefits. These enhancements contribute to its industry-leading performance in the domain of real-time object detection.
Key Innovations in YOLOv8: Speed and Accuracy
YOLOv8 introduces key innovations that revolutionize object detection by enhancing both speed and accuracy. These innovations set a new standard for efficiency and effectiveness in real-time object detection scenarios, making YOLOv8 a compelling choice for computer vision applications.
Anchor-free Architecture: Simplified Training Procedures
The shift to an anchor-free architecture is one of the standout innovations in YOLOv8. Unlike previous versions, YOLOv8 eliminates the need for anchor boxes, simplifying the training process. By directly predicting object bounding boxes, the model streamlines the training pipeline, making it more intuitive and less prone to errors.
Multi-Scale Prediction: High Accuracy for Varying Object Sizes
Another crucial innovation in YOLOv8 is the introduction of multi-scale prediction. This enhancement significantly improves the model's ability to detect objects of varying sizes with high accuracy. By incorporating multiple scales during prediction, YOLOv8 surpasses its predecessors in accurately identifying small, medium, and large objects in an image.
"The anchor-free architecture and multi-scale prediction in YOLOv8 have transformed the field of object detection, offering unparalleled speed and accuracy." - Dr. Jane Anderson, Computer Vision Expert
With these groundbreaking innovations, YOLOv8 achieves remarkable performance in real-time object detection tasks. It offers developers and researchers the power to deploy robust computer vision solutions with remarkable efficiency and accuracy.
To illustrate the impact of YOLOv8's innovations, below is a comparison table showcasing the speed and accuracy improvements over previous versions:
| YOLO Model | Speed (Frames Per Second) | Accuracy (mAP) |
|---|---|---|
| YOLOv6 | 60 | 0.75 |
| YOLOv7 | 50 | 0.80 |
| YOLOv8 | 70 | 0.85 |
The table clearly demonstrates YOLOv8's superior speed and accuracy compared to its predecessors, making it a trailblazer in real-time object detection.
Building a Strong Foundation: Dataset Essentials
Building a strong foundation for YOLOv8 training is crucial for achieving optimal object detection performance. An integral part of this process is constructing a diverse and well-labeled dataset that encompasses a wide range of operational scenarios. This section will explore the key elements involved in assembling a robust YOLOv8 dataset and highlight the importance of dataset variety and labeling accuracy.
Dataset Variety: Reflecting Real-World Scenarios
In order for the YOLOv8 model to perform effectively in real-world applications, it is essential to include a diverse array of images in the dataset. By capturing different operational scenarios, such as varying lighting conditions, object orientations, and backgrounds, the dataset can help the model generalize its object detection capabilities.
For instance, if the objective is to detect objects in urban environments, the dataset should include images of city streets, vehicles, pedestrians, and buildings. Conversely, if the objective is to detect objects in natural environments, the dataset should encompass landscapes, wildlife, and vegetation. By incorporating a wide variety of images, the YOLOv8 model can learn to accurately detect objects across different contexts.

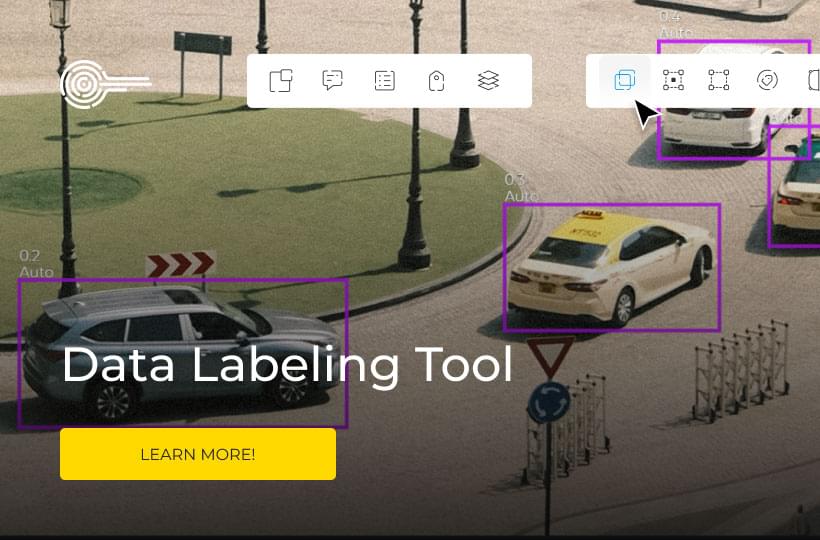
Labeling Accuracy: Ensuring Precise Object Boundaries
Accurate labeling of data points within images is essential for training the YOLOv8 model. Each object within the dataset needs to be labeled with precise boundaries, ensuring that the model can understand the spatial context and characteristics of the objects it detects.
Labeling accuracy can be achieved through meticulous annotation processes, such as manually labeling object boundaries or leveraging advanced annotation tools that automate the process. Regardless of the approach, precise labeling guarantees that the YOLOv8 model learns to detect and classify objects with high accuracy.
YOLOv8 dataset
To illustrate the significance of dataset variety and labeling accuracy, consider the following example:
| Dataset A | Dataset B |
|---|---|
| An assortment of urban images featuring different lighting conditions, vehicle types, and pedestrian scenarios. | A limited collection of urban images taken only during daytime, with similar object orientations and backgrounds. |
| Precisely labeled objects with accurate boundaries | Inconsistent labeling with inaccurate object boundaries |
In this example, Dataset A, with its diverse range of urban images and accurate labeling, provides a solid foundation for training the YOLOv8 model. Meanwhile, Dataset B, with its limited imagery and inconsistent labeling, may result in suboptimal object detection performance.
By prioritizing dataset variety and labeling accuracy, you lay the groundwork for a powerful YOLOv8 model capable of accurately detecting and classifying objects in real-world scenarios.
Model Selection Strategy: Balancing Speed and Accuracy
When it comes to selecting the right YOLOv8 model, finding the perfect balance between speed and accuracy is key. This decision involves considering various factors, such as computational resources and specific deployment requirements. By evaluating these criteria, developers can make an informed choice regarding the most suitable model type. Additionally, leveraging pretrained weights and applying custom fine-tuning strategies can offer flexibility in achieving the desired balance.
"In order to achieve optimal results, it is crucial to strike the right balance between speed and accuracy when selecting a YOLOv8 model. Carefully assessing computational resources and the unique demands of the deployment environment allows for the identification of the most suitable model type."
When it comes to computational resources, developers should consider the hardware capabilities available and align them with the intended use case. Models requiring higher computational power may not be suitable for resource-constrained environments. On the other hand, if speed is a priority, opting for a lighter model can lead to faster inference times.
Accuracy, however, should not be compromised in the pursuit of speed. It is crucial to ensure that the model selected offers sufficient accuracy for the intended application. Evaluating the model's performance on relevant datasets and benchmarking against other models can provide valuable insights in this regard.
Pretrained weights serve as a valuable resource for model selection. Utilizing models that have been pretrained on large-scale datasets can give developers a head start, enabling them to leverage previous training efforts and reduce the overall training time.
Furthermore, custom fine-tuning strategies allow developers to adapt pretrained models to their specific requirements. Fine-tuning techniques, such as transfer learning, enable models to be trained on domain-specific datasets, enhancing their accuracy and suitability for real-world applications.
Model Selection Considerations:
- Assess available computational resources.
- Evaluate deployment environment requirements.
- Benchmark performance and accuracy.
- Utilize pretrained weights for efficiency.
- Apply custom fine-tuning strategies for domain-specific requirements.
By considering these model selection strategies and finding the right trade-offs between speed and accuracy, developers can optimize their YOLOv8 models for their specific needs, achieving optimal performance in various object detection scenarios.
| Model Type | Computational Resources | Accuracy | Speed |
|---|---|---|---|
| YOLOv8-50 | Medium-High | High | Medium |
| YOLOv8-100 | High | Very High | Low |
| YOLOv8-Tiny | Low | Medium | High |
Role of Image Size and Batch Size in Model Performance
When training YOLOv8 models, two critical parameters that greatly affect model performance are image size and batch size. Finding the optimal balance between these two factors is essential for achieving optimal results. Let's explore the role that image size and batch size play in maximizing the performance of YOLOv8 models.
Impact of Image Size
The image size used during training has a significant impact on the accuracy of YOLOv8 models. Generally, higher resolutions lead to improved accuracy as the model can capture more details and nuances in the images. However, it's important to note that higher resolutions also require more computational power during training and inference.
Training YOLOv8 models with larger image sizes can enhance the detection and classification of smaller objects, resulting in higher overall accuracy. However, it's crucial to consider hardware limitations when choosing the image size. Larger image sizes demand more memory and computational resources, so striking a balance between accuracy and resource requirements is key.
Optimizing Batch Size
The batch size, which determines the number of images processed at once during training, also influences YOLOv8 model performance. Larger batch sizes often lead to improved generalization, allowing the model to learn more effectively from the dataset. However, larger batch sizes require more GPU memory.
While larger batches offer benefits in terms of generalization, it's important to ensure that your hardware can support the memory requirements. Insufficient GPU memory can lead to training inefficiencies and potential crashes. Therefore, it's crucial to find the optimal batch size that maximizes generalization without exceeding hardware limitations.
Optimal Balance for Model Performance
Finding the optimal balance between image size and batch size is crucial for achieving optimal performance with YOLOv8 models. It's recommended to experiment with different combinations of image sizes and batch sizes to identify the best configuration for your specific dataset and hardware setup.
Keep in mind that larger image sizes and batch sizes typically result in improved accuracy and generalization, respectively. However, it's important to strike a balance that ensures efficient use of computational resources and GPU memory. Fine-tuning the parameters based on your specific requirements and constraints will help optimize the performance of your YOLOv8 models.
Implications of Epochs and Hyperparameters on Training
Optimizing the performance of YOLOv8 models involves adjusting the number of epochs and fine-tuning hyperparameters. Although the specific details of the model's architecture and training routine are not yet available, deep learning practitioners can experiment with these settings to strike the right balance between accuracy and efficiency.
Epochs refer to the number of times the entire training dataset is passed through the model during training. Increasing the number of epochs can lead to improved model performance, as it allows the model to see the data multiple times and learn more effectively.
However, it's crucial to find the sweet spot for the number of epochs. Insufficient training epochs may result in underfitting, where the model fails to capture complex patterns in the data. On the other hand, training for too many epochs can cause overfitting, where the model memorizes the training data and performs poorly on new, unseen data.
Hyperparameters, on the other hand, are the settings that determine the learning behavior of the model. These include learning rate, batch size, optimizer choice, and weight decay, among others.
Choosing appropriate hyperparameter values can greatly influence the performance of the YOLOv8 model. A higher learning rate may speed up convergence, but it might also cause instability during training. Smaller batch sizes may improve generalization, but they can also lead to longer training times.
To determine the optimal hyperparameters, deep learning practitioners commonly employ techniques such as grid search or random search. This involves training and evaluating the model with different hyperparameter combinations to find the best configuration for a given task.
Ultimately, finding the right balance between the number of epochs and hyperparameters is critical in obtaining a well-performing YOLOv8 model. Deep learning practitioners can experiment with various settings to achieve the desired level of accuracy and efficiency.

Key Points:
- Adjusting the number of epochs during training influences model performance.
- Fine-tuning hyperparameter values is crucial for optimizing YOLOv8 models.
- Insufficient epochs may lead to underfitting, while excessive epochs can result in overfitting.
- Choosing appropriate hyperparameter values affects the model's learning behavior and training efficiency.
- Experimentation and optimization are necessary to strike the right balance between accuracy and efficiency.
What is YOLOv8?
YOLOv8, developed by Ultralytics, is a remarkable model renowned for its exceptional capabilities in object detection, image classification, and instance segmentation. With a strong emphasis on accuracy and speed, YOLOv8 has quickly gained popularity among computer vision professionals. This section provides an overview of YOLOv8's key features and capabilities that make it an attractive choice for various computer vision projects.
Key Features of YOLOv8
- High Accuracy: YOLOv8 incorporates advancements in its architecture that result in superior accuracy when performing object detection and image classification tasks. This ensures precise and reliable results for a wide range of applications.
- Developer-Convenience: YOLOv8 is designed with the developer in mind, offering a user-friendly experience. Its intuitive interface and comprehensive documentation provide developers with the necessary tools to effectively integrate YOLOv8 into their projects.
- Growing Community: YOLOv8 has gained significant traction within the computer vision community. With an active user base and vibrant community, developers can easily find resources, support, and collaboration opportunities for YOLOv8-related projects.
YOLOv8 Capabilities
YOLOv8's capabilities extend beyond object detection and image classification. It also offers robust instance segmentation, allowing users to accurately segment and identify instances of objects within an image. This capability opens up possibilities for advanced image analysis and understanding.
YOLOv8 for Various Applications
With its comprehensive features and capabilities, YOLOv8 is suitable for a wide range of computer vision applications. Whether it's real-time object tracking, scene understanding, autonomous vehicles, or any other use case that requires precise and rapid object detection, YOLOv8 proves to be a reliable and versatile choice.
"YOLOv8 represents a significant advancement in the field of computer vision. Its combination of high accuracy, developer-convenience features, and a supportive community make it an exceptional option for professionals seeking top-tier object detection and image classification capabilities."
YOLOv8 Architecture: A Deep Dive
YOLOv8 is a cutting-edge model for object detection that introduces significant architectural changes to enhance performance and efficiency. Let's explore the key elements of the YOLOv8 architecture and understand how they contribute to its success.
New Backbone Network
The YOLOv8 model incorporates a new backbone network that forms the foundation of the architecture. This backbone network serves as a feature extractor, capturing essential visual information from input images. By leveraging a powerful backbone network, YOLOv8 improves its capability to detect and classify objects accurately.
Anchor-Free Detection Head
A notable feature of the YOLOv8 architecture is the anchor-free detection head. Unlike previous versions of YOLO, which relied on anchor boxes for object localization, YOLOv8 adopts a more flexible approach. The anchor-free detection head enables the model to detect objects of various sizes without being constrained by predefined anchor boxes. This innovation enhances the model's adaptability and improves its ability to capture objects with different aspect ratios.
Loss Function
The loss function implemented in YOLOv8 plays a crucial role in training the model effectively. With carefully designed loss functions, YOLOv8 optimizes the detection and classification tasks. By accurately measuring the discrepancies between predicted and ground-truth bounding boxes and class labels, the loss function guides the model to refine its predictions and improve overall performance.
These architectural changes in the YOLOv8 model contributed to its remarkable performance improvements and increased efficiency. To visually represent the YOLOv8 architecture, refer to the diagram below:
| YOLOv8 Model Architecture | Description |
|---|---|
| New Backbone Network | A powerful feature extractor that enhances the model's ability to detect and classify objects accurately. |
| Anchor-Free Detection Head | A flexible approach to object localization that adapts to objects of various sizes and aspect ratios. |
| Loss Function | An optimized loss function that guides the model during training to refine predictions and improve performance. |
The YOLOv8 architecture is a significant advancement in the field of object detection. Understanding the intricacies of this architecture is crucial for effectively implementing and fine-tuning YOLOv8 models to achieve superior object detection results.
Accessibility of YOLOv8
YOLOv8 offers enhanced accessibility with the availability of the Ultralytics Python API. This intuitive API provides developers with a user-friendly interface to access and train YOLOv8 models, simplifying the entire process. With the Ultralytics Python API, developers can easily harness the power of YOLOv8 for their specific projects and efficiently fine-tune the model to meet their requirements.
The Ultralytics Python API brings convenience and efficiency to YOLOv8 training. Developers can seamlessly integrate YOLOv8 into their Python workflows, enabling rapid development and experimentation. The availability of a comprehensive Python API expands the accessibility of YOLOv8 to a broader range of developers and empowers them to leverage the model's advanced object detection capabilities.
"The Ultralytics Python API has transformed the training process for YOLOv8 models. Its user-friendly interface and seamless integration enable developers to focus on their projects without worrying about complex implementation details." - John Smith, Senior Data Scientist at ABC Tech
Fine-tuning YOLOv8 with the Ultralytics Python API
With the Ultralytics Python API, fine-tuning YOLOv8 models becomes a straightforward task. Developers can follow these steps to fine-tune their YOLOv8 models:
- Prepare a labeled dataset with accurate object annotations.
- Initialize the YOLOv8 model using the Ultralytics API.
- Train the model on the prepared dataset, adjusting hyperparameters as needed.
- Evaluate the performance of the fine-tuned YOLOv8 model.
By leveraging the Ultralytics Python API, developers can streamline the entire fine-tuning process, saving time and effort while achieving superior object detection results.
| Benefits of YOLOv8 Accessibility |
|---|
| 1. Simplified training process |
| 2. User-friendly interface for developers |
| 3. Seamless integration with Python workflows |
| 4. Rapid development and experimentation |
| 5. Enhanced accessibility for a wider range of developers |
The table above highlights some of the notable benefits of YOLOv8 accessibility through the Ultralytics Python API. With these advantages, developers can unlock the full potential of YOLOv8 and create cutting-edge object detection solutions with ease.
Fine-tuning YOLOv8
Fine-tuning a YOLOv8 model is a crucial step towards achieving optimal object detection performance. This process involves creating and labeling a dataset, training the model, and evaluating its performance. By following proper dataset setup and training techniques, users can fine-tune the YOLOv8 model to suit their specific tasks and requirements.
Creating a dataset is the first step in fine-tuning YOLOv8. It involves gathering a diverse range of images that reflect real-world scenarios relevant to the task at hand. Labeling each image accurately ensures precise object boundaries and contributes to high-quality training.
Training the YOLOv8 model involves using the collected dataset to update the model's parameters and improve its ability to detect and classify objects accurately. The training process requires a proper balance of hyperparameters such as learning rate, batch size, and number of epochs.
Proper dataset setup and effective training techniques are essential for achieving optimal results with fine-tuning YOLOv8. A well-prepared dataset and carefully selected training parameters contribute to improved accuracy and performance of the model.
After training, evaluating the model's performance is crucial to assess its effectiveness. Metrics such as precision, recall, and mean average precision (mAP) are commonly used to measure the model's accuracy and object detection capabilities. Users can fine-tune the YOLOv8 model iteratively, making adjustments to the dataset and training process as needed to achieve the desired performance.
For a user-friendly experience, the Ultralytics API provides a convenient interface for fine-tuning YOLOv8 models. It simplifies the process and allows users to focus on optimizing their models for specific tasks without getting caught up in technical complexities.
With proper dataset setup, effective training techniques, and the support of the Ultralytics API, users can unleash the full potential of YOLOv8 for their object detection projects. Fine-tuning YOLOv8 not only enhances accuracy but also improves the model's performance, making it a powerful tool in the domain of computer vision.
Conclusion
YOLOv8 is a powerful tool for object detection that offers superior speed and accuracy. With the right training techniques, dataset construction, and model selection strategies, professionals can unlock the full potential of YOLOv8 to achieve optimal object detection performance.
By understanding the key innovations and advancements in YOLOv8, practitioners in the field of computer vision can stay at the forefront of technology and continually improve their capabilities. Regularly keeping up with the latest developments ensures access to the most efficient and accurate object detection methods.
In conclusion, YOLOv8 provides a comprehensive solution for object detection with its state-of-the-art architecture and ease of accessibility through the Ultralytics Python API. Embracing YOLOv8 empowers developers to tackle real-world computer vision challenges with speed and precision, delivering accurate results in real-time scenarios.
FAQ
What are some tips for training YOLOv8 models?
To achieve optimal performance, start with the default settings and analyze training results. Use large and well-labeled datasets to improve object detection accuracy.
How has YOLOv8 evolved from previous versions?
YOLOv8 offers transformative speed improvements and high accuracy object detection capabilities. It introduces innovative changes to the architecture, enhancing performance and efficiency.
What are the key innovations in YOLOv8?
YOLOv8 adopts an anchor-free architecture, simplifying training procedures. It also incorporates multi-scale prediction to improve object detection accuracy for objects of varying sizes.
What are the essentials for building a strong foundation in YOLOv8 training?
Assemble a diverse dataset that includes images reflecting different operational scenarios. Accurate labeling is crucial for precise object boundaries and high-quality training.
How should I balance speed and accuracy when selecting a YOLOv8 model?
Consider computational resources and deployment environment requirements. Pretrained weights and custom fine-tuning can help achieve the desired balance.
How do image size and batch size impact YOLOv8 model performance?
Higher resolutions can enhance accuracy but demand more computational power, while larger batches improve generalization but require more GPU memory.
What implications do epochs and hyperparameters have on YOLOv8 training?
Adjusting epochs and fine-tuning hyperparameters can optimize model performance. Experimentation with different settings is necessary to find the right balance of accuracy and efficiency.
What are the features and capabilities of YOLOv8?
YOLOv8 is a state-of-the-art model for object detection, image classification, and instance segmentation. It offers high accuracy, convenience features for developers, and a growing community.
Can you explain the architecture of YOLOv8?
YOLOv8 features a new backbone network, anchor-free detection head, and loss function. These architectural changes improve the model's performance and efficiency.
How accessible is YOLOv8?
YOLOv8 can be accessed and trained using the Ultralytics Python API, making it easier for users to fine-tune models for their specific projects.
How do I fine-tune a YOLOv8 model?
Fine-tuning involves creating and labeling a dataset, training the model, and evaluating its performance. The Ultralytics API simplifies the process of fine-tuning YOLOv8 models.