Robot Perception Datasets: Vision, Sensors, and AI
Robotic perception is a key area of modern robotics and AI, enabling machines to “see”, “feel”, and interpret the world around them. The basis of such capabilities is data coming from various sensors: cameras, lidars, radars, inertial measurement units, and other devices. However, sensor data alone is not sufficient without high-quality datasets for training and testing computer vision and machine learning algorithms.
The topic of Robot Perception Datasets combines several areas — computer vision, sensor technologies, and artificial intelligence methods. Thanks to the development of large, diverse datasets, progress in the field of autonomous systems has accelerated significantly.

Types of Robot Perception Datasets
Well-Known Robot Perception Datasets
How data is collected and annotated
Data collection for robotic perception is a complex, multi-step process that usually begins with the use of specialized platforms or vehicles equipped with sensor suites. These can be autonomous cars, mobile robots, or stationary systems with cameras, lidars, GPS, and inertial measurement units. During system movement or operation, the sensors synchronously record environmental information, forming large arrays of raw data.
After data collection, an important stage is their annotation. It consists of adding information about objects to images or 3D data, such as their classes, bounding boxes, segmentation, or motion trajectories. In many cases, this process is performed manually by specially trained annotators, which makes it very time-consuming and expensive.
To reduce time and resource consumption, semi-automatic markup methods are increasingly used, in which machine learning algorithms first suggest preliminary labels, and humans only check and correct them. Active learning methods are also used, allowing the selection of the most informative examples for markup.
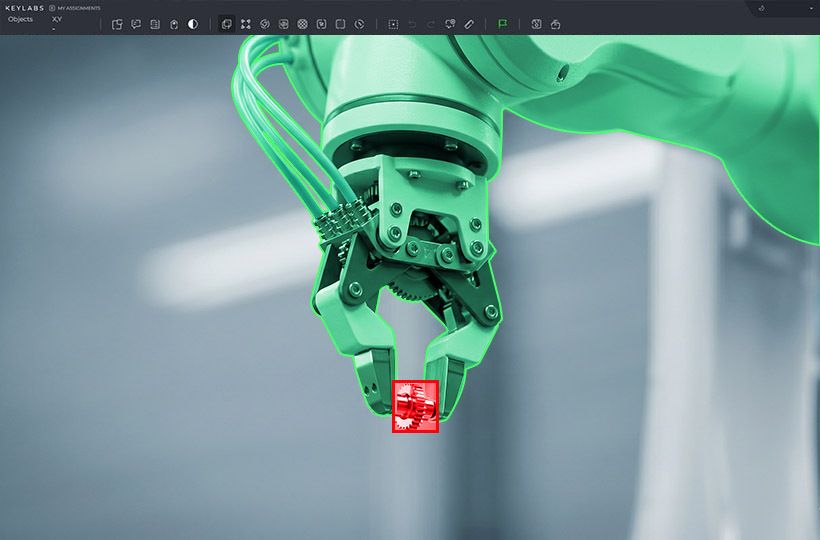
Problems and challenges of robotic datasets
Despite the rapid growth of datasets for robotic perception, several significant problems limit the effectiveness of model training and its application in real-world conditions.
One of the main problems is the lack of real-world data. Collecting information from physical sensors is expensive, time-consuming, and often limited by operating conditions. Because of this, many models are trained on relatively small or highly specialized datasets, which reduces their ability to generalize.
Another important challenge is the domain gap - the difference between synthetic (simulated) and real-world data. Although simulations allow you to quickly create large amounts of labeled data, they do not always accurately reproduce the complexity of the real world: lighting, sensor noise, unpredictable objects, and dynamic scenes. This leads to a decrease in model performance when moving from simulation to real-world conditions.
Another significant problem is the imbalance in the data classes. In the real world, some objects occur much more frequently than others, which can bias model training and impair the recognition of rare yet important objects.
Of particular note are scalability and labeling quality. The larger the dataset, the harder it is to maintain high annotation accuracy, especially when a significant portion of the data is labeled manually or semi-automatically. Labeling errors can significantly affect the quality of model training.
FAQ
What is computer vision in robotics?
Computer vision in robotics enables machines to interpret and analyze visual data from cameras and other sensors. It is a core component of computer vision robotics, supporting tasks such as object detection, scene understanding, and navigation.
Why are datasets important for perception AI models?
Datasets provide structured and labeled data needed to train and evaluate perception AI models. They ensure that models learn meaningful patterns from real-world sensor inputs and can generalize to new environments.
What are LiDAR datasets used for?
LiDAR datasets consist of 3D point clouds that represent the geometry of real-world environments. They are commonly used in robotics for mapping, localization, and obstacle detection.
What is the role of sensor data in perception AI models?
Sensor data serves as input to perception AI models, enabling robots to understand their surroundings. Combining data from cameras, LiDAR, and other sensors improves perception accuracy.
What is the difference between image and LiDAR datasets?
Image datasets contain 2D visual information, while LiDAR datasets provide 3D spatial representations of environments. Both are often combined to improve robotic perception.
Why is sensor fusion important in robotics?
Sensor fusion combines multiple data sources to produce a more complete and reliable representation of the environment. In computer vision robotics, this improves robustness under challenging conditions.
What challenges are associated with perception AI models?
Perception AI models face challenges such as noisy sensor data, environmental variability, and limited generalization. These issues can reduce performance in real-world applications.
What is the process of collecting LiDAR datasets?
LiDAR datasets are collected using platforms equipped with laser scanners that capture 3D spatial information. The data is recorded alongside other sensor streams, such as GPS and cameras.
What is the role of computer vision robotics in autonomous systems?
Computer vision and robotics enable autonomous systems to perceive and interpret their environment. This capability is essential for navigation, detection, and decision-making tasks.
What is the impact of datasets on robotic performance?
High-quality datasets improve the performance of perception AI models by providing diverse and representative training examples. This leads to more reliable and accurate robotic behavior in real-world scenarios.